 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMini Honor of Kings: A Lightweight Environment for Multi-Agent Reinforcement Learning
Jun 06, 2024Games are widely used as research environments for multi-agent reinforcement learning (MARL), but they pose three significant challenges: limited customization, high computational demands, and oversimplification. To address these issues, we introduce the first publicly available map editor for the popular mobile game Honor of Kings and design a lightweight environment, Mini Honor of Kings (Mini HoK), for researchers to conduct experiments. Mini HoK is highly efficient, allowing experiments to be run on personal PCs or laptops while still presenting sufficient challenges for existing MARL algorithms. We have tested our environment on common MARL algorithms and demonstrated that these algorithms have yet to find optimal solutions within this environment. This facilitates the dissemination and advancement of MARL methods within the research community. Additionally, we hope that more researchers will leverage the Honor of Kings map editor to develop innovative and scientifically valuable new maps. Our code and user manual are available at: https://github.com/tencent-ailab/mini-hok.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
ContrastAlign: Toward Robust BEV Feature Alignment via Contrastive Learning for Multi-Modal 3D Object Detection
May 27, 2024In the field of 3D object detection tasks, fusing heterogeneous features from LiDAR and camera sensors into a unified Bird's Eye View (BEV) representation is a widely adopted paradigm. However, existing methods are often compromised by imprecise sensor calibration, resulting in feature misalignment in LiDAR-camera BEV fusion. Moreover, such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a novel ContrastAlign approach that utilizes contrastive learning to enhance the alignment of heterogeneous modalities, thereby improving the robustness of the fusion process. Specifically, our approach includes the L-Instance module, which directly outputs LiDAR instance features within LiDAR BEV features. Then, we introduce the C-Instance module, which predicts camera instance features through RoI (Region of Interest) pooling on the camera BEV features. We propose the InstanceFusion module, which utilizes contrastive learning to generate similar instance features across heterogeneous modalities. We then use graph matching to calculate the similarity between the neighboring camera instance features and the similarity instance features to complete the alignment of instance features. Our method achieves state-of-the-art performance, with an mAP of 70.3%, surpassing BEVFusion by 1.8% on the nuScenes validation set. Importantly, our method outperforms BEVFusion by 7.3% under conditions with misalignment noise.
A Preference-oriented Diversity Model Based on Mutual-information in Re-ranking for E-commerce Search
May 24, 2024Re-ranking is a process of rearranging ranking list to more effectively meet user demands by accounting for the interrelationships between items. Existing methods predominantly enhance the precision of search results, often at the expense of diversity, leading to outcomes that may not fulfill the varied needs of users. Conversely, methods designed to promote diversity might compromise the precision of the results, failing to satisfy the users' requirements for accuracy. To alleviate the above problems, this paper proposes a Preference-oriented Diversity Model Based on Mutual-information (PODM-MI), which consider both accuracy and diversity in the re-ranking process. Specifically, PODM-MI adopts Multidimensional Gaussian distributions based on variational inference to capture users' diversity preferences with uncertainty. Then we maximize the mutual information between the diversity preferences of the users and the candidate items using the maximum variational inference lower bound to enhance their correlations. Subsequently, we derive a utility matrix based on the correlations, enabling the adaptive ranking of items in line with user preferences and establishing a balance between the aforementioned objectives. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of PODM-MI, and we have successfully deployed PODM-MI on an e-commerce search platform.
Optimizing E-commerce Search: Toward a Generalizable and Rank-Consistent Pre-Ranking Model
May 09, 2024In large e-commerce platforms, search systems are typically composed of a series of modules, including recall, pre-ranking, and ranking phases. The pre-ranking phase, serving as a lightweight module, is crucial for filtering out the bulk of products in advance for the downstream ranking module. Industrial efforts on optimizing the pre-ranking model have predominantly focused on enhancing ranking consistency, model structure, and generalization towards long-tail items. Beyond these optimizations, meeting the system performance requirements presents a significant challenge. Contrasting with existing industry works, we propose a novel method: a Generalizable and RAnk-ConsistEnt Pre-Ranking Model (GRACE), which achieves: 1) Ranking consistency by introducing multiple binary classification tasks that predict whether a product is within the top-k results as estimated by the ranking model, which facilitates the addition of learning objectives on common point-wise ranking models; 2) Generalizability through contrastive learning of representation for all products by pre-training on a subset of ranking product embeddings; 3) Ease of implementation in feature construction and online deployment. Our extensive experiments demonstrate significant improvements in both offline metrics and online A/B test: a 0.75% increase in AUC and a 1.28% increase in CVR.
Multimodal Information Interaction for Medical Image Segmentation
Apr 25, 2024The use of multimodal data in assisted diagnosis and segmentation has emerged as a prominent area of interest in current research. However, one of the primary challenges is how to effectively fuse multimodal features. Most of the current approaches focus on the integration of multimodal features while ignoring the correlation and consistency between different modal features, leading to the inclusion of potentially irrelevant information. To address this issue, we introduce an innovative Multimodal Information Cross Transformer (MicFormer), which employs a dual-stream architecture to simultaneously extract features from each modality. Leveraging the Cross Transformer, it queries features from one modality and retrieves corresponding responses from another, facilitating effective communication between bimodal features. Additionally, we incorporate a deformable Transformer architecture to expand the search space. We conducted experiments on the MM-WHS dataset, and in the CT-MRI multimodal image segmentation task, we successfully improved the whole-heart segmentation DICE score to 85.57 and MIoU to 75.51. Compared to other multimodal segmentation techniques, our method outperforms by margins of 2.83 and 4.23, respectively. This demonstrates the efficacy of MicFormer in integrating relevant information between different modalities in multimodal tasks. These findings hold significant implications for multimodal image tasks, and we believe that MicFormer possesses extensive potential for broader applications across various domains. Access to our method is available at https://github.com/fxxJuses/MICFormer
Mixup Domain Adaptations for Dynamic Remaining Useful Life Predictions
Apr 07, 2024Remaining Useful Life (RUL) predictions play vital role for asset planning and maintenance leading to many benefits to industries such as reduced downtime, low maintenance costs, etc. Although various efforts have been devoted to study this topic, most existing works are restricted for i.i.d conditions assuming the same condition of the training phase and the deployment phase. This paper proposes a solution to this problem where a mix-up domain adaptation (MDAN) is put forward. MDAN encompasses a three-staged mechanism where the mix-up strategy is not only performed to regularize the source and target domains but also applied to establish an intermediate mix-up domain where the source and target domains are aligned. The self-supervised learning strategy is implemented to prevent the supervision collapse problem. Rigorous evaluations have been performed where MDAN is compared to recently published works for dynamic RUL predictions. MDAN outperforms its counterparts with substantial margins in 12 out of 12 cases. In addition, MDAN is evaluated with the bearing machine dataset where it beats prior art with significant gaps in 8 of 12 cases. Source codes of MDAN are made publicly available in \url{https://github.com/furqon3009/MDAN}.
* accepted for publication in Knowledge-based Systems
MTP: Advancing Remote Sensing Foundation Model via Multi-Task Pretraining
Mar 20, 2024



Foundation models have reshaped the landscape of Remote Sensing (RS) by enhancing various image interpretation tasks. Pretraining is an active research topic, encompassing supervised and self-supervised learning methods to initialize model weights effectively. However, transferring the pretrained models to downstream tasks may encounter task discrepancy due to their formulation of pretraining as image classification or object discrimination tasks. In this study, we explore the Multi-Task Pretraining (MTP) paradigm for RS foundation models to address this issue. Using a shared encoder and task-specific decoder architecture, we conduct multi-task supervised pretraining on the SAMRS dataset, encompassing semantic segmentation, instance segmentation, and rotated object detection. MTP supports both convolutional neural networks and vision transformer foundation models with over 300 million parameters. The pretrained models are finetuned on various RS downstream tasks, such as scene classification, horizontal and rotated object detection, semantic segmentation, and change detection. Extensive experiments across 14 datasets demonstrate the superiority of our models over existing ones of similar size and their competitive performance compared to larger state-of-the-art models, thus validating the effectiveness of MTP.
GraphBEV: Towards Robust BEV Feature Alignment for Multi-Modal 3D Object Detection
Mar 18, 2024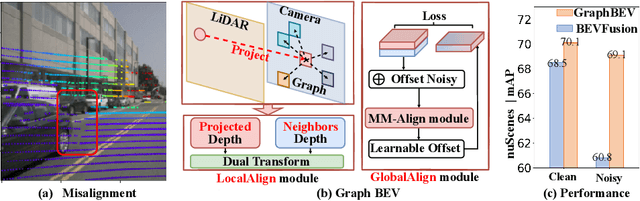
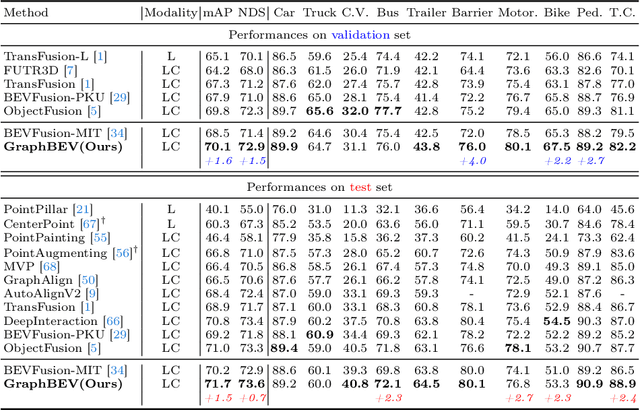
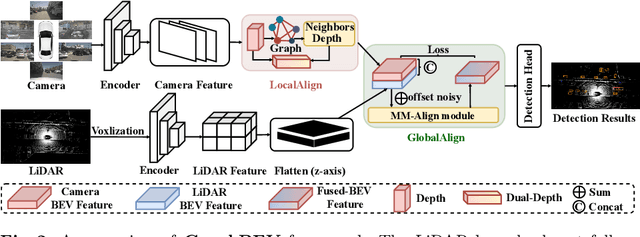
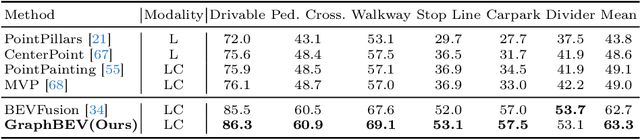
Integrating LiDAR and camera information into Bird's-Eye-View (BEV) representation has emerged as a crucial aspect of 3D object detection in autonomous driving. However, existing methods are susceptible to the inaccurate calibration relationship between LiDAR and the camera sensor. Such inaccuracies result in errors in depth estimation for the camera branch, ultimately causing misalignment between LiDAR and camera BEV features. In this work, we propose a robust fusion framework called Graph BEV. Addressing errors caused by inaccurate point cloud projection, we introduce a Local Align module that employs neighbor-aware depth features via Graph matching. Additionally, we propose a Global Align module to rectify the misalignment between LiDAR and camera BEV features. Our Graph BEV framework achieves state-of-the-art performance, with an mAP of 70.1\%, surpassing BEV Fusion by 1.6\% on the nuscenes validation set. Importantly, our Graph BEV outperforms BEV Fusion by 8.3\% under conditions with misalignment noise.
Controllable Relation Disentanglement for Few-Shot Class-Incremental Learning
Mar 17, 2024



In this paper, we propose to tackle Few-Shot Class-Incremental Learning (FSCIL) from a new perspective, i.e., relation disentanglement, which means enhancing FSCIL via disentangling spurious relation between categories. The challenge of disentangling spurious correlations lies in the poor controllability of FSCIL. On one hand, an FSCIL model is required to be trained in an incremental manner and thus it is very hard to directly control relationships between categories of different sessions. On the other hand, training samples per novel category are only in the few-shot setting, which increases the difficulty of alleviating spurious relation issues as well. To overcome this challenge, in this paper, we propose a new simple-yet-effective method, called ConTrollable Relation-disentangLed Few-Shot Class-Incremental Learning (CTRL-FSCIL). Specifically, during the base session, we propose to anchor base category embeddings in feature space and construct disentanglement proxies to bridge gaps between the learning for category representations in different sessions, thereby making category relation controllable. During incremental learning, the parameters of the backbone network are frozen in order to relieve the negative impact of data scarcity. Moreover, a disentanglement loss is designed to effectively guide a relation disentanglement controller to disentangle spurious correlations between the embeddings encoded by the backbone. In this way, the spurious correlation issue in FSCIL can be suppressed. Extensive experiments on CIFAR-100, mini-ImageNet, and CUB-200 datasets demonstrate the effectiveness of our CTRL-FSCIL method.