 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNPHardEval4V: A Dynamic Reasoning Benchmark of Multimodal Large Language Models
Mar 05, 2024



Understanding the reasoning capabilities of Multimodal Large Language Models (MLLMs) is an important area of research. In this study, we introduce a dynamic benchmark, NPHardEval4V, aimed at addressing the existing gaps in evaluating the pure reasoning abilities of MLLMs. Our benchmark aims to provide a venue to disentangle the effect of various factors such as image recognition and instruction following, from the overall performance of the models, allowing us to focus solely on evaluating their reasoning abilities. It is built by converting textual description of questions from NPHardEval to image representations. Our findings reveal significant discrepancies in reasoning abilities across different models and highlight the relatively weak performance of MLLMs compared to LLMs in terms of reasoning. We also investigate the impact of different prompting styles, including visual, text, and combined visual and text prompts, on the reasoning abilities of MLLMs, demonstrating the different impacts of multimodal inputs in model performance. Unlike traditional benchmarks, which focus primarily on static evaluations, our benchmark will be updated monthly to prevent overfitting and ensure a more authentic and fine-grained evaluation of the models. We believe that this benchmark can aid in understanding and guide the further development of reasoning abilities in MLLMs. The benchmark dataset and code are available at https://github.com/lizhouf/NPHardEval4V
DyVal 2: Dynamic Evaluation of Large Language Models by Meta Probing Agents
Feb 21, 2024Evaluation of large language models (LLMs) has raised great concerns in the community due to the issue of data contamination. Existing work designed evaluation protocols using well-defined algorithms for specific tasks, which cannot be easily extended to diverse scenarios. Moreover, current evaluation benchmarks can only provide the overall benchmark results and cannot support a fine-grained and multifaceted analysis of LLMs' abilities. In this paper, we propose meta probing agents (MPA), a general dynamic evaluation protocol inspired by psychometrics to evaluate LLMs. MPA is the key component of DyVal 2, which naturally extends the previous DyVal~\citep{zhu2023dyval}. MPA designs the probing and judging agents to automatically transform an original evaluation problem into a new one following psychometric theory on three basic cognitive abilities: language understanding, problem solving, and domain knowledge. These basic abilities are also dynamically configurable, allowing multifaceted analysis. We conducted extensive evaluations using MPA and found that most LLMs achieve poorer performance, indicating room for improvement. Our multifaceted analysis demonstrated the strong correlation between the basic abilities and an implicit Matthew effect on model size, i.e., larger models possess stronger correlations of the abilities. MPA can also be used as a data augmentation approach to enhance LLMs.
The Good, The Bad, and Why: Unveiling Emotions in Generative AI
Dec 19, 2023



Emotion significantly impacts our daily behaviors and interactions. While recent generative AI models, such as large language models, have shown impressive performance in various tasks, it remains unclear whether they truly comprehend emotions. This paper aims to address this gap by incorporating psychological theories to gain a holistic understanding of emotions in generative AI models. Specifically, we propose three approaches: 1) EmotionPrompt to enhance AI model performance, 2) EmotionAttack to impair AI model performance, and 3) EmotionDecode to explain the effects of emotional stimuli, both benign and malignant. Through extensive experiments involving language and multi-modal models on semantic understanding, logical reasoning, and generation tasks, we demonstrate that both textual and visual EmotionPrompt can boost the performance of AI models while EmotionAttack can hinder it. Additionally, EmotionDecode reveals that AI models can comprehend emotional stimuli akin to the mechanism of dopamine in the human brain. Our work heralds a novel avenue for exploring psychology to enhance our understanding of generative AI models. This paper is an extended version of our previous work EmotionPrompt (arXiv:2307.11760).
PromptBench: A Unified Library for Evaluation of Large Language Models
Dec 13, 2023The evaluation of large language models (LLMs) is crucial to assess their performance and mitigate potential security risks. In this paper, we introduce PromptBench, a unified library to evaluate LLMs. It consists of several key components that are easily used and extended by researchers: prompt construction, prompt engineering, dataset and model loading, adversarial prompt attack, dynamic evaluation protocols, and analysis tools. PromptBench is designed to be an open, general, and flexible codebase for research purposes that can facilitate original study in creating new benchmarks, deploying downstream applications, and designing new evaluation protocols. The code is available at: https://github.com/microsoft/promptbench and will be continuously supported.
CompeteAI: Understanding the Competition Behaviors in Large Language Model-based Agents
Oct 26, 2023



Large language models (LLMs) have been widely used as agents to complete different tasks, such as personal assistance or event planning. While most work has focused on cooperation and collaboration between agents, little work explores competition, another important mechanism that fosters the development of society and economy. In this paper, we seek to examine the competition behaviors in LLM-based agents. We first propose a general framework to study the competition between agents. Then, we implement a practical competitive environment using GPT-4 to simulate a virtual town with two types of agents, including restaurant agents and customer agents. Specifically, restaurant agents compete with each other to attract more customers, where the competition fosters them to transform, such as cultivating new operating strategies. The results of our experiments reveal several interesting findings ranging from social learning to Matthew Effect, which aligns well with existing sociological and economic theories. We believe that competition between agents deserves further investigation to help us understand society better. The code will be released soon.
DyVal: Graph-informed Dynamic Evaluation of Large Language Models
Oct 05, 2023



Large language models (LLMs) have achieved remarkable performance in various evaluation benchmarks. However, concerns about their performance are raised on potential data contamination in their considerable volume of training corpus. Moreover, the static nature and fixed complexity of current benchmarks may inadequately gauge the advancing capabilities of LLMs. In this paper, we introduce DyVal, a novel, general, and flexible evaluation protocol for dynamic evaluation of LLMs. Based on our proposed dynamic evaluation framework, we build graph-informed DyVal by leveraging the structural advantage of directed acyclic graphs to dynamically generate evaluation samples with controllable complexities. DyVal generates challenging evaluation sets on reasoning tasks including mathematics, logical reasoning, and algorithm problems. We evaluate various LLMs ranging from Flan-T5-large to ChatGPT and GPT4. Experiments demonstrate that LLMs perform worse in DyVal-generated evaluation samples with different complexities, emphasizing the significance of dynamic evaluation. We also analyze the failure cases and results of different prompting methods. Moreover, DyVal-generated samples are not only evaluation sets, but also helpful data for fine-tuning to improve the performance of LLMs on existing benchmarks. We hope that DyVal can shed light on the future evaluation research of LLMs.
EmotionPrompt: Leveraging Psychology for Large Language Models Enhancement via Emotional Stimulus
Aug 01, 2023



Large language models (LLMs) have achieved significant performance in many fields such as reasoning, language understanding, and math problem-solving, and are regarded as a crucial step to artificial general intelligence (AGI). However, the sensitivity of LLMs to prompts remains a major bottleneck for their daily adoption. In this paper, we take inspiration from psychology and propose EmotionPrompt to explore emotional intelligence to enhance the performance of LLMs. EmotionPrompt operates on a remarkably straightforward principle: the incorporation of emotional stimulus into prompts. Experimental results demonstrate that our EmotionPrompt, using the same single prompt templates, significantly outperforms original zero-shot prompt and Zero-shot-CoT on 8 tasks with diverse models: ChatGPT, Vicuna-13b, Bloom, and T5. Further, EmotionPrompt was observed to improve both truthfulness and informativeness. We believe that EmotionPrompt heralds a novel avenue for exploring interdisciplinary knowledge for humans-LLMs interaction.
Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning
Aug 01, 2023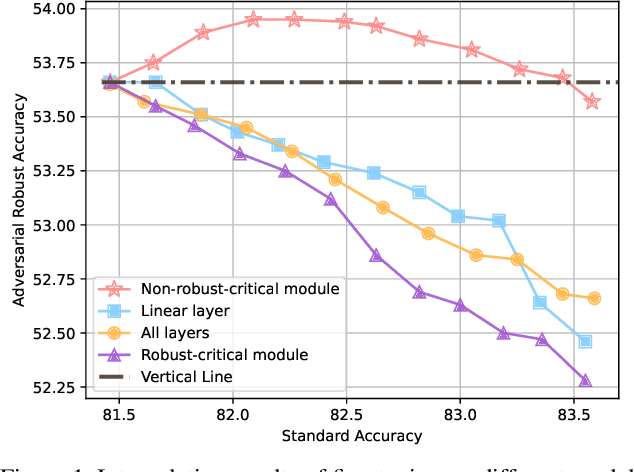
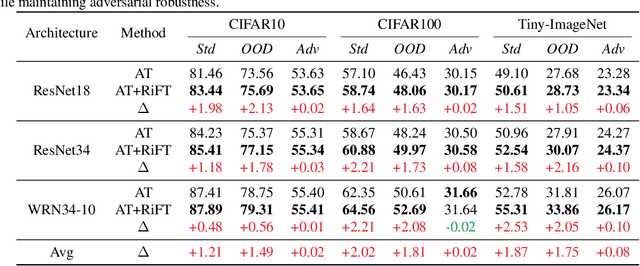
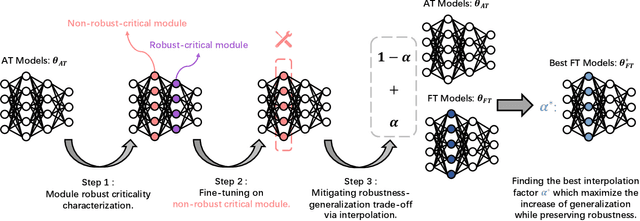

Deep neural networks are susceptible to adversarial examples, posing a significant security risk in critical applications. Adversarial Training (AT) is a well-established technique to enhance adversarial robustness, but it often comes at the cost of decreased generalization ability. This paper proposes Robustness Critical Fine-Tuning (RiFT), a novel approach to enhance generalization without compromising adversarial robustness. The core idea of RiFT is to exploit the redundant capacity for robustness by fine-tuning the adversarially trained model on its non-robust-critical module. To do so, we introduce module robust criticality (MRC), a measure that evaluates the significance of a given module to model robustness under worst-case weight perturbations. Using this measure, we identify the module with the lowest MRC value as the non-robust-critical module and fine-tune its weights to obtain fine-tuned weights. Subsequently, we linearly interpolate between the adversarially trained weights and fine-tuned weights to derive the optimal fine-tuned model weights. We demonstrate the efficacy of RiFT on ResNet18, ResNet34, and WideResNet34-10 models trained on CIFAR10, CIFAR100, and Tiny-ImageNet datasets. Our experiments show that \method can significantly improve both generalization and out-of-distribution robustness by around 1.5% while maintaining or even slightly enhancing adversarial robustness. Code is available at https://github.com/microsoft/robustlearn.
A Survey on Evaluation of Large Language Models
Jul 18, 2023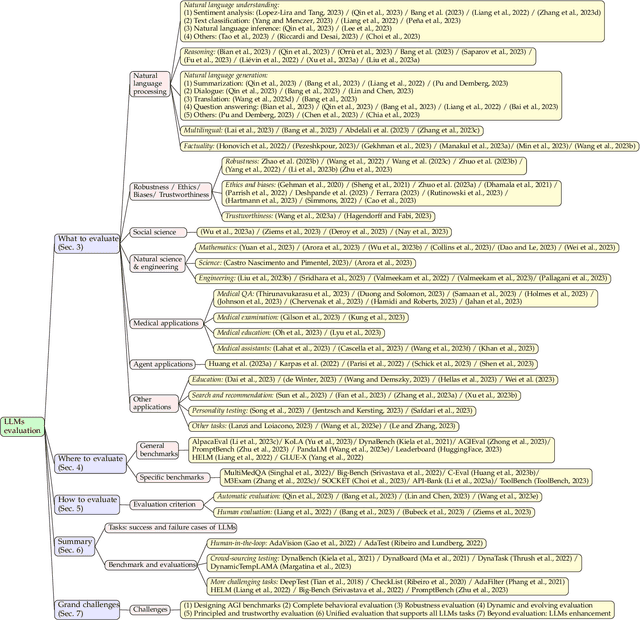
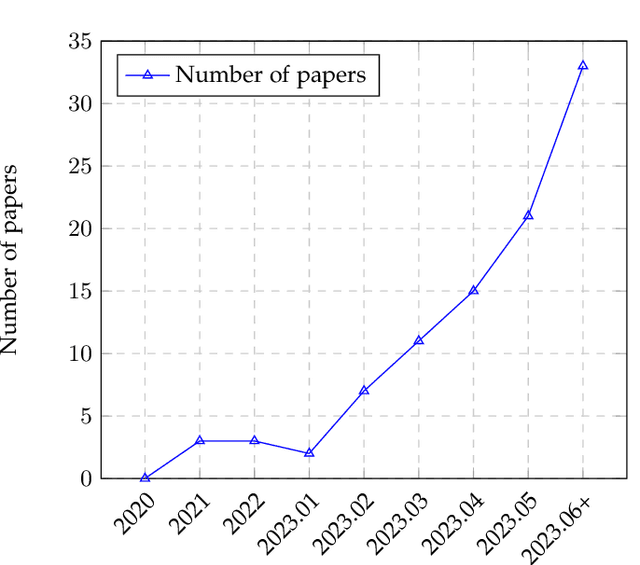
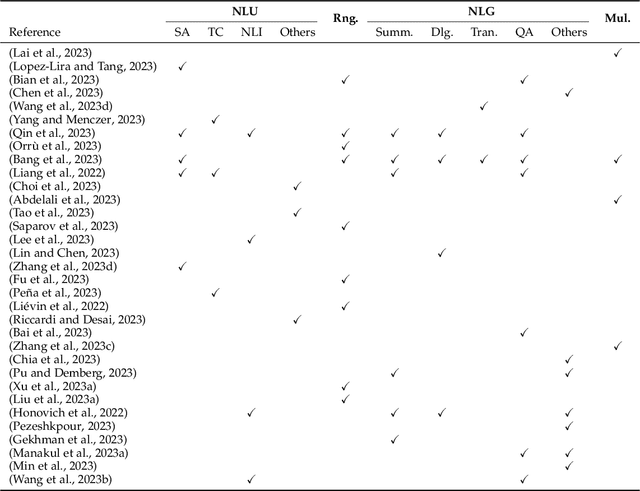
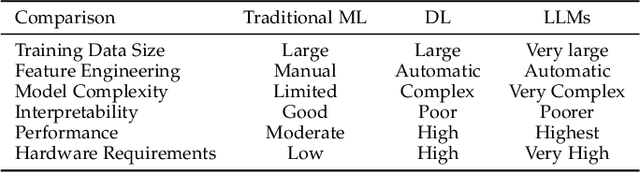
Large language models (LLMs) are gaining increasing popularity in both academia and industry, owing to their unprecedented performance in various applications. As LLMs continue to play a vital role in both research and daily use, their evaluation becomes increasingly critical, not only at the task level, but also at the society level for better understanding of their potential risks. Over the past years, significant efforts have been made to examine LLMs from various perspectives. This paper presents a comprehensive review of these evaluation methods for LLMs, focusing on three key dimensions: what to evaluate, where to evaluate, and how to evaluate. Firstly, we provide an overview from the perspective of evaluation tasks, encompassing general natural language processing tasks, reasoning, medical usage, ethics, educations, natural and social sciences, agent applications, and other areas. Secondly, we answer the `where' and `how' questions by diving into the evaluation methods and benchmarks, which serve as crucial components in assessing performance of LLMs. Then, we summarize the success and failure cases of LLMs in different tasks. Finally, we shed light on several future challenges that lie ahead in LLMs evaluation. Our aim is to offer invaluable insights to researchers in the realm of LLMs evaluation, thereby aiding the development of more proficient LLMs. Our key point is that evaluation should be treated as an essential discipline to better assist the development of LLMs. We consistently maintain the related open-source materials at: https://github.com/MLGroupJLU/LLM-eval-survey.
PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts
Jun 13, 2023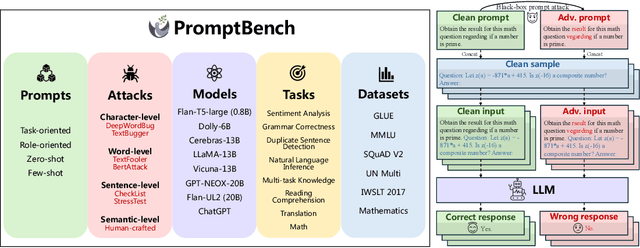
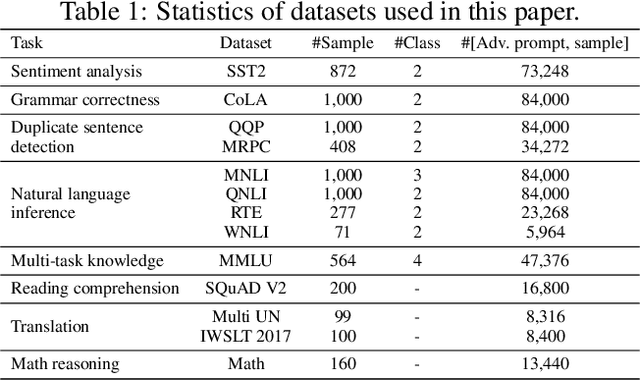
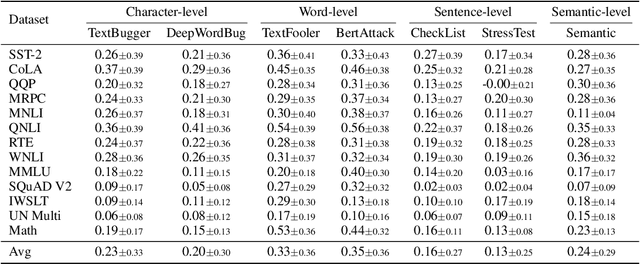

The increasing reliance on Large Language Models (LLMs) across academia and industry necessitates a comprehensive understanding of their robustness to prompts. In response to this vital need, we introduce PromptBench, a robustness benchmark designed to measure LLMs' resilience to adversarial prompts. This study uses a plethora of adversarial textual attacks targeting prompts across multiple levels: character, word, sentence, and semantic. These prompts are then employed in diverse tasks, such as sentiment analysis, natural language inference, reading comprehension, machine translation, and math problem-solving. Our study generates 4,032 adversarial prompts, meticulously evaluated over 8 tasks and 13 datasets, with 567,084 test samples in total. Our findings demonstrate that contemporary LLMs are vulnerable to adversarial prompts. Furthermore, we present comprehensive analysis to understand the mystery behind prompt robustness and its transferability. We then offer insightful robustness analysis and pragmatic recommendations for prompt composition, beneficial to both researchers and everyday users. We make our code, prompts, and methodologies to generate adversarial prompts publicly accessible, thereby enabling and encouraging collaborative exploration in this pivotal field: https://github.com/microsoft/promptbench.