 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving
May 27, 2024Recent advancements in bird's eye view (BEV) representations have shown remarkable promise for in-vehicle 3D perception. However, while these methods have achieved impressive results on standard benchmarks, their robustness in varied conditions remains insufficiently assessed. In this study, we present RoboBEV, an extensive benchmark suite designed to evaluate the resilience of BEV algorithms. This suite incorporates a diverse set of camera corruption types, each examined over three severity levels. Our benchmarks also consider the impact of complete sensor failures that occur when using multi-modal models. Through RoboBEV, we assess 33 state-of-the-art BEV-based perception models spanning tasks like detection, map segmentation, depth estimation, and occupancy prediction. Our analyses reveal a noticeable correlation between the model's performance on in-distribution datasets and its resilience to out-of-distribution challenges. Our experimental results also underline the efficacy of strategies like pre-training and depth-free BEV transformations in enhancing robustness against out-of-distribution data. Furthermore, we observe that leveraging extensive temporal information significantly improves the model's robustness. Based on our observations, we design an effective robustness enhancement strategy based on the CLIP model. The insights from this study pave the way for the development of future BEV models that seamlessly combine accuracy with real-world robustness.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
DiffTF++: 3D-aware Diffusion Transformer for Large-Vocabulary 3D Generation
May 13, 2024Generating diverse and high-quality 3D assets automatically poses a fundamental yet challenging task in 3D computer vision. Despite extensive efforts in 3D generation, existing optimization-based approaches struggle to produce large-scale 3D assets efficiently. Meanwhile, feed-forward methods often focus on generating only a single category or a few categories, limiting their generalizability. Therefore, we introduce a diffusion-based feed-forward framework to address these challenges with a single model. To handle the large diversity and complexity in geometry and texture across categories efficiently, we 1) adopt improved triplane to guarantee efficiency; 2) introduce the 3D-aware transformer to aggregate the generalized 3D knowledge with specialized 3D features; and 3) devise the 3D-aware encoder/decoder to enhance the generalized 3D knowledge. Building upon our 3D-aware Diffusion model with TransFormer, DiffTF, we propose a stronger version for 3D generation, i.e., DiffTF++. It boils down to two parts: multi-view reconstruction loss and triplane refinement. Specifically, we utilize multi-view reconstruction loss to fine-tune the diffusion model and triplane decoder, thereby avoiding the negative influence caused by reconstruction errors and improving texture synthesis. By eliminating the mismatch between the two stages, the generative performance is enhanced, especially in texture. Additionally, a 3D-aware refinement process is introduced to filter out artifacts and refine triplanes, resulting in the generation of more intricate and reasonable details. Extensive experiments on ShapeNet and OmniObject3D convincingly demonstrate the effectiveness of our proposed modules and the state-of-the-art 3D object generation performance with large diversity, rich semantics, and high quality.
Multi-Modal Data-Efficient 3D Scene Understanding for Autonomous Driving
May 08, 2024Efficient data utilization is crucial for advancing 3D scene understanding in autonomous driving, where reliance on heavily human-annotated LiDAR point clouds challenges fully supervised methods. Addressing this, our study extends into semi-supervised learning for LiDAR semantic segmentation, leveraging the intrinsic spatial priors of driving scenes and multi-sensor complements to augment the efficacy of unlabeled datasets. We introduce LaserMix++, an evolved framework that integrates laser beam manipulations from disparate LiDAR scans and incorporates LiDAR-camera correspondences to further assist data-efficient learning. Our framework is tailored to enhance 3D scene consistency regularization by incorporating multi-modality, including 1) multi-modal LaserMix operation for fine-grained cross-sensor interactions; 2) camera-to-LiDAR feature distillation that enhances LiDAR feature learning; and 3) language-driven knowledge guidance generating auxiliary supervisions using open-vocabulary models. The versatility of LaserMix++ enables applications across LiDAR representations, establishing it as a universally applicable solution. Our framework is rigorously validated through theoretical analysis and extensive experiments on popular driving perception datasets. Results demonstrate that LaserMix++ markedly outperforms fully supervised alternatives, achieving comparable accuracy with five times fewer annotations and significantly improving the supervised-only baselines. This substantial advancement underscores the potential of semi-supervised approaches in reducing the reliance on extensive labeled data in LiDAR-based 3D scene understanding systems.
Multi-Space Alignments Towards Universal LiDAR Segmentation
May 02, 2024A unified and versatile LiDAR segmentation model with strong robustness and generalizability is desirable for safe autonomous driving perception. This work presents M3Net, a one-of-a-kind framework for fulfilling multi-task, multi-dataset, multi-modality LiDAR segmentation in a universal manner using just a single set of parameters. To better exploit data volume and diversity, we first combine large-scale driving datasets acquired by different types of sensors from diverse scenes and then conduct alignments in three spaces, namely data, feature, and label spaces, during the training. As a result, M3Net is capable of taming heterogeneous data for training state-of-the-art LiDAR segmentation models. Extensive experiments on twelve LiDAR segmentation datasets verify our effectiveness. Notably, using a shared set of parameters, M3Net achieves 75.1%, 83.1%, and 72.4% mIoU scores, respectively, on the official benchmarks of SemanticKITTI, nuScenes, and Waymo Open.
Closely Interactive Human Reconstruction with Proxemics and Physics-Guided Adaption
Apr 17, 2024Existing multi-person human reconstruction approaches mainly focus on recovering accurate poses or avoiding penetration, but overlook the modeling of close interactions. In this work, we tackle the task of reconstructing closely interactive humans from a monocular video. The main challenge of this task comes from insufficient visual information caused by depth ambiguity and severe inter-person occlusion. In view of this, we propose to leverage knowledge from proxemic behavior and physics to compensate the lack of visual information. This is based on the observation that human interaction has specific patterns following the social proxemics. Specifically, we first design a latent representation based on Vector Quantised-Variational AutoEncoder (VQ-VAE) to model human interaction. A proxemics and physics guided diffusion model is then introduced to denoise the initial distribution. We design the diffusion model as dual branch with each branch representing one individual such that the interaction can be modeled via cross attention. With the learned priors of VQ-VAE and physical constraint as the additional information, our proposed approach is capable of estimating accurate poses that are also proxemics and physics plausible. Experimental results on Hi4D, 3DPW, and CHI3D demonstrate that our method outperforms existing approaches. The code is available at \url{https://github.com/boycehbz/HumanInteraction}.
Calib3D: Calibrating Model Preferences for Reliable 3D Scene Understanding
Mar 25, 2024Safety-critical 3D scene understanding tasks necessitate not only accurate but also confident predictions from 3D perception models. This study introduces Calib3D, a pioneering effort to benchmark and scrutinize the reliability of 3D scene understanding models from an uncertainty estimation viewpoint. We comprehensively evaluate 28 state-of-the-art models across 10 diverse 3D datasets, uncovering insightful phenomena that cope with both the aleatoric and epistemic uncertainties in 3D scene understanding. We discover that despite achieving impressive levels of accuracy, existing models frequently fail to provide reliable uncertainty estimates -- a pitfall that critically undermines their applicability in safety-sensitive contexts. Through extensive analysis of key factors such as network capacity, LiDAR representations, rasterization resolutions, and 3D data augmentation techniques, we correlate these aspects directly with the model calibration efficacy. Furthermore, we introduce DeptS, a novel depth-aware scaling approach aimed at enhancing 3D model calibration. Extensive experiments across a wide range of configurations validate the superiority of our method. We hope this work could serve as a cornerstone for fostering reliable 3D scene understanding. Code and benchmark toolkits are publicly available.
3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors
Mar 04, 2024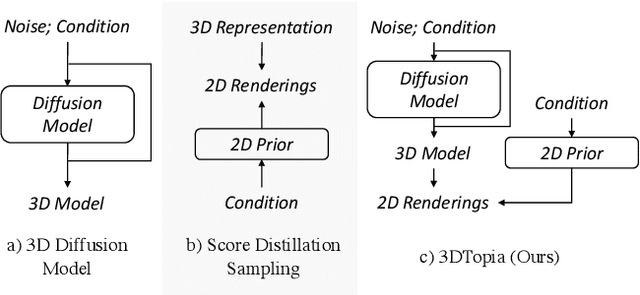

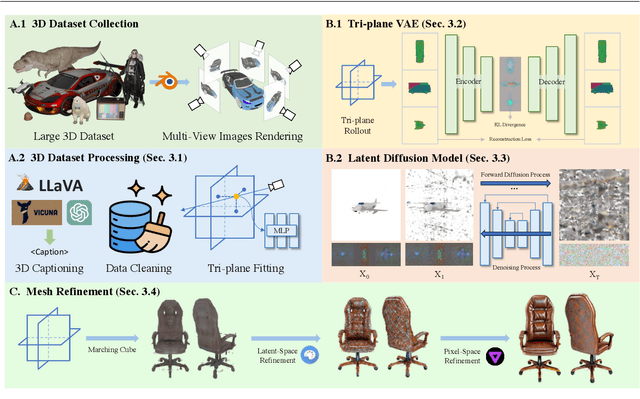
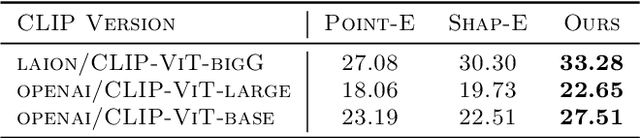
We present a two-stage text-to-3D generation system, namely 3DTopia, which generates high-quality general 3D assets within 5 minutes using hybrid diffusion priors. The first stage samples from a 3D diffusion prior directly learned from 3D data. Specifically, it is powered by a text-conditioned tri-plane latent diffusion model, which quickly generates coarse 3D samples for fast prototyping. The second stage utilizes 2D diffusion priors to further refine the texture of coarse 3D models from the first stage. The refinement consists of both latent and pixel space optimization for high-quality texture generation. To facilitate the training of the proposed system, we clean and caption the largest open-source 3D dataset, Objaverse, by combining the power of vision language models and large language models. Experiment results are reported qualitatively and quantitatively to show the performance of the proposed system. Our codes and models are available at https://github.com/3DTopia/3DTopia
Exploiting Hierarchical Interactions for Protein Surface Learning
Jan 17, 2024Predicting interactions between proteins is one of the most important yet challenging problems in structural bioinformatics. Intrinsically, potential function sites in protein surfaces are determined by both geometric and chemical features. However, existing works only consider handcrafted or individually learned chemical features from the atom type and extract geometric features independently. Here, we identify two key properties of effective protein surface learning: 1) relationship among atoms: atoms are linked with each other by covalent bonds to form biomolecules instead of appearing alone, leading to the significance of modeling the relationship among atoms in chemical feature learning. 2) hierarchical feature interaction: the neighboring residue effect validates the significance of hierarchical feature interaction among atoms and between surface points and atoms (or residues). In this paper, we present a principled framework based on deep learning techniques, namely Hierarchical Chemical and Geometric Feature Interaction Network (HCGNet), for protein surface analysis by bridging chemical and geometric features with hierarchical interactions. Extensive experiments demonstrate that our method outperforms the prior state-of-the-art method by 2.3% in site prediction task and 3.2% in interaction matching task, respectively. Our code is available at https://github.com/xmed-lab/HCGNet.
DreamGaussian4D: Generative 4D Gaussian Splatting
Dec 29, 2023Remarkable progress has been made in 4D content generation recently. However, existing methods suffer from long optimization time, lack of motion controllability, and a low level of detail. In this paper, we introduce DreamGaussian4D, an efficient 4D generation framework that builds on 4D Gaussian Splatting representation. Our key insight is that the explicit modeling of spatial transformations in Gaussian Splatting makes it more suitable for the 4D generation setting compared with implicit representations. DreamGaussian4D reduces the optimization time from several hours to just a few minutes, allows flexible control of the generated 3D motion, and produces animated meshes that can be efficiently rendered in 3D engines.