 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMT-Bench: A Comprehensive Multimodal Benchmark for Evaluating Large Vision-Language Models Towards Multitask AGI
Apr 24, 2024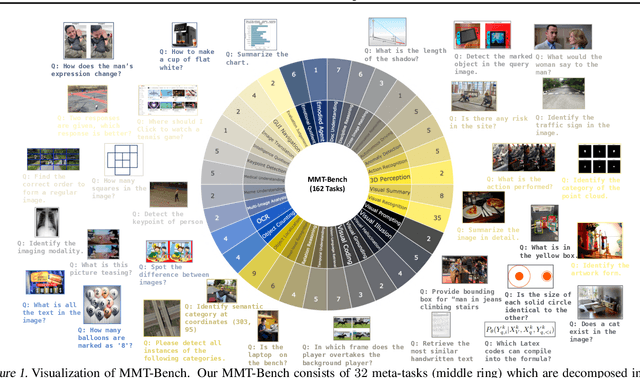

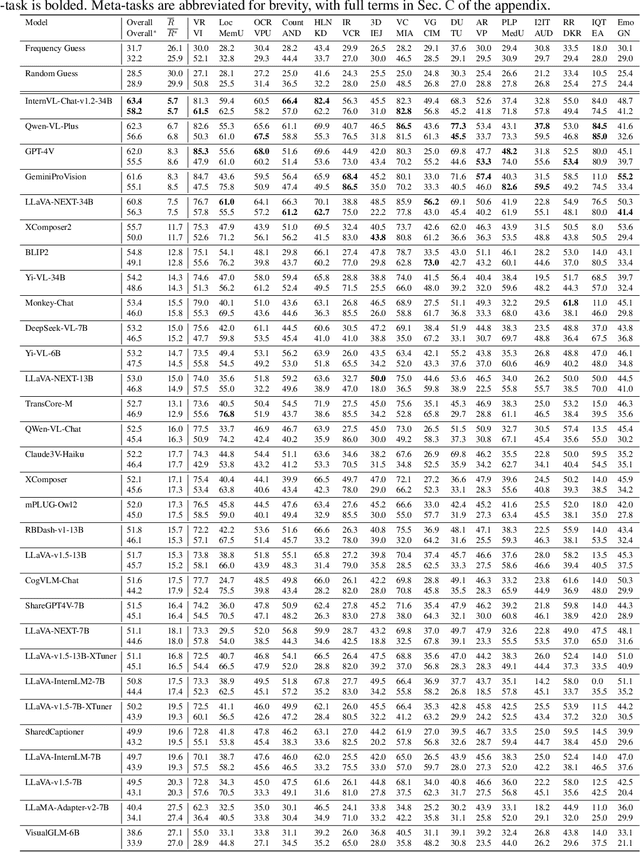
Large Vision-Language Models (LVLMs) show significant strides in general-purpose multimodal applications such as visual dialogue and embodied navigation. However, existing multimodal evaluation benchmarks cover a limited number of multimodal tasks testing rudimentary capabilities, falling short in tracking LVLM development. In this study, we present MMT-Bench, a comprehensive benchmark designed to assess LVLMs across massive multimodal tasks requiring expert knowledge and deliberate visual recognition, localization, reasoning, and planning. MMT-Bench comprises $31,325$ meticulously curated multi-choice visual questions from various multimodal scenarios such as vehicle driving and embodied navigation, covering $32$ core meta-tasks and $162$ subtasks in multimodal understanding. Due to its extensive task coverage, MMT-Bench enables the evaluation of LVLMs using a task map, facilitating the discovery of in- and out-of-domain tasks. Evaluation results involving $30$ LVLMs such as the proprietary GPT-4V, GeminiProVision, and open-sourced InternVL-Chat, underscore the significant challenges posed by MMT-Bench. We anticipate that MMT-Bench will inspire the community to develop next-generation multimodal foundation models aimed at achieving general-purpose multimodal intelligence.
CTVIS: Consistent Training for Online Video Instance Segmentation
Jul 24, 2023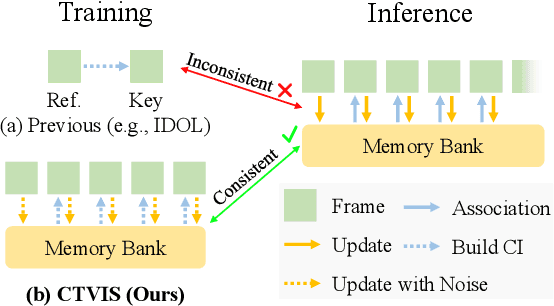
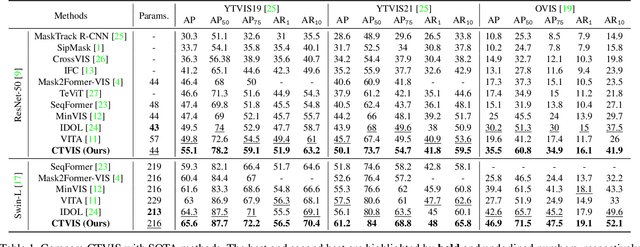
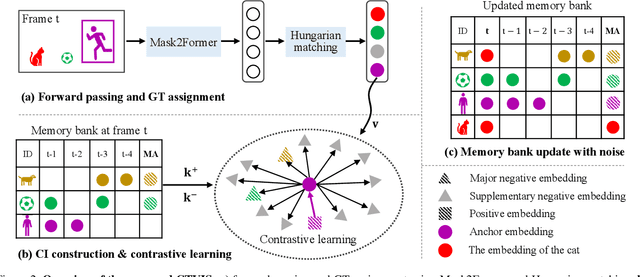
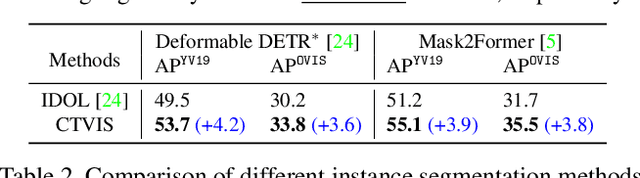
The discrimination of instance embeddings plays a vital role in associating instances across time for online video instance segmentation (VIS). Instance embedding learning is directly supervised by the contrastive loss computed upon the contrastive items (CIs), which are sets of anchor/positive/negative embeddings. Recent online VIS methods leverage CIs sourced from one reference frame only, which we argue is insufficient for learning highly discriminative embeddings. Intuitively, a possible strategy to enhance CIs is replicating the inference phase during training. To this end, we propose a simple yet effective training strategy, called Consistent Training for Online VIS (CTVIS), which devotes to aligning the training and inference pipelines in terms of building CIs. Specifically, CTVIS constructs CIs by referring inference the momentum-averaged embedding and the memory bank storage mechanisms, and adding noise to the relevant embeddings. Such an extension allows a reliable comparison between embeddings of current instances and the stable representations of historical instances, thereby conferring an advantage in modeling VIS challenges such as occlusion, re-identification, and deformation. Empirically, CTVIS outstrips the SOTA VIS models by up to +5.0 points on three VIS benchmarks, including YTVIS19 (55.1% AP), YTVIS21 (50.1% AP) and OVIS (35.5% AP). Furthermore, we find that pseudo-videos transformed from images can train robust models surpassing fully-supervised ones.
Human-to-Human Interaction Detection
Jul 02, 2023



A comprehensive understanding of interested human-to-human interactions in video streams, such as queuing, handshaking, fighting and chasing, is of immense importance to the surveillance of public security in regions like campuses, squares and parks. Different from conventional human interaction recognition, which uses choreographed videos as inputs, neglects concurrent interactive groups, and performs detection and recognition in separate stages, we introduce a new task named human-to-human interaction detection (HID). HID devotes to detecting subjects, recognizing person-wise actions, and grouping people according to their interactive relations, in one model. First, based on the popular AVA dataset created for action detection, we establish a new HID benchmark, termed AVA-Interaction (AVA-I), by adding annotations on interactive relations in a frame-by-frame manner. AVA-I consists of 85,254 frames and 86,338 interactive groups, and each image includes up to 4 concurrent interactive groups. Second, we present a novel baseline approach SaMFormer for HID, containing a visual feature extractor, a split stage which leverages a Transformer-based model to decode action instances and interactive groups, and a merging stage which reconstructs the relationship between instances and groups. All SaMFormer components are jointly trained in an end-to-end manner. Extensive experiments on AVA-I validate the superiority of SaMFormer over representative methods. The dataset and code will be made public to encourage more follow-up studies.
ISDA: Position-Aware Instance Segmentation with Deformable Attention
Feb 23, 2022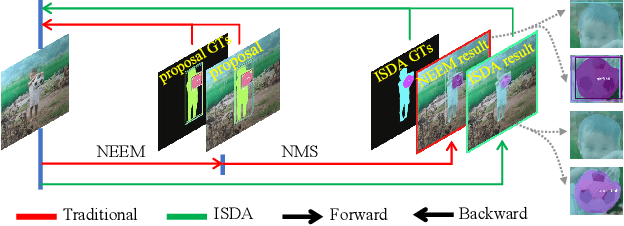
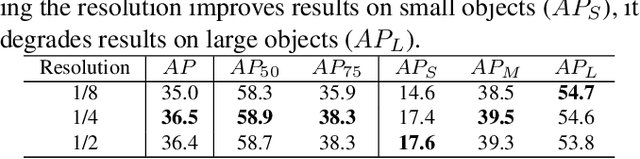
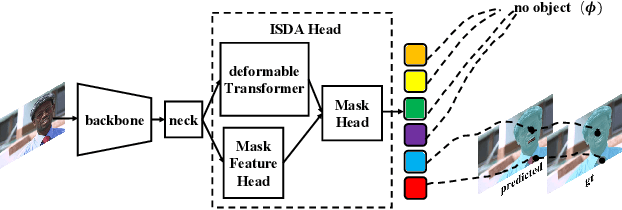
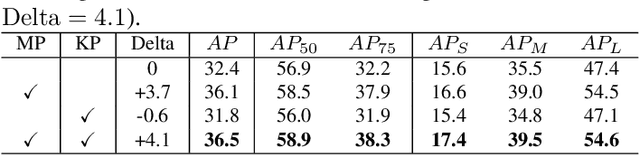
Most instance segmentation models are not end-to-end trainable due to either the incorporation of proposal estimation (RPN) as a pre-processing or non-maximum suppression (NMS) as a post-processing. Here we propose a novel end-to-end instance segmentation method termed ISDA. It reshapes the task into predicting a set of object masks, which are generated via traditional convolution operation with learned position-aware kernels and features of objects. Such kernels and features are learned by leveraging a deformable attention network with multi-scale representation. Thanks to the introduced set-prediction mechanism, the proposed method is NMS-free. Empirically, ISDA outperforms Mask R-CNN (the strong baseline) by 2.6 points on MS-COCO, and achieves leading performance compared with recent models. Code will be available soon.