 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchTriplet: Self-Supervised Scenarized Sketch-Text-Image Triplet Generation
May 29, 2024The scarcity of free-hand sketch presents a challenging problem. Despite the emergence of some large-scale sketch datasets, these datasets primarily consist of sketches at the single-object level. There continues to be a lack of large-scale paired datasets for scene sketches. In this paper, we propose a self-supervised method for scene sketch generation that does not rely on any existing scene sketch, enabling the transformation of single-object sketches into scene sketches. To accomplish this, we introduce a method for vector sketch captioning and sketch semantic expansion. Additionally, we design a sketch generation network that incorporates a fusion of multi-modal perceptual constraints, suitable for application in zero-shot image-to-sketch downstream task, demonstrating state-of-the-art performance through experimental validation. Finally, leveraging our proposed sketch-to-sketch generation method, we contribute a large-scale dataset centered around scene sketches, comprising highly semantically consistent "text-sketch-image" triplets. Our research confirms that this dataset can significantly enhance the capabilities of existing models in sketch-based image retrieval and sketch-controlled image synthesis tasks. We will make our dataset and code publicly available.
Robust portfolio optimization model for electronic coupon allocation
May 21, 2024Currently, many e-commerce websites issue online/electronic coupons as an effective tool for promoting sales of various products and services. We focus on the problem of optimally allocating coupons to customers subject to a budget constraint on an e-commerce website. We apply a robust portfolio optimization model based on customer segmentation to the coupon allocation problem. We also validate the efficacy of our method through numerical experiments using actual data from randomly distributed coupons. Main contributions of our research are twofold. First, we handle six types of coupons, thereby making it extremely difficult to accurately estimate the difference in the effects of various coupons. Second, we demonstrate from detailed numerical results that the robust optimization model achieved larger uplifts of sales than did the commonly-used multiple-choice knapsack model and the conventional mean-variance optimization model. Our results open up great potential for robust portfolio optimization as an effective tool for practical coupon allocation.
IM-RAG: Multi-Round Retrieval-Augmented Generation Through Learning Inner Monologues
May 15, 2024Although the Retrieval-Augmented Generation (RAG) paradigms can use external knowledge to enhance and ground the outputs of Large Language Models (LLMs) to mitigate generative hallucinations and static knowledge base problems, they still suffer from limited flexibility in adopting Information Retrieval (IR) systems with varying capabilities, constrained interpretability during the multi-round retrieval process, and a lack of end-to-end optimization. To address these challenges, we propose a novel LLM-centric approach, IM-RAG, that integrates IR systems with LLMs to support multi-round RAG through learning Inner Monologues (IM, i.e., the human inner voice that narrates one's thoughts). During the IM process, the LLM serves as the core reasoning model (i.e., Reasoner) to either propose queries to collect more information via the Retriever or to provide a final answer based on the conversational context. We also introduce a Refiner that improves the outputs from the Retriever, effectively bridging the gap between the Reasoner and IR modules with varying capabilities and fostering multi-round communications. The entire IM process is optimized via Reinforcement Learning (RL) where a Progress Tracker is incorporated to provide mid-step rewards, and the answer prediction is further separately optimized via Supervised Fine-Tuning (SFT). We conduct extensive experiments with the HotPotQA dataset, a popular benchmark for retrieval-based, multi-step question-answering. The results show that our approach achieves state-of-the-art (SOTA) performance while providing high flexibility in integrating IR modules as well as strong interpretability exhibited in the learned inner monologues.
Decentralized Kernel Ridge Regression Based on Data-dependent Random Feature
May 13, 2024Random feature (RF) has been widely used for node consistency in decentralized kernel ridge regression (KRR). Currently, the consistency is guaranteed by imposing constraints on coefficients of features, necessitating that the random features on different nodes are identical. However, in many applications, data on different nodes varies significantly on the number or distribution, which calls for adaptive and data-dependent methods that generate different RFs. To tackle the essential difficulty, we propose a new decentralized KRR algorithm that pursues consensus on decision functions, which allows great flexibility and well adapts data on nodes. The convergence is rigorously given and the effectiveness is numerically verified: by capturing the characteristics of the data on each node, while maintaining the same communication costs as other methods, we achieved an average regression accuracy improvement of 25.5\% across six real-world data sets.
Efficient Pretraining Model based on Multi-Scale Local Visual Field Feature Reconstruction for PCB CT Image Element Segmentation
May 09, 2024Element segmentation is a key step in nondestructive testing of Printed Circuit Boards (PCB) based on Computed Tomography (CT) technology. In recent years, the rapid development of self-supervised pretraining technology can obtain general image features without labeled samples, and then use a small amount of labeled samples to solve downstream tasks, which has a good potential in PCB element segmentation. At present, Masked Image Modeling (MIM) pretraining model has been initially applied in PCB CT image element segmentation. However, due to the small and regular size of PCB elements such as vias, wires, and pads, the global visual field has redundancy for a single element reconstruction, which may damage the performance of the model. Based on this issue, we propose an efficient pretraining model based on multi-scale local visual field feature reconstruction for PCB CT image element segmentation (EMLR-seg). In this model, the teacher-guided MIM pretraining model is introduced into PCB CT image element segmentation for the first time, and a multi-scale local visual field extraction (MVE) module is proposed to reduce redundancy by focusing on local visual fields. At the same time, a simple 4-Transformer-blocks decoder is used. Experiments show that EMLR-seg can achieve 88.6% mIoU on the PCB CT image dataset we proposed, which exceeds 1.2% by the baseline model, and the training time is reduced by 29.6 hours, a reduction of 17.4% under the same experimental condition, which reflects the advantage of EMLR-seg in terms of performance and efficiency.
Fourier Transform-based Wavenumber Domain 3D Imaging in RIS-aided Communication Systems
Apr 07, 2024Radio imaging is rapidly gaining prominence in the design of future communication systems, with the potential to utilize reconfigurable intelligent surfaces (RISs) as imaging apertures. Although the sparsity of targets in three-dimensional (3D) space has led most research to adopt compressed sensing (CS)-based imaging algorithms, these often require substantial computational and memory burdens. Drawing inspiration from conventional Fourier transform (FT)-based imaging methods, our research seeks to accelerate radio imaging in RIS-aided communication systems. To begin, we introduce a two-stage wavenumber domain 3D imaging technique: first, we modify RIS phase shifts to recover the equivalent channel response from the user equipment to the RIS array, subsequently employing traditional FT-based wavenumber domain methods to produce target images. We also determine the diffraction resolution limits of the system through k-space analysis, taking into account factors including system bandwidth, transmission direction, operating frequency, and the angle subtended by the RIS. Addressing the challenge of limited pilots in communication systems, we unveil an innovative algorithm that merges the strengths of both FT- and CS-based techniques by substituting the expansive sensing matrix with FT-based operators. Our simulation outcomes confirm that our proposed FT-based methods achieve high-quality images while demanding few time, memory, and communication resources.
Exploring LLMs as a Source of Targeted Synthetic Textual Data to Minimize High Confidence Misclassifications
Apr 02, 2024



Natural Language Processing (NLP) models optimized for predictive performance often make high confidence errors and suffer from vulnerability to adversarial and out-of-distribution data. Existing work has mainly focused on mitigation of such errors using either humans or an automated approach. In this study, we explore the usage of large language models (LLMs) for data augmentation as a potential solution to the issue of NLP models making wrong predictions with high confidence during classification tasks. We compare the effectiveness of synthetic data generated by LLMs with that of human data obtained via the same procedure. For mitigation, humans or LLMs provide natural language characterizations of high confidence misclassifications to generate synthetic data, which are then used to extend the training set. We conduct an extensive evaluation of our approach on three classification tasks and demonstrate its effectiveness in reducing the number of high confidence misclassifications present in the model, all while maintaining the same level of accuracy. Moreover, we find that the cost gap between humans and LLMs surpasses an order of magnitude, as LLMs attain human-like performance while being more scalable.
RIS-aided Single-frequency 3D Imaging by Exploiting Multi-view Image Correlations
Mar 18, 2024



Retrieving range information in three-dimensional (3D) radio imaging is particularly challenging due to the limited communication bandwidth and pilot resources. To address this issue, we consider a reconfigurable intelligent surface (RIS)-aided uplink communication scenario, generating multiple measurements through RIS phase adjustment. This study successfully realizes 3D single-frequency imaging by exploiting the near-field multi-view image correlations deduced from user mobility. We first highlight the significance of considering anisotropy in multi-view image formation by investigating radar cross-section properties and diffraction resolution limits. We then propose a novel model for joint multi-view 3D imaging that incorporates occlusion effects and anisotropic scattering. These factors lead to slow image support variation and smooth coefficient evolution, which are mathematically modeled as Markov processes. Based on this model, we employ the Expectation Maximization-Turbo-Generalized Approximate Message Passing algorithm for joint multi-view single-frequency 3D imaging with limited measurements. Simulation results reveal the superiority of joint multi-view imaging in terms of enhanced imaging ranges, accuracies, and anisotropy characterization compared to single-view imaging. Combining adjacent observations for joint multi-view imaging enables a reduction in the measurement overhead by 80%.
Recent Advances in 3D Gaussian Splatting
Mar 17, 2024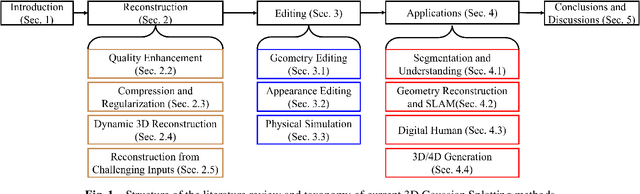
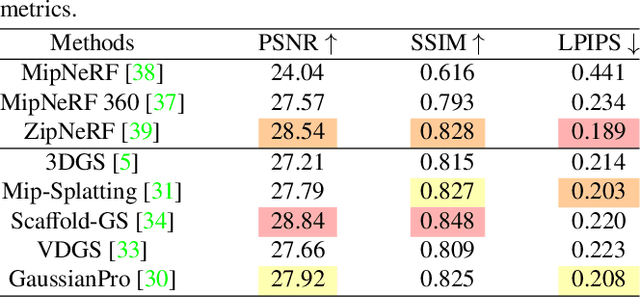
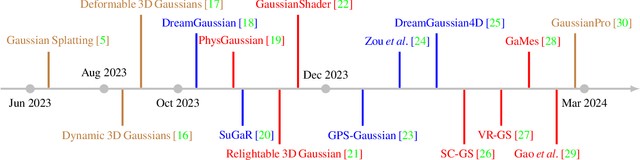
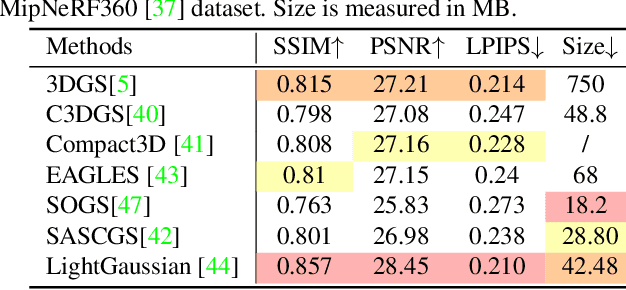
The emergence of 3D Gaussian Splatting (3DGS) has greatly accelerated the rendering speed of novel view synthesis. Unlike neural implicit representations like Neural Radiance Fields (NeRF) that represent a 3D scene with position and viewpoint-conditioned neural networks, 3D Gaussian Splatting utilizes a set of Gaussian ellipsoids to model the scene so that efficient rendering can be accomplished by rasterizing Gaussian ellipsoids into images. Apart from the fast rendering speed, the explicit representation of 3D Gaussian Splatting facilitates editing tasks like dynamic reconstruction, geometry editing, and physical simulation. Considering the rapid change and growing number of works in this field, we present a literature review of recent 3D Gaussian Splatting methods, which can be roughly classified into 3D reconstruction, 3D editing, and other downstream applications by functionality. Traditional point-based rendering methods and the rendering formulation of 3D Gaussian Splatting are also illustrated for a better understanding of this technique. This survey aims to help beginners get into this field quickly and provide experienced researchers with a comprehensive overview, which can stimulate the future development of the 3D Gaussian Splatting representation.
Generation is better than Modification: Combating High Class Homophily Variance in Graph Anomaly Detection
Mar 15, 2024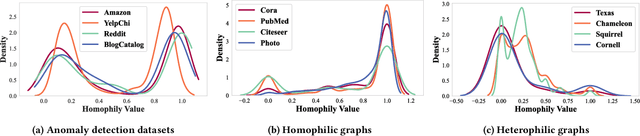
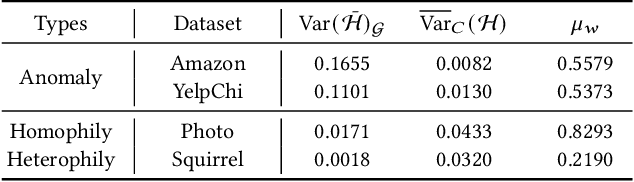
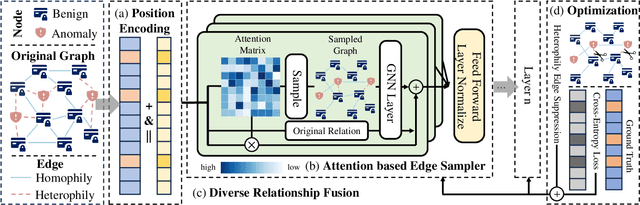
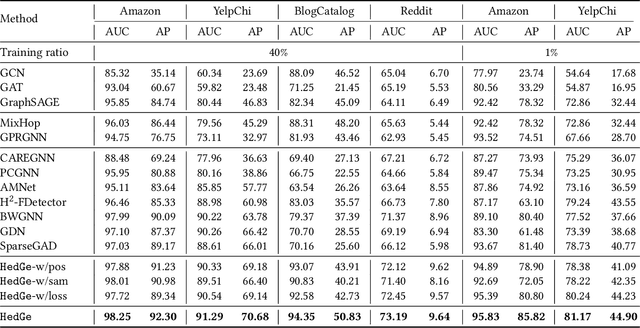
Graph-based anomaly detection is currently an important research topic in the field of graph neural networks (GNNs). We find that in graph anomaly detection, the homophily distribution differences between different classes are significantly greater than those in homophilic and heterophilic graphs. For the first time, we introduce a new metric called Class Homophily Variance, which quantitatively describes this phenomenon. To mitigate its impact, we propose a novel GNN model named Homophily Edge Generation Graph Neural Network (HedGe). Previous works typically focused on pruning, selecting or connecting on original relationships, and we refer to these methods as modifications. Different from these works, our method emphasizes generating new relationships with low class homophily variance, using the original relationships as an auxiliary. HedGe samples homophily adjacency matrices from scratch using a self-attention mechanism, and leverages nodes that are relevant in the feature space but not directly connected in the original graph. Additionally, we modify the loss function to punish the generation of unnecessary heterophilic edges by the model. Extensive comparison experiments demonstrate that HedGe achieved the best performance across multiple benchmark datasets, including anomaly detection and edgeless node classification. The proposed model also improves the robustness under the novel Heterophily Attack with increased class homophily variance on other graph classification tasks.