 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Generative Embedding Model
May 29, 2024Most multi-modal tasks can be formulated into problems of either generation or embedding. Existing models usually tackle these two types of problems by decoupling language modules into a text decoder for generation, and a text encoder for embedding. To explore the minimalism of multi-modal paradigms, we attempt to achieve only one model per modality in this work. We propose a Multi-Modal Generative Embedding Model (MM-GEM), whereby the generative and embedding objectives are encapsulated in one Large Language Model. We also propose a PoolAggregator to boost efficiency and enable the ability of fine-grained embedding and generation. A surprising finding is that these two objectives do not significantly conflict with each other. For example, MM-GEM instantiated from ViT-Large and TinyLlama shows competitive performance on benchmarks for multimodal embedding models such as cross-modal retrieval and zero-shot classification, while has good ability of image captioning. Additionally, MM-GEM can seamlessly execute region-level image caption generation and retrieval tasks. Besides, the advanced text model in MM-GEM brings over 5% improvement in Recall@1 for long text and image retrieval.
LOVA3: Learning to Visual Question Answering, Asking and Assessment
May 23, 2024Question answering, asking, and assessment are three innate human traits crucial for understanding the world and acquiring knowledge. By enhancing these capabilities, humans can more effectively utilize data, leading to better comprehension and learning outcomes. However, current Multimodal Large Language Models (MLLMs) primarily focus on question answering, often neglecting the full potential of questioning and assessment skills. In this study, we introduce LOVA3, an innovative framework named ``Learning tO Visual Question Answering, Asking and Assessment,'' designed to equip MLLMs with these additional capabilities. Our approach involves the creation of two supplementary training tasks GenQA and EvalQA, aiming at fostering the skills of asking and assessing questions in the context of images. To develop the questioning ability, we compile a comprehensive set of multimodal foundational tasks. For assessment, we introduce a new benchmark called EvalQABench, comprising 64,000 training samples (split evenly between positive and negative samples) and 5,000 testing samples. We posit that enhancing MLLMs with the capabilities to answer, ask, and assess questions will improve their multimodal comprehension and lead to better performance. We validate our hypothesis by training an MLLM using the LOVA3 framework and testing it on 10 multimodal benchmarks. The results demonstrate consistent performance improvements, thereby confirming the efficacy of our approach.
Hallucination of Multimodal Large Language Models: A Survey
Apr 29, 2024This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
Learning Long-form Video Prior via Generative Pre-Training
Apr 24, 2024



Concepts involved in long-form videos such as people, objects, and their interactions, can be viewed as following an implicit prior. They are notably complex and continue to pose challenges to be comprehensively learned. In recent years, generative pre-training (GPT) has exhibited versatile capacities in modeling any kind of text content even visual locations. Can this manner work for learning long-form video prior? Instead of operating on pixel space, it is efficient to employ visual locations like bounding boxes and keypoints to represent key information in videos, which can be simply discretized and then tokenized for consumption by GPT. Due to the scarcity of suitable data, we create a new dataset called \textbf{Storyboard20K} from movies to serve as a representative. It includes synopses, shot-by-shot keyframes, and fine-grained annotations of film sets and characters with consistent IDs, bounding boxes, and whole body keypoints. In this way, long-form videos can be represented by a set of tokens and be learned via generative pre-training. Experimental results validate that our approach has great potential for learning long-form video prior. Code and data will be released at \url{https://github.com/showlab/Long-form-Video-Prior}.
RingID: Rethinking Tree-Ring Watermarking for Enhanced Multi-Key Identification
Apr 23, 2024We revisit Tree-Ring Watermarking, a recent diffusion model watermarking method that demonstrates great robustness to various attacks. We conduct an in-depth study on it and reveal that the distribution shift unintentionally introduced by the watermarking process, apart from watermark pattern matching, contributes to its exceptional robustness. Our investigation further exposes inherent flaws in its original design, particularly in its ability to identify multiple distinct keys, where distribution shift offers no assistance. Based on these findings and analysis, we present RingID for enhanced multi-key identification. It consists of a novel multi-channel heterogeneous watermarking approach designed to seamlessly amalgamate distinctive advantages from diverse watermarks. Coupled with a series of suggested enhancements, RingID exhibits substantial advancements in multi-key identification. Github Page: https://github.com/showlab/RingID
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Apr 03, 2024This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Diffusion-Driven Self-Supervised Learning for Shape Reconstruction and Pose Estimation
Mar 19, 2024



Fully-supervised category-level pose estimation aims to determine the 6-DoF poses of unseen instances from known categories, requiring expensive mannual labeling costs. Recently, various self-supervised category-level pose estimation methods have been proposed to reduce the requirement of the annotated datasets. However, most methods rely on synthetic data or 3D CAD model for self-supervised training, and they are typically limited to addressing single-object pose problems without considering multi-objective tasks or shape reconstruction. To overcome these challenges and limitations, we introduce a diffusion-driven self-supervised network for multi-object shape reconstruction and categorical pose estimation, only leveraging the shape priors. Specifically, to capture the SE(3)-equivariant pose features and 3D scale-invariant shape information, we present a Prior-Aware Pyramid 3D Point Transformer in our network. This module adopts a point convolutional layer with radial-kernels for pose-aware learning and a 3D scale-invariant graph convolution layer for object-level shape representation, respectively. Furthermore, we introduce a pretrain-to-refine self-supervised training paradigm to train our network. It enables proposed network to capture the associations between shape priors and observations, addressing the challenge of intra-class shape variations by utilising the diffusion mechanism. Extensive experiments conducted on four public datasets and a self-built dataset demonstrate that our method significantly outperforms state-of-the-art self-supervised category-level baselines and even surpasses some fully-supervised instance-level and category-level methods.
DragAnything: Motion Control for Anything using Entity Representation
Mar 15, 2024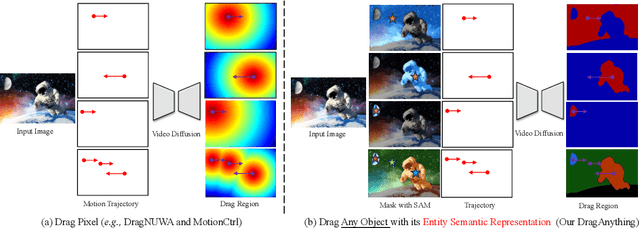

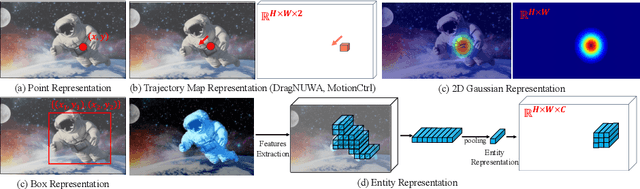

We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background. Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our DragAnything achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.
Bring Your Own Character: A Holistic Solution for Automatic Facial Animation Generation of Customized Characters
Feb 21, 2024Animating virtual characters has always been a fundamental research problem in virtual reality (VR). Facial animations play a crucial role as they effectively convey emotions and attitudes of virtual humans. However, creating such facial animations can be challenging, as current methods often involve utilization of expensive motion capture devices or significant investments of time and effort from human animators in tuning animation parameters. In this paper, we propose a holistic solution to automatically animate virtual human faces. In our solution, a deep learning model was first trained to retarget the facial expression from input face images to virtual human faces by estimating the blendshape coefficients. This method offers the flexibility of generating animations with characters of different appearances and blendshape topologies. Second, a practical toolkit was developed using Unity 3D, making it compatible with the most popular VR applications. The toolkit accepts both image and video as input to animate the target virtual human faces and enables users to manipulate the animation results. Furthermore, inspired by the spirit of Human-in-the-loop (HITL), we leveraged user feedback to further improve the performance of the model and toolkit, thereby increasing the customization properties to suit user preferences. The whole solution, for which we will make the code public, has the potential to accelerate the generation of facial animations for use in VR applications.
Skip : A Simple Method to Reduce Hallucination in Large Vision-Language Models
Feb 12, 2024Recent advancements in large vision-language models (LVLMs) have demonstrated impressive capability in visual information understanding with human language. Despite these advances, LVLMs still face challenges with multimodal hallucination, such as generating text descriptions of objects that are not present in the visual information. However, the underlying fundamental reasons of multimodal hallucinations remain poorly explored. In this paper, we propose a new perspective, suggesting that the inherent biases in LVLMs might be a key factor in hallucinations. Specifically, we systematically identify a semantic shift bias related to paragraph breaks (\n\n), where the content before and after '\n\n' in the training data frequently exhibit significant semantic changes. This pattern leads the model to infer that the contents following '\n\n' should be obviously different from the preceding contents with less hallucinatory descriptions, thereby increasing the probability of hallucinatory descriptions subsequent to the '\n\n'. We have validated this hypothesis on multiple publicly available LVLMs. Besides, we find that deliberately inserting '\n\n' at the generated description can induce more hallucinations. A simple method is proposed to effectively mitigate the hallucination of LVLMs by skipping the output of '\n'.