 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFull-Atom Peptide Design based on Multi-modal Flow Matching
Jun 02, 2024Peptides, short chains of amino acid residues, play a vital role in numerous biological processes by interacting with other target molecules, offering substantial potential in drug discovery. In this work, we present PepFlow, the first multi-modal deep generative model grounded in the flow-matching framework for the design of full-atom peptides that target specific protein receptors. Drawing inspiration from the crucial roles of residue backbone orientations and side-chain dynamics in protein-peptide interactions, we characterize the peptide structure using rigid backbone frames within the $\mathrm{SE}(3)$ manifold and side-chain angles on high-dimensional tori. Furthermore, we represent discrete residue types in the peptide sequence as categorical distributions on the probability simplex. By learning the joint distributions of each modality using derived flows and vector fields on corresponding manifolds, our method excels in the fine-grained design of full-atom peptides. Harnessing the multi-modal paradigm, our approach adeptly tackles various tasks such as fix-backbone sequence design and side-chain packing through partial sampling. Through meticulously crafted experiments, we demonstrate that PepFlow exhibits superior performance in comprehensive benchmarks, highlighting its significant potential in computational peptide design and analysis.
Categorical Flow Matching on Statistical Manifolds
May 26, 2024We introduce Statistical Flow Matching (SFM), a novel and mathematically rigorous flow-matching framework on the manifold of parameterized probability measures inspired by the results from information geometry. We demonstrate the effectiveness of our method on the discrete generation problem by instantiating SFM on the manifold of categorical distributions whose geometric properties remain unexplored in previous discrete generative models. Utilizing the Fisher information metric, we equip the manifold with a Riemannian structure whose intrinsic geometries are effectively leveraged by following the shortest paths of geodesics. We develop an efficient training and sampling algorithm that overcomes numerical stability issues with a diffeomorphism between manifolds. Our distinctive geometric perspective of statistical manifolds allows us to apply optimal transport during training and interpret SFM as following the steepest direction of the natural gradient. Unlike previous models that rely on variational bounds for likelihood estimation, SFM enjoys the exact likelihood calculation for arbitrary probability measures. We manifest that SFM can learn more complex patterns on the statistical manifold where existing models often fail due to strong prior assumptions. Comprehensive experiments on real-world generative tasks ranging from image, text to biological domains further demonstrate that SFM achieves higher sampling quality and likelihood than other discrete diffusion or flow-based models.
Equivariant Neural Operator Learning with Graphon Convolution
Nov 17, 2023We propose a general architecture that combines the coefficient learning scheme with a residual operator layer for learning mappings between continuous functions in the 3D Euclidean space. Our proposed model is guaranteed to achieve SE(3)-equivariance by design. From the graph spectrum view, our method can be interpreted as convolution on graphons (dense graphs with infinitely many nodes), which we term InfGCN. By leveraging both the continuous graphon structure and the discrete graph structure of the input data, our model can effectively capture the geometric information while preserving equivariance. Through extensive experiments on large-scale electron density datasets, we observed that our model significantly outperformed the current state-of-the-art architectures. Multiple ablation studies were also carried out to demonstrate the effectiveness of the proposed architecture.
InstaFlow: One Step is Enough for High-Quality Diffusion-Based Text-to-Image Generation
Sep 12, 2023



Diffusion models have revolutionized text-to-image generation with its exceptional quality and creativity. However, its multi-step sampling process is known to be slow, often requiring tens of inference steps to obtain satisfactory results. Previous attempts to improve its sampling speed and reduce computational costs through distillation have been unsuccessful in achieving a functional one-step model. In this paper, we explore a recent method called Rectified Flow, which, thus far, has only been applied to small datasets. The core of Rectified Flow lies in its \emph{reflow} procedure, which straightens the trajectories of probability flows, refines the coupling between noises and images, and facilitates the distillation process with student models. We propose a novel text-conditioned pipeline to turn Stable Diffusion (SD) into an ultra-fast one-step model, in which we find reflow plays a critical role in improving the assignment between noise and images. Leveraging our new pipeline, we create, to the best of our knowledge, the first one-step diffusion-based text-to-image generator with SD-level image quality, achieving an FID (Frechet Inception Distance) of $23.3$ on MS COCO 2017-5k, surpassing the previous state-of-the-art technique, progressive distillation, by a significant margin ($37.2$ $\rightarrow$ $23.3$ in FID). By utilizing an expanded network with 1.7B parameters, we further improve the FID to $22.4$. We call our one-step models \emph{InstaFlow}. On MS COCO 2014-30k, InstaFlow yields an FID of $13.1$ in just $0.09$ second, the best in $\leq 0.1$ second regime, outperforming the recent StyleGAN-T ($13.9$ in $0.1$ second). Notably, the training of InstaFlow only costs 199 A100 GPU days. Project page:~\url{https://github.com/gnobitab/InstaFlow}.
3D Equivariant Diffusion for Target-Aware Molecule Generation and Affinity Prediction
Mar 06, 2023



Rich data and powerful machine learning models allow us to design drugs for a specific protein target \textit{in silico}. Recently, the inclusion of 3D structures during targeted drug design shows superior performance to other target-free models as the atomic interaction in the 3D space is explicitly modeled. However, current 3D target-aware models either rely on the voxelized atom densities or the autoregressive sampling process, which are not equivariant to rotation or easily violate geometric constraints resulting in unrealistic structures. In this work, we develop a 3D equivariant diffusion model to solve the above challenges. To achieve target-aware molecule design, our method learns a joint generative process of both continuous atom coordinates and categorical atom types with a SE(3)-equivariant network. Moreover, we show that our model can serve as an unsupervised feature extractor to estimate the binding affinity under proper parameterization, which provides an effective way for drug screening. To evaluate our model, we propose a comprehensive framework to evaluate the quality of sampled molecules from different dimensions. Empirical studies show our model could generate molecules with more realistic 3D structures and better affinities towards the protein targets, and improve binding affinity ranking and prediction without retraining.
Active Learning in Brain Tumor Segmentation with Uncertainty Sampling, Annotation Redundancy Restriction, and Data Initialization
Feb 05, 2023



Deep learning models have demonstrated great potential in medical 3D imaging, but their development is limited by the expensive, large volume of annotated data required. Active learning (AL) addresses this by training a model on a subset of the most informative data samples without compromising performance. We compared different AL strategies and propose a framework that minimizes the amount of data needed for state-of-the-art performance. 638 multi-institutional brain tumor MRI images were used to train a 3D U-net model and compare AL strategies. We investigated uncertainty sampling, annotation redundancy restriction, and initial dataset selection techniques. Uncertainty estimation techniques including Bayesian estimation with dropout, bootstrapping, and margins sampling were compared to random query. Strategies to avoid annotation redundancy by removing similar images within the to-be-annotated subset were considered as well. We determined the minimum amount of data necessary to achieve similar performance to the model trained on the full dataset ({\alpha} = 0.1). A variance-based selection strategy using radiomics to identify the initial training dataset is also proposed. Bayesian approximation with dropout at training and testing showed similar results to that of the full data model with less than 20% of the training data (p=0.293) compared to random query achieving similar performance at 56.5% of the training data (p=0.814). Annotation redundancy restriction techniques achieved state-of-the-art performance at approximately 40%-50% of the training data. Radiomics dataset initialization had higher Dice with initial dataset sizes of 20 and 80 images, but improvements were not significant. In conclusion, we investigated various AL strategies with dropout uncertainty estimation achieving state-of-the-art performance with the least annotated data.
Efficient Meta Reinforcement Learning for Preference-based Fast Adaptation
Nov 20, 2022


Learning new task-specific skills from a few trials is a fundamental challenge for artificial intelligence. Meta reinforcement learning (meta-RL) tackles this problem by learning transferable policies that support few-shot adaptation to unseen tasks. Despite recent advances in meta-RL, most existing methods require the access to the environmental reward function of new tasks to infer the task objective, which is not realistic in many practical applications. To bridge this gap, we study the problem of few-shot adaptation in the context of human-in-the-loop reinforcement learning. We develop a meta-RL algorithm that enables fast policy adaptation with preference-based feedback. The agent can adapt to new tasks by querying human's preference between behavior trajectories instead of using per-step numeric rewards. By extending techniques from information theory, our approach can design query sequences to maximize the information gain from human interactions while tolerating the inherent error of non-expert human oracle. In experiments, we extensively evaluate our method, Adaptation with Noisy OracLE (ANOLE), on a variety of meta-RL benchmark tasks and demonstrate substantial improvement over baseline algorithms in terms of both feedback efficiency and error tolerance.
Split Time Series into Patches: Rethinking Long-term Series Forecasting with Dateformer
Jul 12, 2022



Time is one of the most significant characteristics of time-series, yet has received insufficient attention. Prior time-series forecasting research has mainly focused on mapping a past subseries (lookback window) to a future series (forecast window), and time of series often just play an auxiliary role even completely ignored in most cases. Due to the point-wise processing within these windows, extrapolating series to longer-term future is tough in the pattern. To overcome this barrier, we propose a brand-new time-series forecasting framework named Dateformer who turns attention to modeling time instead of following the above practice. Specifically, time-series are first split into patches by day to supervise the learning of dynamic date-representations with Date Encoder Representations from Transformers (DERT). These representations are then fed into a simple decoder to produce a coarser (or global) prediction, and used to help the model seek valuable information from the lookback window to learn a refined (or local) prediction. Dateformer obtains the final result by summing the above two parts. Our empirical studies on seven benchmarks show that the time-modeling method is more efficient for long-term series forecasting compared with sequence modeling methods. Dateformer yields state-of-the-art accuracy with a 40% remarkable relative improvement, and broadens the maximum credible forecasting range to a half-yearly level.
Is Self-Supervised Learning More Robust Than Supervised Learning?
Jun 10, 2022
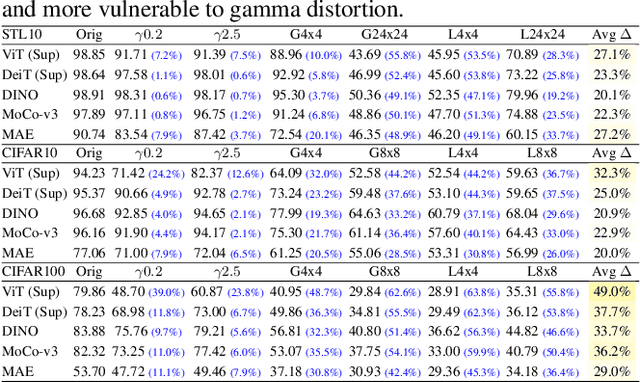
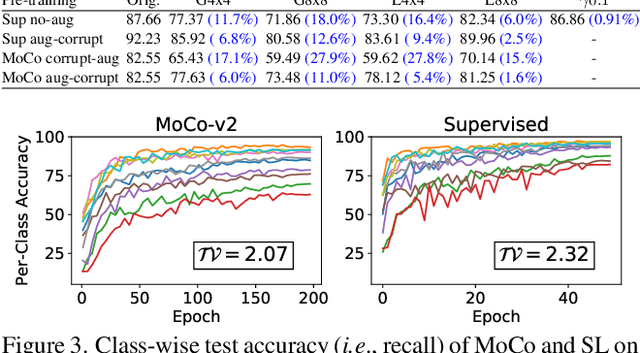

Self-supervised contrastive learning is a powerful tool to learn visual representation without labels. Prior work has primarily focused on evaluating the recognition accuracy of various pre-training algorithms, but has overlooked other behavioral aspects. In addition to accuracy, distributional robustness plays a critical role in the reliability of machine learning models. We design and conduct a series of robustness tests to quantify the behavioral differences between contrastive learning and supervised learning to downstream or pre-training data distribution changes. These tests leverage data corruptions at multiple levels, ranging from pixel-level gamma distortion to patch-level shuffling and to dataset-level distribution shift. Our tests unveil intriguing robustness behaviors of contrastive and supervised learning. On the one hand, under downstream corruptions, we generally observe that contrastive learning is surprisingly more robust than supervised learning. On the other hand, under pre-training corruptions, we find contrastive learning vulnerable to patch shuffling and pixel intensity change, yet less sensitive to dataset-level distribution change. We attempt to explain these results through the role of data augmentation and feature space properties. Our insight has implications in improving the downstream robustness of supervised learning.
Pocket2Mol: Efficient Molecular Sampling Based on 3D Protein Pockets
May 15, 2022



Deep generative models have achieved tremendous success in designing novel drug molecules in recent years. A new thread of works have shown the great potential in advancing the specificity and success rate of in silico drug design by considering the structure of protein pockets. This setting posts fundamental computational challenges in sampling new chemical compounds that could satisfy multiple geometrical constraints imposed by pockets. Previous sampling algorithms either sample in the graph space or only consider the 3D coordinates of atoms while ignoring other detailed chemical structures such as bond types and functional groups. To address the challenge, we develop Pocket2Mol, an E(3)-equivariant generative network composed of two modules: 1) a new graph neural network capturing both spatial and bonding relationships between atoms of the binding pockets and 2) a new efficient algorithm which samples new drug candidates conditioned on the pocket representations from a tractable distribution without relying on MCMC. Experimental results demonstrate that molecules sampled from Pocket2Mol achieve significantly better binding affinity and other drug properties such as druglikeness and synthetic accessibility.