 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending Fusion: A Multi-Scale Alignment Method for Remote Sensing Image-Text Retrieval
May 29, 2024Remote Sensing Image-Text Retrieval (RSITR) is pivotal for knowledge services and data mining in the remote sensing (RS) domain. Considering the multi-scale representations in image content and text vocabulary can enable the models to learn richer representations and enhance retrieval. Current multi-scale RSITR approaches typically align multi-scale fused image features with text features, but overlook aligning image-text pairs at distinct scales separately. This oversight restricts their ability to learn joint representations suitable for effective retrieval. We introduce a novel Multi-Scale Alignment (MSA) method to overcome this limitation. Our method comprises three key innovations: (1) Multi-scale Cross-Modal Alignment Transformer (MSCMAT), which computes cross-attention between single-scale image features and localized text features, integrating global textual context to derive a matching score matrix within a mini-batch, (2) a multi-scale cross-modal semantic alignment loss that enforces semantic alignment across scales, and (3) a cross-scale multi-modal semantic consistency loss that uses the matching matrix from the largest scale to guide alignment at smaller scales. We evaluated our method across multiple datasets, demonstrating its efficacy with various visual backbones and establishing its superiority over existing state-of-the-art methods. The GitHub URL for our project is: https://github.com/yr666666/MSA
Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing
May 07, 2024Existing diffusion-based video editing methods have achieved impressive results in motion editing. Most of the existing methods focus on the motion alignment between the edited video and the reference video. However, these methods do not constrain the background and object content of the video to remain unchanged, which makes it possible for users to generate unexpected videos. In this paper, we propose a one-shot video motion editing method called Edit-Your-Motion that requires only a single text-video pair for training. Specifically, we design the Detailed Prompt-Guided Learning Strategy (DPL) to decouple spatio-temporal features in space-time diffusion models. DPL separates learning object content and motion into two training stages. In the first training stage, we focus on learning the spatial features (the features of object content) and breaking down the temporal relationships in the video frames by shuffling them. We further propose Recurrent-Causal Attention (RC-Attn) to learn the consistent content features of the object from unordered video frames. In the second training stage, we restore the temporal relationship in video frames to learn the temporal feature (the features of the background and object's motion). We also adopt the Noise Constraint Loss to smooth out inter-frame differences. Finally, in the inference stage, we inject the content features of the source object into the editing branch through a two-branch structure (editing branch and reconstruction branch). With Edit-Your-Motion, users can edit the motion of objects in the source video to generate more exciting and diverse videos. Comprehensive qualitative experiments, quantitative experiments and user preference studies demonstrate that Edit-Your-Motion performs better than other methods.
S$^2$Mamba: A Spatial-spectral State Space Model for Hyperspectral Image Classification
Apr 28, 2024Land cover analysis using hyperspectral images (HSI) remains an open problem due to their low spatial resolution and complex spectral information. Recent studies are primarily dedicated to designing Transformer-based architectures for spatial-spectral long-range dependencies modeling, which is computationally expensive with quadratic complexity. Selective structured state space model (Mamba), which is efficient for modeling long-range dependencies with linear complexity, has recently shown promising progress. However, its potential in hyperspectral image processing that requires handling numerous spectral bands has not yet been explored. In this paper, we innovatively propose S$^2$Mamba, a spatial-spectral state space model for hyperspectral image classification, to excavate spatial-spectral contextual features, resulting in more efficient and accurate land cover analysis. In S$^2$Mamba, two selective structured state space models through different dimensions are designed for feature extraction, one for spatial, and the other for spectral, along with a spatial-spectral mixture gate for optimal fusion. More specifically, S$^2$Mamba first captures spatial contextual relations by interacting each pixel with its adjacent through a Patch Cross Scanning module and then explores semantic information from continuous spectral bands through a Bi-directional Spectral Scanning module. Considering the distinct expertise of the two attributes in homogenous and complicated texture scenes, we realize the Spatial-spectral Mixture Gate by a group of learnable matrices, allowing for the adaptive incorporation of representations learned across different dimensions. Extensive experiments conducted on HSI classification benchmarks demonstrate the superiority and prospect of S$^2$Mamba. The code will be available at: https://github.com/PURE-melo/S2Mamba.
Exploring Beyond Logits: Hierarchical Dynamic Labeling Based on Embeddings for Semi-Supervised Classification
Apr 26, 2024In semi-supervised learning, methods that rely on confidence learning to generate pseudo-labels have been widely proposed. However, increasing research finds that when faced with noisy and biased data, the model's representation network is more reliable than the classification network. Additionally, label generation methods based on model predictions often show poor adaptability across different datasets, necessitating customization of the classification network. Therefore, we propose a Hierarchical Dynamic Labeling (HDL) algorithm that does not depend on model predictions and utilizes image embeddings to generate sample labels. We also introduce an adaptive method for selecting hyperparameters in HDL, enhancing its versatility. Moreover, HDL can be combined with general image encoders (e.g., CLIP) to serve as a fundamental data processing module. We extract embeddings from datasets with class-balanced and long-tailed distributions using pre-trained semi-supervised models. Subsequently, samples are re-labeled using HDL, and the re-labeled samples are used to further train the semi-supervised models. Experiments demonstrate improved model performance, validating the motivation that representation networks are more reliable than classifiers or predictors. Our approach has the potential to change the paradigm of pseudo-label generation in semi-supervised learning.
Unveiling and Mitigating Generalized Biases of DNNs through the Intrinsic Dimensions of Perceptual Manifolds
Apr 22, 2024Building fair deep neural networks (DNNs) is a crucial step towards achieving trustworthy artificial intelligence. Delving into deeper factors that affect the fairness of DNNs is paramount and serves as the foundation for mitigating model biases. However, current methods are limited in accurately predicting DNN biases, relying solely on the number of training samples and lacking more precise measurement tools. Here, we establish a geometric perspective for analyzing the fairness of DNNs, comprehensively exploring how DNNs internally shape the intrinsic geometric characteristics of datasets-the intrinsic dimensions (IDs) of perceptual manifolds, and the impact of IDs on the fairness of DNNs. Based on multiple findings, we propose Intrinsic Dimension Regularization (IDR), which enhances the fairness and performance of models by promoting the learning of concise and ID-balanced class perceptual manifolds. In various image recognition benchmark tests, IDR significantly mitigates model bias while improving its performance.
SA-MixNet: Structure-aware Mixup and Invariance Learning for Scribble-supervised Road Extraction in Remote Sensing Images
Mar 03, 2024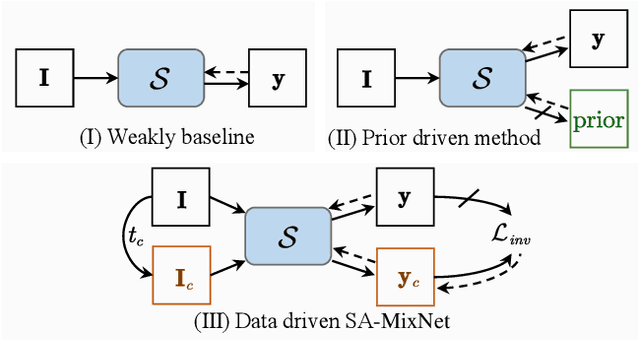
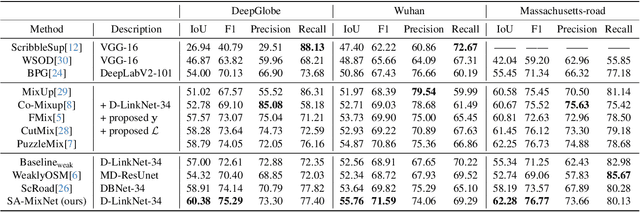
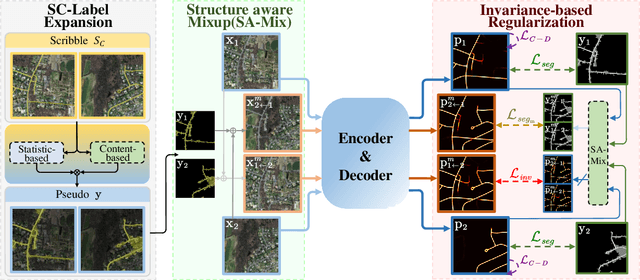
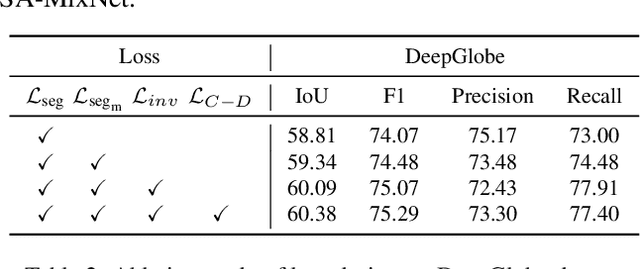
Mainstreamed weakly supervised road extractors rely on highly confident pseudo-labels propagated from scribbles, and their performance often degrades gradually as the image scenes tend various. We argue that such degradation is due to the poor model's invariance to scenes with different complexities, whereas existing solutions to this problem are commonly based on crafted priors that cannot be derived from scribbles. To eliminate the reliance on such priors, we propose a novel Structure-aware Mixup and Invariance Learning framework (SA-MixNet) for weakly supervised road extraction that improves the model invariance in a data-driven manner. Specifically, we design a structure-aware Mixup scheme to paste road regions from one image onto another for creating an image scene with increased complexity while preserving the road's structural integrity. Then an invariance regularization is imposed on the predictions of constructed and origin images to minimize their conflicts, which thus forces the model to behave consistently on various scenes. Moreover, a discriminator-based regularization is designed for enhancing the connectivity meanwhile preserving the structure of roads. Combining these designs, our framework demonstrates superior performance on the DeepGlobe, Wuhan, and Massachusetts datasets outperforming the state-of-the-art techniques by 1.47%, 2.12%, 4.09% respectively in IoU metrics, and showing its potential of plug-and-play. The code will be made publicly available.
Geometric Prior Guided Feature Representation Learning for Long-Tailed Classification
Jan 21, 2024Real-world data are long-tailed, the lack of tail samples leads to a significant limitation in the generalization ability of the model. Although numerous approaches of class re-balancing perform well for moderate class imbalance problems, additional knowledge needs to be introduced to help the tail class recover the underlying true distribution when the observed distribution from a few tail samples does not represent its true distribution properly, thus allowing the model to learn valuable information outside the observed domain. In this work, we propose to leverage the geometric information of the feature distribution of the well-represented head class to guide the model to learn the underlying distribution of the tail class. Specifically, we first systematically define the geometry of the feature distribution and the similarity measures between the geometries, and discover four phenomena regarding the relationship between the geometries of different feature distributions. Then, based on four phenomena, feature uncertainty representation is proposed to perturb the tail features by utilizing the geometry of the head class feature distribution. It aims to make the perturbed features cover the underlying distribution of the tail class as much as possible, thus improving the model's generalization performance in the test domain. Finally, we design a three-stage training scheme enabling feature uncertainty modeling to be successfully applied. Experiments on CIFAR-10/100-LT, ImageNet-LT, and iNaturalist2018 show that our proposed approach outperforms other similar methods on most metrics. In addition, the experimental phenomena we discovered are able to provide new perspectives and theoretical foundations for subsequent studies.
A match made in consistency heaven: when large language models meet evolutionary algorithms
Jan 19, 2024Pre-trained large language models (LLMs) have powerful capabilities for generating creative natural text. Evolutionary algorithms (EAs) can discover diverse solutions to complex real-world problems. Motivated by the common collective and directionality of text sequence generation and evolution, this paper illustrates the strong consistency of LLMs and EAs, which includes multiple one-to-one key characteristics: token embedding and genotype-phenotype mapping, position encoding and fitness shaping, position embedding and selection, attention and crossover, feed-forward neural network and mutation, model training and parameter update, and multi-task learning and multi-objective optimization. Based on this consistency perspective, existing coupling studies are analyzed, including evolutionary fine-tuning and LLM-enhanced EAs. Leveraging these insights, we outline a fundamental roadmap for future research in coupling LLMs and EAs, while highlighting key challenges along the way. The consistency not only reveals the evolution mechanism behind LLMs but also facilitates the development of evolved artificial agents that approach or surpass biological organisms.
Transferring Modality-Aware Pedestrian Attentive Learning for Visible-Infrared Person Re-identification
Dec 19, 2023Visible-infrared person re-identification (VI-ReID) aims to search the same pedestrian of interest across visible and infrared modalities. Existing models mainly focus on compensating for modality-specific information to reduce modality variation. However, these methods often lead to a higher computational overhead and may introduce interfering information when generating the corresponding images or features. To address this issue, it is critical to leverage pedestrian-attentive features and learn modality-complete and -consistent representation. In this paper, a novel Transferring Modality-Aware Pedestrian Attentive Learning (TMPA) model is proposed, focusing on the pedestrian regions to efficiently compensate for missing modality-specific features. Specifically, we propose a region-based data augmentation module PedMix to enhance pedestrian region coherence by mixing the corresponding regions from different modalities. A lightweight hybrid compensation module, i.e., the Modality Feature Transfer (MFT), is devised to integrate cross attention and convolution networks to fully explore the discriminative modality-complete features with minimal computational overhead. Extensive experiments conducted on the benchmark SYSU-MM01 and RegDB datasets demonstrated the effectiveness of our proposed TMPA model.
Semantic Connectivity-Driven Pseudo-labeling for Cross-domain Segmentation
Dec 11, 2023Presently, self-training stands as a prevailing approach in cross-domain semantic segmentation, enhancing model efficacy by training with pixels assigned with reliable pseudo-labels. However, we find two critical limitations in this paradigm. (1) The majority of reliable pixels exhibit a speckle-shaped pattern and are primarily located in the central semantic region. This presents challenges for the model in accurately learning semantics. (2) Category noise in speckle pixels is difficult to locate and correct, leading to error accumulation in self-training. To address these limitations, we propose a novel approach called Semantic Connectivity-driven pseudo-labeling (SeCo). This approach formulates pseudo-labels at the connectivity level and thus can facilitate learning structured and low-noise semantics. Specifically, SeCo comprises two key components: Pixel Semantic Aggregation (PSA) and Semantic Connectivity Correction (SCC). Initially, PSA divides semantics into 'stuff' and 'things' categories and aggregates speckled pseudo-labels into semantic connectivity through efficient interaction with the Segment Anything Model (SAM). This enables us not only to obtain accurate boundaries but also simplifies noise localization. Subsequently, SCC introduces a simple connectivity classification task, which enables locating and correcting connectivity noise with the guidance of loss distribution. Extensive experiments demonstrate that SeCo can be flexibly applied to various cross-domain semantic segmentation tasks, including traditional unsupervised, source-free, and black-box domain adaptation, significantly improving the performance of existing state-of-the-art methods. The code is available at https://github.com/DZhaoXd/SeCo.