 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-task Manipulation Policy Modeling with Visuomotor Latent Diffusion
Mar 12, 2024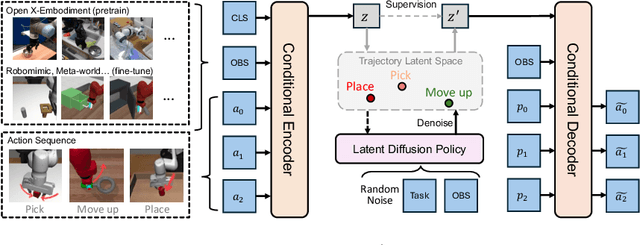
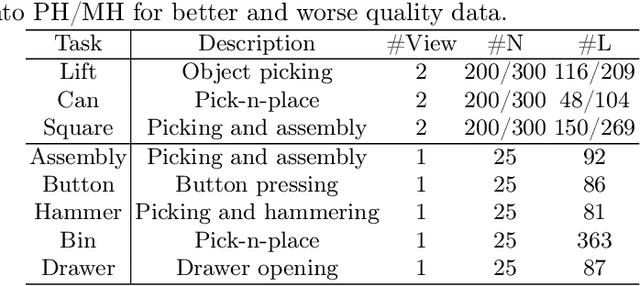
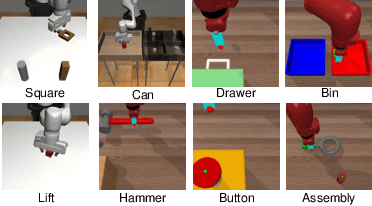
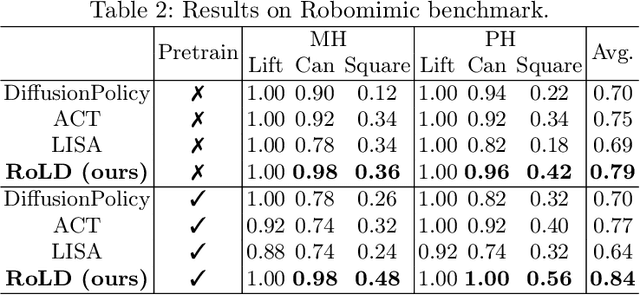
Modeling a generalized visuomotor policy has been a longstanding challenge for both computer vision and robotics communities. Existing approaches often fail to efficiently leverage cross-dataset resources or rely on heavy Vision-Language models, which require substantial computational resources, thereby limiting their multi-task performance and application potential. In this paper, we introduce a novel paradigm that effectively utilizes latent modeling of manipulation skills and an efficient visuomotor latent diffusion policy, which enhances the utilizing of existing cross-embodiment and cross-environment datasets, thereby improving multi-task capabilities. Our methodology consists of two decoupled phases: action modeling and policy modeling. Firstly, we introduce a task-agnostic, embodiment-aware trajectory latent autoencoder for unified action skills modeling. This step condenses action data and observation into a condensed latent space, effectively benefiting from large-scale cross-datasets. Secondly, we propose to use a visuomotor latent diffusion policy that recovers target skill latent from noises for effective task execution. We conducted extensive experiments on two widely used benchmarks, and the results demonstrate the effectiveness of our proposed paradigms on multi-tasking and pre-training. Code is available at https://github.com/AlbertTan404/RoLD.
Deep Learning for Cross-Domain Data Fusion in Urban Computing: Taxonomy, Advances, and Outlook
Feb 29, 2024As cities continue to burgeon, Urban Computing emerges as a pivotal discipline for sustainable development by harnessing the power of cross-domain data fusion from diverse sources (e.g., geographical, traffic, social media, and environmental data) and modalities (e.g., spatio-temporal, visual, and textual modalities). Recently, we are witnessing a rising trend that utilizes various deep-learning methods to facilitate cross-domain data fusion in smart cities. To this end, we propose the first survey that systematically reviews the latest advancements in deep learning-based data fusion methods tailored for urban computing. Specifically, we first delve into data perspective to comprehend the role of each modality and data source. Secondly, we classify the methodology into four primary categories: feature-based, alignment-based, contrast-based, and generation-based fusion methods. Thirdly, we further categorize multi-modal urban applications into seven types: urban planning, transportation, economy, public safety, society, environment, and energy. Compared with previous surveys, we focus more on the synergy of deep learning methods with urban computing applications. Furthermore, we shed light on the interplay between Large Language Models (LLMs) and urban computing, postulating future research directions that could revolutionize the field. We firmly believe that the taxonomy, progress, and prospects delineated in our survey stand poised to significantly enrich the research community. The summary of the comprehensive and up-to-date paper list can be found at https://github.com/yoshall/Awesome-Multimodal-Urban-Computing.
Federated Continual Learning via Knowledge Fusion: A Survey
Dec 27, 2023Data privacy and silos are nontrivial and greatly challenging in many real-world applications. Federated learning is a decentralized approach to training models across multiple local clients without the exchange of raw data from client devices to global servers. However, existing works focus on a static data environment and ignore continual learning from streaming data with incremental tasks. Federated Continual Learning (FCL) is an emerging paradigm to address model learning in both federated and continual learning environments. The key objective of FCL is to fuse heterogeneous knowledge from different clients and retain knowledge of previous tasks while learning on new ones. In this work, we delineate federated learning and continual learning first and then discuss their integration, i.e., FCL, and particular FCL via knowledge fusion. In summary, our motivations are four-fold: we (1) raise a fundamental problem called ''spatial-temporal catastrophic forgetting'' and evaluate its impact on the performance using a well-known method called federated averaging (FedAvg), (2) integrate most of the existing FCL methods into two generic frameworks, namely synchronous FCL and asynchronous FCL, (3) categorize a large number of methods according to the mechanism involved in knowledge fusion, and finally (4) showcase an outlook on the future work of FCL.
MLPST: MLP is All You Need for Spatio-Temporal Prediction
Sep 23, 2023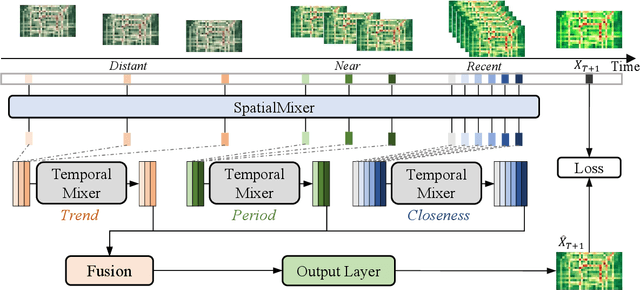
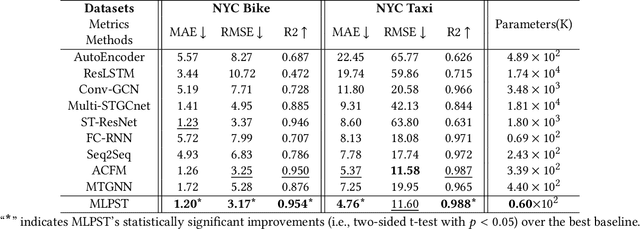
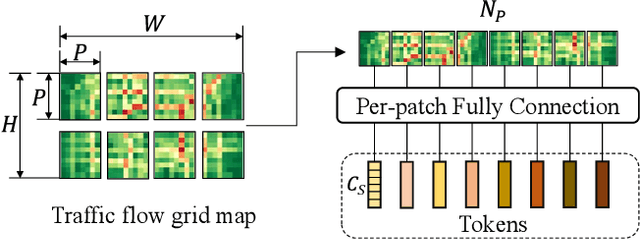
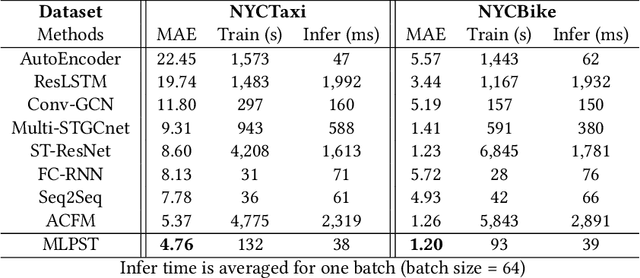
Traffic prediction is a typical spatio-temporal data mining task and has great significance to the public transportation system. Considering the demand for its grand application, we recognize key factors for an ideal spatio-temporal prediction method: efficient, lightweight, and effective. However, the current deep model-based spatio-temporal prediction solutions generally own intricate architectures with cumbersome optimization, which can hardly meet these expectations. To accomplish the above goals, we propose an intuitive and novel framework, MLPST, a pure multi-layer perceptron architecture for traffic prediction. Specifically, we first capture spatial relationships from both local and global receptive fields. Then, temporal dependencies in different intervals are comprehensively considered. Through compact and swift MLP processing, MLPST can well capture the spatial and temporal dependencies while requiring only linear computational complexity, as well as model parameters that are more than an order of magnitude lower than baselines. Extensive experiments validated the superior effectiveness and efficiency of MLPST against advanced baselines, and among models with optimal accuracy, MLPST achieves the best time and space efficiency.
Spatio-Temporal Contrastive Self-Supervised Learning for POI-level Crowd Flow Inference
Sep 12, 2023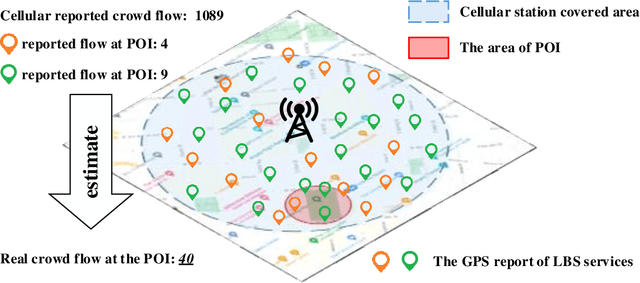
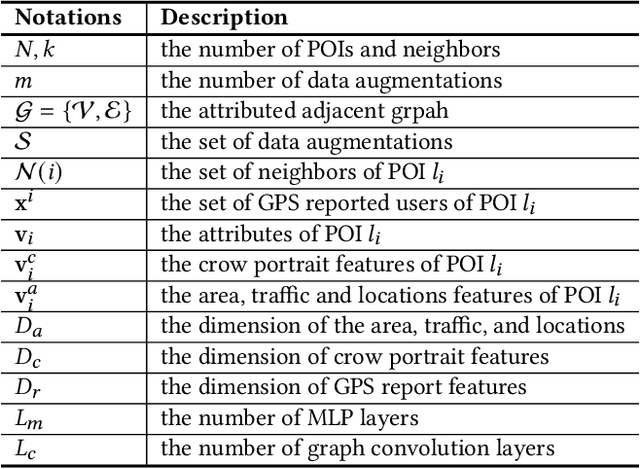
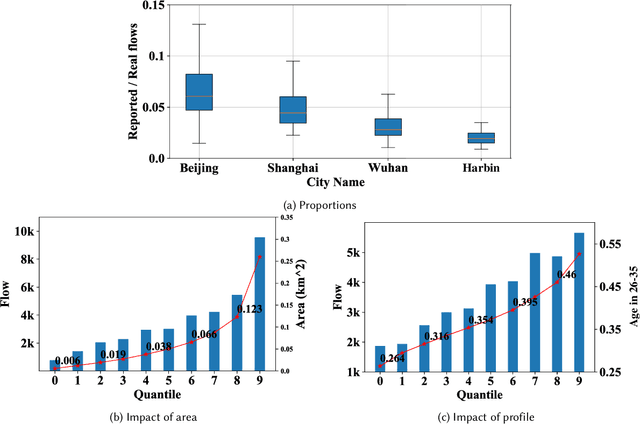
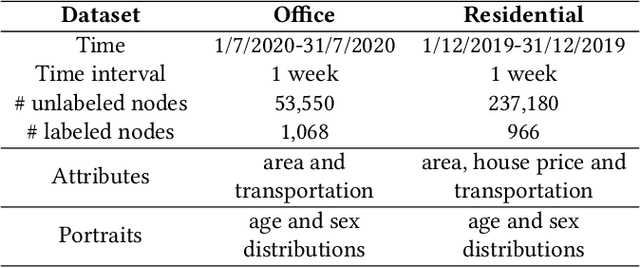
Accurate acquisition of crowd flow at Points of Interest (POIs) is pivotal for effective traffic management, public service, and urban planning. Despite this importance, due to the limitations of urban sensing techniques, the data quality from most sources is inadequate for monitoring crowd flow at each POI. This renders the inference of accurate crowd flow from low-quality data a critical and challenging task. The complexity is heightened by three key factors: 1) The scarcity and rarity of labeled data, 2) The intricate spatio-temporal dependencies among POIs, and 3) The myriad correlations between precise crowd flow and GPS reports. To address these challenges, we recast the crowd flow inference problem as a self-supervised attributed graph representation learning task and introduce a novel Contrastive Self-learning framework for Spatio-Temporal data (CSST). Our approach initiates with the construction of a spatial adjacency graph founded on the POIs and their respective distances. We then employ a contrastive learning technique to exploit large volumes of unlabeled spatio-temporal data. We adopt a swapped prediction approach to anticipate the representation of the target subgraph from similar instances. Following the pre-training phase, the model is fine-tuned with accurate crowd flow data. Our experiments, conducted on two real-world datasets, demonstrate that the CSST pre-trained on extensive noisy data consistently outperforms models trained from scratch.
CED: Consistent ensemble distillation for audio tagging
Sep 08, 2023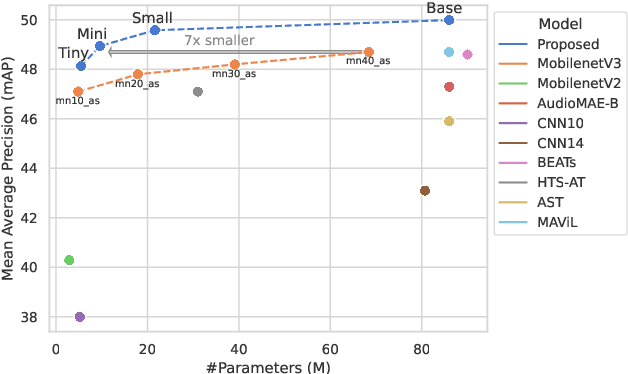
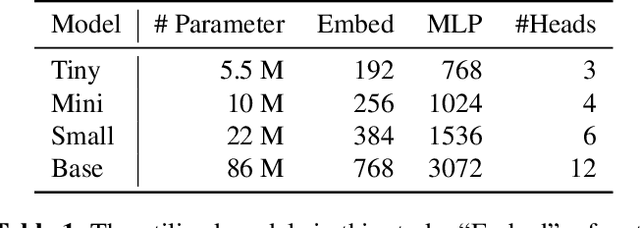
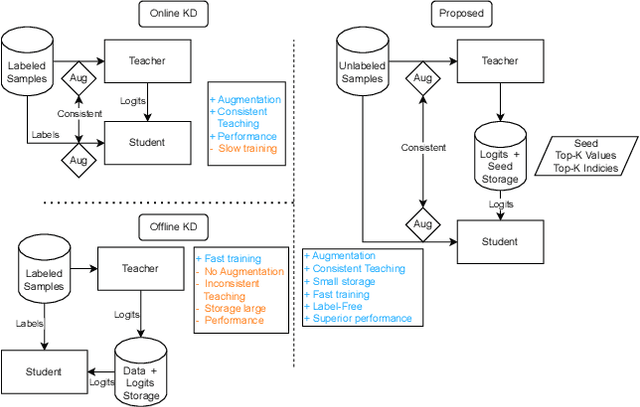

Augmentation and knowledge distillation (KD) are well-established techniques employed in audio classification tasks, aimed at enhancing performance and reducing model sizes on the widely recognized Audioset (AS) benchmark. Although both techniques are effective individually, their combined use, called consistent teaching, hasn't been explored before. This paper proposes CED, a simple training framework that distils student models from large teacher ensembles with consistent teaching. To achieve this, CED efficiently stores logits as well as the augmentation methods on disk, making it scalable to large-scale datasets. Central to CED's efficacy is its label-free nature, meaning that only the stored logits are used for the optimization of a student model only requiring 0.3\% additional disk space for AS. The study trains various transformer-based models, including a 10M parameter model achieving a 49.0 mean average precision (mAP) on AS. Pretrained models and code are available at https://github.com/RicherMans/CED.
Focus on the Sound around You: Monaural Target Speaker Extraction via Distance and Speaker Information
Jun 28, 2023

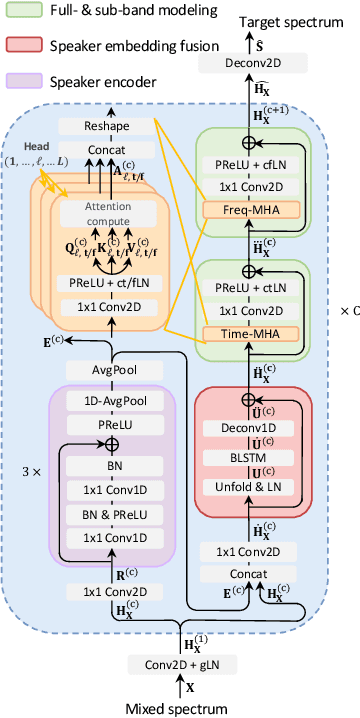
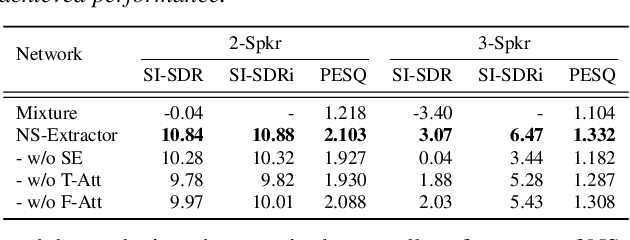
Previously, Target Speaker Extraction (TSE) has yielded outstanding performance in certain application scenarios for speech enhancement and source separation. However, obtaining auxiliary speaker-related information is still challenging in noisy environments with significant reverberation. inspired by the recently proposed distance-based sound separation, we propose the near sound (NS) extractor, which leverages distance information for TSE to reliably extract speaker information without requiring previous speaker enrolment, called speaker embedding self-enrollment (SESE). Full- & sub-band modeling is introduced to enhance our NS-Extractor's adaptability towards environments with significant reverberation. Experimental results on several cross-datasets demonstrate the effectiveness of our improvements and the excellent performance of our proposed NS-Extractor in different application scenarios.
AV-SepFormer: Cross-Attention SepFormer for Audio-Visual Target Speaker Extraction
Jun 25, 2023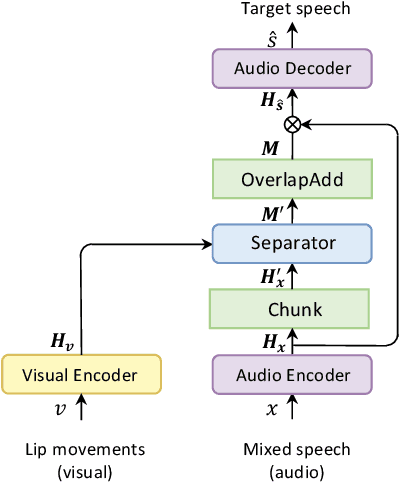

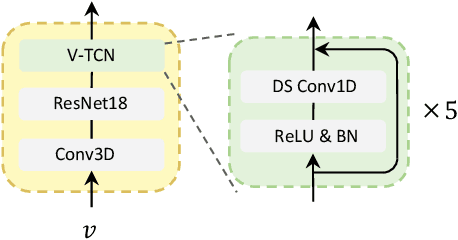

Visual information can serve as an effective cue for target speaker extraction (TSE) and is vital to improving extraction performance. In this paper, we propose AV-SepFormer, a SepFormer-based attention dual-scale model that utilizes cross- and self-attention to fuse and model features from audio and visual. AV-SepFormer splits the audio feature into a number of chunks, equivalent to the length of the visual feature. Then self- and cross-attention are employed to model and fuse the multi-modal features. Furthermore, we use a novel 2D positional encoding, that introduces the positional information between and within chunks and provides significant gains over the traditional positional encoding. Our model has two key advantages: the time granularity of audio chunked feature is synchronized to the visual feature, which alleviates the harm caused by the inconsistency of audio and video sampling rate; by combining self- and cross-attention, feature fusion and speech extraction processes are unified within an attention paradigm. The experimental results show that AV-SepFormer significantly outperforms other existing methods.
Understanding temporally weakly supervised training: A case study for keyword spotting
May 30, 2023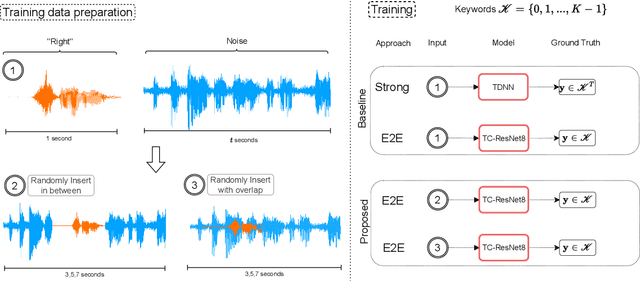
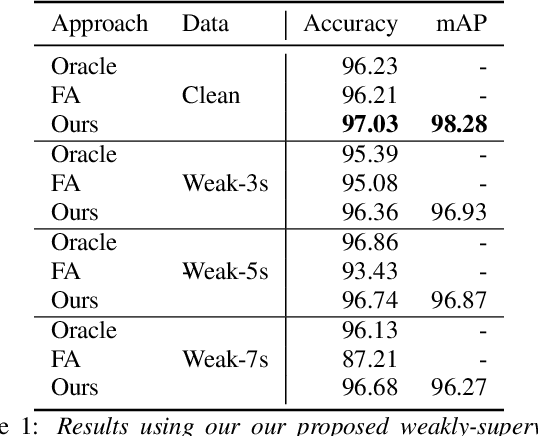

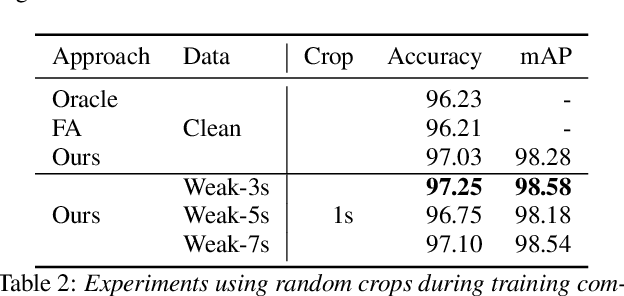
The currently most prominent algorithm to train keyword spotting (KWS) models with deep neural networks (DNNs) requires strong supervision i.e., precise knowledge of the spoken keyword location in time. Thus, most KWS approaches treat the presence of redundant data, such as noise, within their training set as an obstacle. A common training paradigm to deal with data redundancies is to use temporally weakly supervised learning, which only requires providing labels on a coarse scale. This study explores the limits of DNN training using temporally weak labeling with applications in KWS. We train a simple end-to-end classifier on the common Google Speech Commands dataset with increased difficulty by randomly appending and adding noise to the training dataset. Our results indicate that temporally weak labeling can achieve comparable results to strongly supervised baselines while having a less stringent labeling requirement. In the presence of noise, weakly supervised models are capable to localize and extract target keywords without explicit supervision, leading to a performance increase compared to strongly supervised approaches.
Streaming Audio Transformers for Online Audio Tagging
May 29, 2023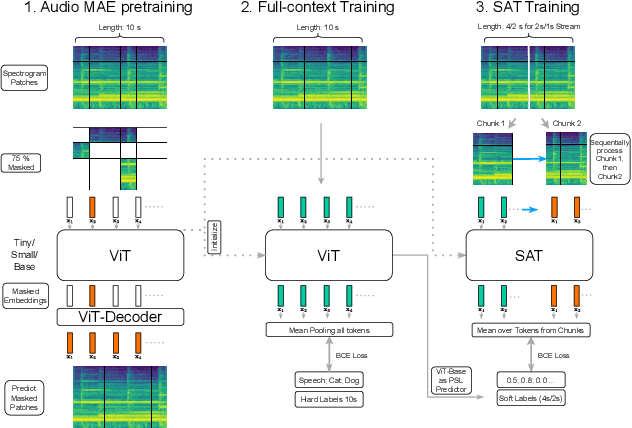
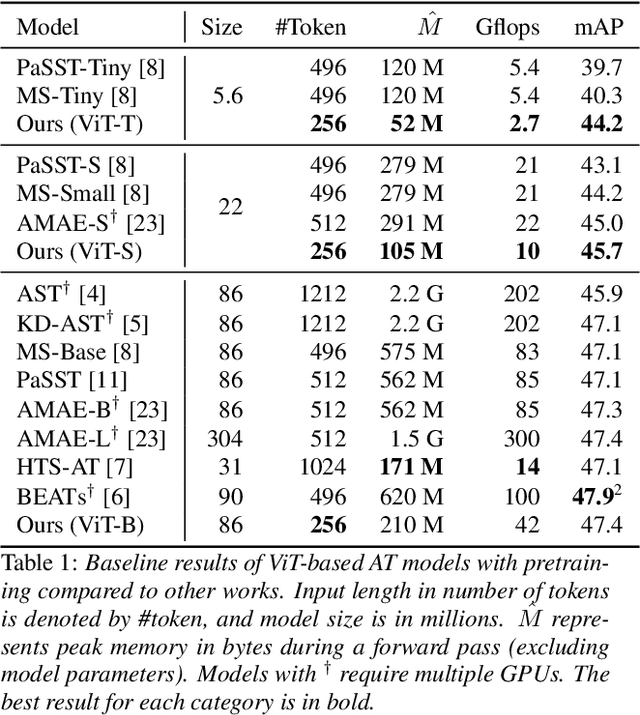
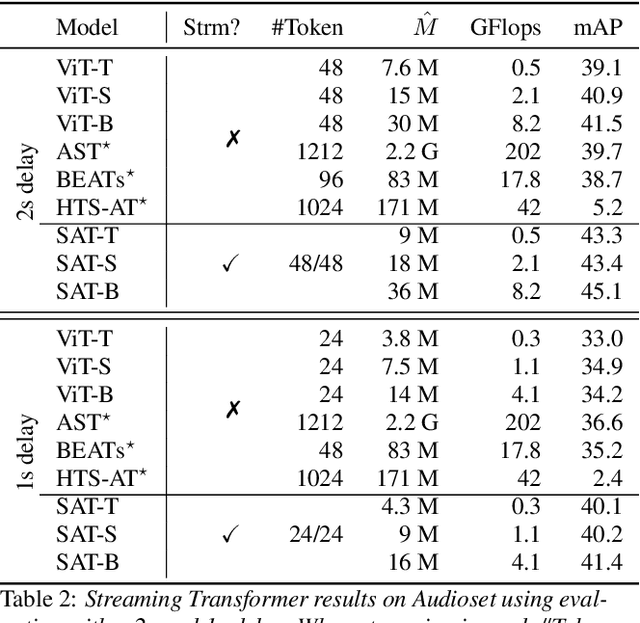
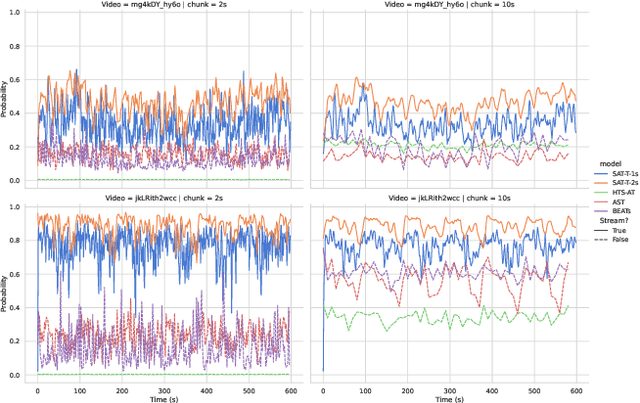
Transformers have emerged as a prominent model framework for audio tagging (AT), boasting state-of-the-art (SOTA) performance on the widely-used Audioset dataset. However, their impressive performance often comes at the cost of high memory usage, slow inference speed, and considerable model delay, rendering them impractical for real-world AT applications. In this study, we introduce streaming audio transformers (SAT) that combine the vision transformer (ViT) architecture with Transformer-Xl-like chunk processing, enabling efficient processing of long-range audio signals. Our proposed SAT is benchmarked against other transformer-based SOTA methods, achieving significant improvements in terms of mean average precision (mAP) at a delay of 2s and 1s, while also exhibiting significantly lower memory usage and computational overhead. Checkpoints are publicly available https://github.com/RicherMans/SAT.