 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignSAM: Aligning Segment Anything Model to Open Context via Reinforcement Learning
Jun 01, 2024Powered by massive curated training data, Segment Anything Model (SAM) has demonstrated its impressive generalization capabilities in open-world scenarios with the guidance of prompts. However, the vanilla SAM is class agnostic and heavily relies on user-provided prompts to segment objects of interest. Adapting this method to diverse tasks is crucial for accurate target identification and to avoid suboptimal segmentation results. In this paper, we propose a novel framework, termed AlignSAM, designed for automatic prompting for aligning SAM to an open context through reinforcement learning. Anchored by an agent, AlignSAM enables the generality of the SAM model across diverse downstream tasks while keeping its parameters frozen. Specifically, AlignSAM initiates a prompting agent to iteratively refine segmentation predictions by interacting with the foundational model. It integrates a reinforcement learning policy network to provide informative prompts to the foundational models. Additionally, a semantic recalibration module is introduced to provide fine-grained labels of prompts, enhancing the model's proficiency in handling tasks encompassing explicit and implicit semantics. Experiments conducted on various challenging segmentation tasks among existing foundation models demonstrate the superiority of the proposed AlignSAM over state-of-the-art approaches. Project page: \url{https://github.com/Duojun-Huang/AlignSAM-CVPR2024}.
TIE: Revolutionizing Text-based Image Editing for Complex-Prompt Following and High-Fidelity Editing
May 27, 2024As the field of image generation rapidly advances, traditional diffusion models and those integrated with multimodal large language models (LLMs) still encounter limitations in interpreting complex prompts and preserving image consistency pre and post-editing. To tackle these challenges, we present an innovative image editing framework that employs the robust Chain-of-Thought (CoT) reasoning and localizing capabilities of multimodal LLMs to aid diffusion models in generating more refined images. We first meticulously design a CoT process comprising instruction decomposition, region localization, and detailed description. Subsequently, we fine-tune the LISA model, a lightweight multimodal LLM, using the CoT process of Multimodal LLMs and the mask of the edited image. By providing the diffusion models with knowledge of the generated prompt and image mask, our models generate images with a superior understanding of instructions. Through extensive experiments, our model has demonstrated superior performance in image generation, surpassing existing state-of-the-art models. Notably, our model exhibits an enhanced ability to understand complex prompts and generate corresponding images, while maintaining high fidelity and consistency in images before and after generation.
Integer Scale: A Free Lunch for Faster Fine-grained Quantization of LLMs
May 23, 2024We introduce Integer Scale, a novel post-training quantization scheme for large language models that effectively resolves the inference bottleneck in current fine-grained quantization approaches while maintaining similar accuracies. Integer Scale is a free lunch as it requires no extra calibration or fine-tuning which will otherwise incur additional costs. It can be used plug-and-play for most fine-grained quantization methods. Its integration results in at most 1.85x end-to-end speed boost over the original counterpart with comparable accuracy. Additionally, due to the orchestration of the proposed Integer Scale and fine-grained quantization, we resolved the quantization difficulty for Mixtral-8x7B and LLaMA-3 models with negligible performance degradation, and it comes with an end-to-end speed boost of 2.13x, and 2.31x compared with their FP16 versions respectively.
Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts
May 18, 2024Recent advancements in Multimodal Large Language Models (MLLMs) underscore the significance of scalable models and data to boost performance, yet this often incurs substantial computational costs. Although the Mixture of Experts (MoE) architecture has been employed to efficiently scale large language and image-text models, these efforts typically involve fewer experts and limited modalities. To address this, our work presents the pioneering attempt to develop a unified MLLM with the MoE architecture, named Uni-MoE that can handle a wide array of modalities. Specifically, it features modality-specific encoders with connectors for a unified multimodal representation. We also implement a sparse MoE architecture within the LLMs to enable efficient training and inference through modality-level data parallelism and expert-level model parallelism. To enhance the multi-expert collaboration and generalization, we present a progressive training strategy: 1) Cross-modality alignment using various connectors with different cross-modality data, 2) Training modality-specific experts with cross-modality instruction data to activate experts' preferences, and 3) Tuning the Uni-MoE framework utilizing Low-Rank Adaptation (LoRA) on mixed multimodal instruction data. We evaluate the instruction-tuned Uni-MoE on a comprehensive set of multimodal datasets. The extensive experimental results demonstrate Uni-MoE's principal advantage of significantly reducing performance bias in handling mixed multimodal datasets, alongside improved multi-expert collaboration and generalization. Our findings highlight the substantial potential of MoE frameworks in advancing MLLMs and the code is available at https://github.com/HITsz-TMG/UMOE-Scaling-Unified-Multimodal-LLMs.
Coin3D: Controllable and Interactive 3D Assets Generation with Proxy-Guided Conditioning
May 13, 2024As humans, we aspire to create media content that is both freely willed and readily controlled. Thanks to the prominent development of generative techniques, we now can easily utilize 2D diffusion methods to synthesize images controlled by raw sketch or designated human poses, and even progressively edit/regenerate local regions with masked inpainting. However, similar workflows in 3D modeling tasks are still unavailable due to the lack of controllability and efficiency in 3D generation. In this paper, we present a novel controllable and interactive 3D assets modeling framework, named Coin3D. Coin3D allows users to control the 3D generation using a coarse geometry proxy assembled from basic shapes, and introduces an interactive generation workflow to support seamless local part editing while delivering responsive 3D object previewing within a few seconds. To this end, we develop several techniques, including the 3D adapter that applies volumetric coarse shape control to the diffusion model, proxy-bounded editing strategy for precise part editing, progressive volume cache to support responsive preview, and volume-SDS to ensure consistent mesh reconstruction. Extensive experiments of interactive generation and editing on diverse shape proxies demonstrate that our method achieves superior controllability and flexibility in the 3D assets generation task.
Aux-NAS: Exploiting Auxiliary Labels with Negligibly Extra Inference Cost
May 09, 2024We aim at exploiting additional auxiliary labels from an independent (auxiliary) task to boost the primary task performance which we focus on, while preserving a single task inference cost of the primary task. While most existing auxiliary learning methods are optimization-based relying on loss weights/gradients manipulation, our method is architecture-based with a flexible asymmetric structure for the primary and auxiliary tasks, which produces different networks for training and inference. Specifically, starting from two single task networks/branches (each representing a task), we propose a novel method with evolving networks where only primary-to-auxiliary links exist as the cross-task connections after convergence. These connections can be removed during the primary task inference, resulting in a single-task inference cost. We achieve this by formulating a Neural Architecture Search (NAS) problem, where we initialize bi-directional connections in the search space and guide the NAS optimization converging to an architecture with only the single-side primary-to-auxiliary connections. Moreover, our method can be incorporated with optimization-based auxiliary learning approaches. Extensive experiments with six tasks on NYU v2, CityScapes, and Taskonomy datasets using VGG, ResNet, and ViT backbones validate the promising performance. The codes are available at https://github.com/ethanygao/Aux-NAS.
* Accepted to ICLR 2024
Matten: Video Generation with Mamba-Attention
May 05, 2024In this paper, we introduce Matten, a cutting-edge latent diffusion model with Mamba-Attention architecture for video generation. With minimal computational cost, Matten employs spatial-temporal attention for local video content modeling and bidirectional Mamba for global video content modeling. Our comprehensive experimental evaluation demonstrates that Matten has competitive performance with the current Transformer-based and GAN-based models in benchmark performance, achieving superior FVD scores and efficiency. Additionally, we observe a direct positive correlation between the complexity of our designed model and the improvement in video quality, indicating the excellent scalability of Matten.
LaSagnA: Language-based Segmentation Assistant for Complex Queries
Apr 12, 2024Recent advancements have empowered Large Language Models for Vision (vLLMs) to generate detailed perceptual outcomes, including bounding boxes and masks. Nonetheless, there are two constraints that restrict the further application of these vLLMs: the incapability of handling multiple targets per query and the failure to identify the absence of query objects in the image. In this study, we acknowledge that the main cause of these problems is the insufficient complexity of training queries. Consequently, we define the general sequence format for complex queries. Then we incorporate a semantic segmentation task in the current pipeline to fulfill the requirements of training data. Furthermore, we present three novel strategies to effectively handle the challenges arising from the direct integration of the proposed format. The effectiveness of our model in processing complex queries is validated by the comparable results with conventional methods on both close-set and open-set semantic segmentation datasets. Additionally, we outperform a series of vLLMs in reasoning and referring segmentation, showcasing our model's remarkable capabilities. We release the code at https://github.com/congvvc/LaSagnA.
UniMD: Towards Unifying Moment Retrieval and Temporal Action Detection
Apr 07, 2024Temporal Action Detection (TAD) focuses on detecting pre-defined actions, while Moment Retrieval (MR) aims to identify the events described by open-ended natural language within untrimmed videos. Despite that they focus on different events, we observe they have a significant connection. For instance, most descriptions in MR involve multiple actions from TAD. In this paper, we aim to investigate the potential synergy between TAD and MR. Firstly, we propose a unified architecture, termed Unified Moment Detection (UniMD), for both TAD and MR. It transforms the inputs of the two tasks, namely actions for TAD or events for MR, into a common embedding space, and utilizes two novel query-dependent decoders to generate a uniform output of classification score and temporal segments. Secondly, we explore the efficacy of two task fusion learning approaches, pre-training and co-training, in order to enhance the mutual benefits between TAD and MR. Extensive experiments demonstrate that the proposed task fusion learning scheme enables the two tasks to help each other and outperform the separately trained counterparts. Impressively, UniMD achieves state-of-the-art results on three paired datasets Ego4D, Charades-STA, and ActivityNet. Our code will be released at https://github.com/yingsen1/UniMD.
Lumen: Unleashing Versatile Vision-Centric Capabilities of Large Multimodal Models
Mar 12, 2024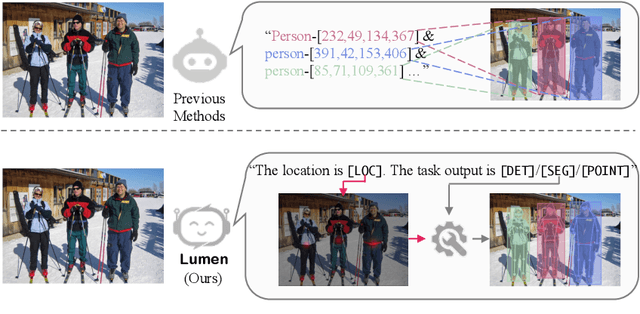
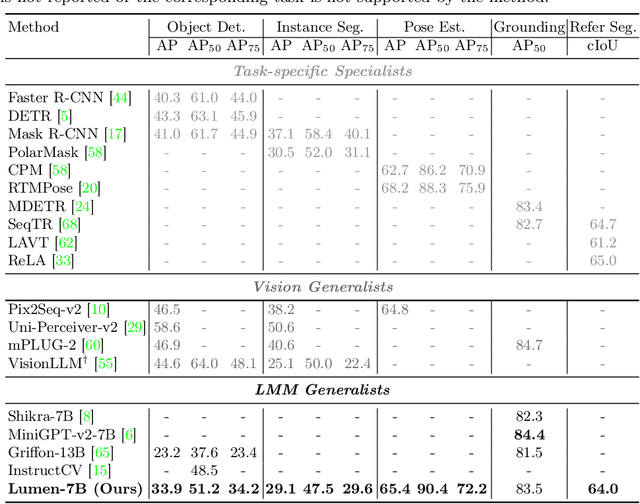
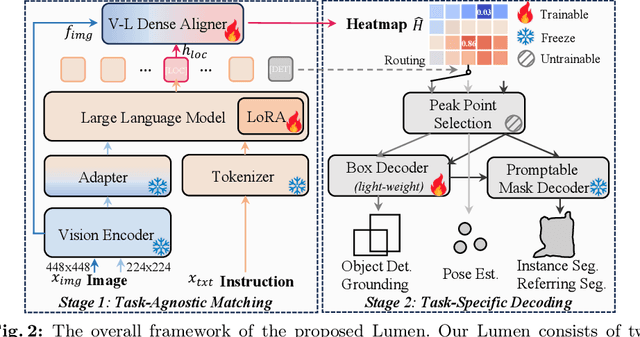

Large Multimodal Model (LMM) is a hot research topic in the computer vision area and has also demonstrated remarkable potential across multiple disciplinary fields. A recent trend is to further extend and enhance the perception capabilities of LMMs. The current methods follow the paradigm of adapting the visual task outputs to the format of the language model, which is the main component of a LMM. This adaptation leads to convenient development of such LMMs with minimal modifications, however, it overlooks the intrinsic characteristics of diverse visual tasks and hinders the learning of perception capabilities. To address this issue, we propose a novel LMM architecture named Lumen, a Large multimodal model with versatile vision-centric capability enhancement. We decouple the LMM's learning of perception capabilities into task-agnostic and task-specific stages. Lumen first promotes fine-grained vision-language concept alignment, which is the fundamental capability for various visual tasks. Thus the output of the task-agnostic stage is a shared representation for all the tasks we address in this paper. Then the task-specific decoding is carried out by flexibly routing the shared representation to lightweight task decoders with negligible training efforts. Benefiting from such a decoupled design, our Lumen surpasses existing LMM-based approaches on the COCO detection benchmark with a clear margin and exhibits seamless scalability to additional visual tasks. Furthermore, we also conduct comprehensive ablation studies and generalization evaluations for deeper insights. The code will be released at https://github.com/SxJyJay/Lumen.