 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooking Backward: Retrospective Backward Synthesis for Goal-Conditioned GFlowNets
Jun 03, 2024Generative Flow Networks (GFlowNets) are amortized sampling methods for learning a stochastic policy to sequentially generate compositional objects with probabilities proportional to their rewards. GFlowNets exhibit a remarkable ability to generate diverse sets of high-reward objects, in contrast to standard return maximization reinforcement learning approaches, which often converge to a single optimal solution. Recent works have arisen for learning goal-conditioned GFlowNets to acquire various useful properties, aiming to train a single GFlowNet capable of achieving different goals as the task specifies. However, training a goal-conditioned GFlowNet poses critical challenges due to extremely sparse rewards, which is further exacerbated in large state spaces. In this work, we propose a novel method named Retrospective Backward Synthesis (RBS) to address these challenges. Specifically, RBS synthesizes a new backward trajectory based on the backward policy in GFlowNets to enrich training trajectories with enhanced quality and diversity, thereby efficiently solving the sparse reward problem. Extensive empirical results show that our method improves sample efficiency by a large margin and outperforms strong baselines on various standard evaluation benchmarks.
Rethinking Transformers in Solving POMDPs
May 30, 2024Sequential decision-making algorithms such as reinforcement learning (RL) in real-world scenarios inevitably face environments with partial observability. This paper scrutinizes the effectiveness of a popular architecture, namely Transformers, in Partially Observable Markov Decision Processes (POMDPs) and reveals its theoretical limitations. We establish that regular languages, which Transformers struggle to model, are reducible to POMDPs. This poses a significant challenge for Transformers in learning POMDP-specific inductive biases, due to their lack of inherent recurrence found in other models like RNNs. This paper casts doubt on the prevalent belief in Transformers as sequence models for RL and proposes to introduce a point-wise recurrent structure. The Deep Linear Recurrent Unit (LRU) emerges as a well-suited alternative for Partially Observable RL, with empirical results highlighting the sub-optimal performance of the Transformer and considerable strength of LRU.
OMPO: A Unified Framework for RL under Policy and Dynamics Shifts
May 29, 2024Training reinforcement learning policies using environment interaction data collected from varying policies or dynamics presents a fundamental challenge. Existing works often overlook the distribution discrepancies induced by policy or dynamics shifts, or rely on specialized algorithms with task priors, thus often resulting in suboptimal policy performances and high learning variances. In this paper, we identify a unified strategy for online RL policy learning under diverse settings of policy and dynamics shifts: transition occupancy matching. In light of this, we introduce a surrogate policy learning objective by considering the transition occupancy discrepancies and then cast it into a tractable min-max optimization problem through dual reformulation. Our method, dubbed Occupancy-Matching Policy Optimization (OMPO), features a specialized actor-critic structure equipped with a distribution discriminator and a small-size local buffer. We conduct extensive experiments based on the OpenAI Gym, Meta-World, and Panda Robots environments, encompassing policy shifts under stationary and nonstationary dynamics, as well as domain adaption. The results demonstrate that OMPO outperforms the specialized baselines from different categories in all settings. We also find that OMPO exhibits particularly strong performance when combined with domain randomization, highlighting its potential in RL-based robotics applications
Offline-Boosted Actor-Critic: Adaptively Blending Optimal Historical Behaviors in Deep Off-Policy RL
May 28, 2024Off-policy reinforcement learning (RL) has achieved notable success in tackling many complex real-world tasks, by leveraging previously collected data for policy learning. However, most existing off-policy RL algorithms fail to maximally exploit the information in the replay buffer, limiting sample efficiency and policy performance. In this work, we discover that concurrently training an offline RL policy based on the shared online replay buffer can sometimes outperform the original online learning policy, though the occurrence of such performance gains remains uncertain. This motivates a new possibility of harnessing the emergent outperforming offline optimal policy to improve online policy learning. Based on this insight, we present Offline-Boosted Actor-Critic (OBAC), a model-free online RL framework that elegantly identifies the outperforming offline policy through value comparison, and uses it as an adaptive constraint to guarantee stronger policy learning performance. Our experiments demonstrate that OBAC outperforms other popular model-free RL baselines and rivals advanced model-based RL methods in terms of sample efficiency and asymptotic performance across 53 tasks spanning 6 task suites.
Learning Visual Quadrupedal Loco-Manipulation from Demonstrations
Mar 29, 2024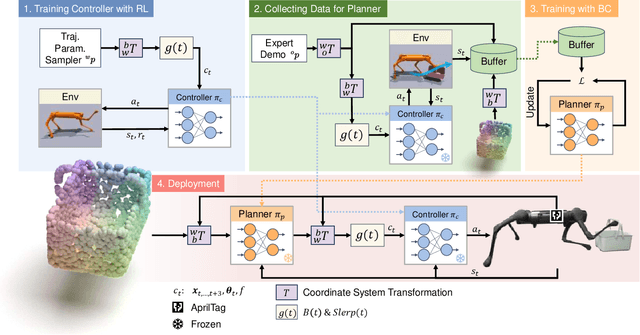

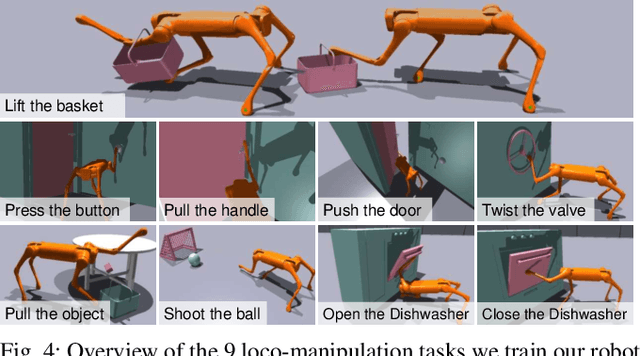
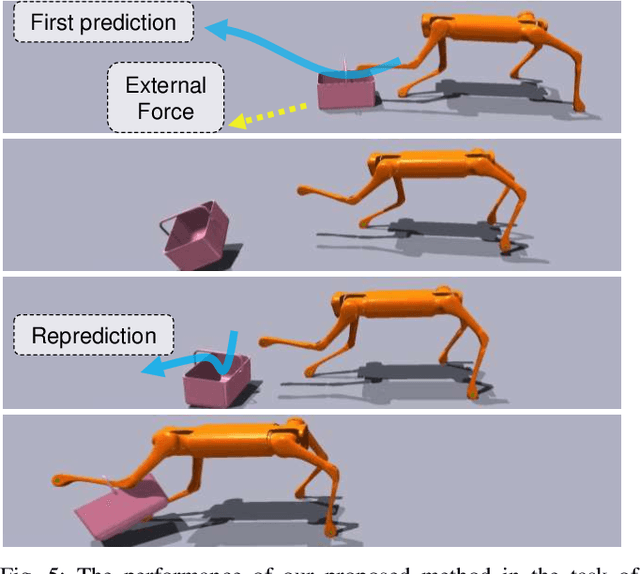
Quadruped robots are progressively being integrated into human environments. Despite the growing locomotion capabilities of quadrupedal robots, their interaction with objects in realistic scenes is still limited. While additional robotic arms on quadrupedal robots enable manipulating objects, they are sometimes redundant given that a quadruped robot is essentially a mobile unit equipped with four limbs, each possessing 3 degrees of freedom (DoFs). Hence, we aim to empower a quadruped robot to execute real-world manipulation tasks using only its legs. We decompose the loco-manipulation process into a low-level reinforcement learning (RL)-based controller and a high-level Behavior Cloning (BC)-based planner. By parameterizing the manipulation trajectory, we synchronize the efforts of the upper and lower layers, thereby leveraging the advantages of both RL and BC. Our approach is validated through simulations and real-world experiments, demonstrating the robot's ability to perform tasks that demand mobility and high precision, such as lifting a basket from the ground while moving, closing a dishwasher, pressing a button, and pushing a door. Project website: https://zhengmaohe.github.io/leg-manip
RiEMann: Near Real-Time SE(3)-Equivariant Robot Manipulation without Point Cloud Segmentation
Mar 28, 2024



We present RiEMann, an end-to-end near Real-time SE(3)-Equivariant Robot Manipulation imitation learning framework from scene point cloud input. Compared to previous methods that rely on descriptor field matching, RiEMann directly predicts the target poses of objects for manipulation without any object segmentation. RiEMann learns a manipulation task from scratch with 5 to 10 demonstrations, generalizes to unseen SE(3) transformations and instances of target objects, resists visual interference of distracting objects, and follows the near real-time pose change of the target object. The scalable action space of RiEMann facilitates the addition of custom equivariant actions such as the direction of turning the faucet, which makes articulated object manipulation possible for RiEMann. In simulation and real-world 6-DOF robot manipulation experiments, we test RiEMann on 5 categories of manipulation tasks with a total of 25 variants and show that RiEMann outperforms baselines in both task success rates and SE(3) geodesic distance errors on predicted poses (reduced by 68.6%), and achieves a 5.4 frames per second (FPS) network inference speed. Code and video results are available at https://riemann-web.github.io/.
RoboDuet: A Framework Affording Mobile-Manipulation and Cross-Embodiment
Mar 27, 2024



Combining the mobility of legged robots with the manipulation skills of arms has the potential to significantly expand the operational range and enhance the capabilities of robotic systems in performing various mobile manipulation tasks. Existing approaches are confined to imprecise six degrees of freedom (DoF) manipulation and possess a limited arm workspace. In this paper, we propose a novel framework, RoboDuet, which employs two collaborative policies to realize locomotion and manipulation simultaneously, achieving whole-body control through interactions between each other. Surprisingly, going beyond the large-range pose tracking, we find that the two-policy framework may enable cross-embodiment deployment such as using different quadrupedal robots or other arms. Our experiments demonstrate that the policies trained through RoboDuet can accomplish stable gaits, agile 6D end-effector pose tracking, and zero-shot exchange of legged robots, and can be deployed in the real world to perform various mobile manipulation tasks. Our project page with demo videos is at https://locomanip-duet.github.io .
3D Diffusion Policy
Mar 06, 2024



Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 55.3% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning. Videos, code, and data are available on https://3d-diffusion-policy.github.io .
ACE : Off-Policy Actor-Critic with Causality-Aware Entropy Regularization
Feb 22, 2024The varying significance of distinct primitive behaviors during the policy learning process has been overlooked by prior model-free RL algorithms. Leveraging this insight, we explore the causal relationship between different action dimensions and rewards to evaluate the significance of various primitive behaviors during training. We introduce a causality-aware entropy term that effectively identifies and prioritizes actions with high potential impacts for efficient exploration. Furthermore, to prevent excessive focus on specific primitive behaviors, we analyze the gradient dormancy phenomenon and introduce a dormancy-guided reset mechanism to further enhance the efficacy of our method. Our proposed algorithm, ACE: Off-policy Actor-critic with Causality-aware Entropy regularization, demonstrates a substantial performance advantage across 29 diverse continuous control tasks spanning 7 domains compared to model-free RL baselines, which underscores the effectiveness, versatility, and efficient sample efficiency of our approach. Benchmark results and videos are available at https://ace-rl.github.io/.
RoboScript: Code Generation for Free-Form Manipulation Tasks across Real and Simulation
Feb 22, 2024Rapid progress in high-level task planning and code generation for open-world robot manipulation has been witnessed in Embodied AI. However, previous studies put much effort into general common sense reasoning and task planning capabilities of large-scale language or multi-modal models, relatively little effort on ensuring the deployability of generated code on real robots, and other fundamental components of autonomous robot systems including robot perception, motion planning, and control. To bridge this ``ideal-to-real'' gap, this paper presents \textbf{RobotScript}, a platform for 1) a deployable robot manipulation pipeline powered by code generation; and 2) a code generation benchmark for robot manipulation tasks in free-form natural language. The RobotScript platform addresses this gap by emphasizing the unified interface with both simulation and real robots, based on abstraction from the Robot Operating System (ROS), ensuring syntax compliance and simulation validation with Gazebo. We demonstrate the adaptability of our code generation framework across multiple robot embodiments, including the Franka and UR5 robot arms, and multiple grippers. Additionally, our benchmark assesses reasoning abilities for physical space and constraints, highlighting the differences between GPT-3.5, GPT-4, and Gemini in handling complex physical interactions. Finally, we present a thorough evaluation on the whole system, exploring how each module in the pipeline: code generation, perception, motion planning, and even object geometric properties, impact the overall performance of the system.