 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogic Synthesis with Generative Deep Neural Networks
Jun 07, 2024While deep learning has achieved significant success in various domains, its application to logic circuit design has been limited due to complex constraints and strict feasibility requirement. However, a recent generative deep neural model, "Circuit Transformer", has shown promise in this area by enabling equivalence-preserving circuit transformation on a small scale. In this paper, we introduce a logic synthesis rewriting operator based on the Circuit Transformer model, named "ctrw" (Circuit Transformer Rewriting), which incorporates the following techniques: (1) a two-stage training scheme for the Circuit Transformer tailored for logic synthesis, with iterative improvement of optimality through self-improvement training; (2) integration of the Circuit Transformer with state-of-the-art rewriting techniques to address scalability issues, allowing for guided DAG-aware rewriting. Experimental results on the IWLS 2023 contest benchmark demonstrate the effectiveness of our proposed rewriting methods.
DPN: Decoupling Partition and Navigation for Neural Solvers of Min-max Vehicle Routing Problems
May 27, 2024The min-max vehicle routing problem (min-max VRP) traverses all given customers by assigning several routes and aims to minimize the length of the longest route. Recently, reinforcement learning (RL)-based sequential planning methods have exhibited advantages in solving efficiency and optimality. However, these methods fail to exploit the problem-specific properties in learning representations, resulting in less effective features for decoding optimal routes. This paper considers the sequential planning process of min-max VRPs as two coupled optimization tasks: customer partition for different routes and customer navigation in each route (i.e., partition and navigation). To effectively process min-max VRP instances, we present a novel attention-based Partition-and-Navigation encoder (P&N Encoder) that learns distinct embeddings for partition and navigation. Furthermore, we utilize an inherent symmetry in decoding routes and develop an effective agent-permutation-symmetric (APS) loss function. Experimental results demonstrate that the proposed Decoupling-Partition-Navigation (DPN) method significantly surpasses existing learning-based methods in both single-depot and multi-depot min-max VRPs. Our code is available at
SmoothGNN: Smoothing-based GNN for Unsupervised Node Anomaly Detection
May 27, 2024The smoothing issue leads to indistinguishable node representations, which poses a significant challenge in the field of graph learning. However, this issue also presents an opportunity to reveal underlying properties behind different types of nodes, which have been overlooked in previous studies. Through empirical and theoretical analysis of real-world node anomaly detection (NAD) datasets, we observe that anomalous and normal nodes show different patterns in the smoothing process, which can be leveraged to enhance NAD tasks. Motivated by these findings, in this paper, we propose a novel unsupervised NAD framework. Specifically, according to our theoretical analysis, we design a Smoothing Learning Component. Subsequently, we introduce a Smoothing-aware Spectral Graph Neural Network, which establishes the connection between the spectral space of graphs and the smoothing process. Additionally, we demonstrate that the Dirichlet Energy, which reflects the smoothness of a graph, can serve as coefficients for node representations across different dimensions of the spectral space. Building upon these observations and analyses, we devise a novel anomaly measure for the NAD task. Extensive experiments on 9 real-world datasets show that SmoothGNN outperforms the best rival by an average of 14.66% in AUC and 7.28% in Precision, with 75x running time speed-up, which validates the effectiveness and efficiency of our framework.
Prompt Learning for Generalized Vehicle Routing
May 20, 2024Neural combinatorial optimization (NCO) is a promising learning-based approach to solving various vehicle routing problems without much manual algorithm design. However, the current NCO methods mainly focus on the in-distribution performance, while the real-world problem instances usually come from different distributions. A costly fine-tuning approach or generalized model retraining from scratch could be needed to tackle the out-of-distribution instances. Unlike the existing methods, this work investigates an efficient prompt learning approach in NCO for cross-distribution adaptation. To be concrete, we propose a novel prompt learning method to facilitate fast zero-shot adaptation of a pre-trained model to solve routing problem instances from different distributions. The proposed model learns a set of prompts among various distributions and then selects the best-matched one to prompt a pre-trained attention model for each problem instance. Extensive experiments show that the proposed prompt learning approach facilitates the fast adaptation of pre-trained routing models. It also outperforms existing generalized models on both in-distribution prediction and zero-shot generalization to a diverse set of new tasks. Our code implementation is available online https://github.com/FeiLiu36/PromptVRP.
GraSS: Combining Graph Neural Networks with Expert Knowledge for SAT Solver Selection
May 17, 2024Boolean satisfiability (SAT) problems are routinely solved by SAT solvers in real-life applications, yet solving time can vary drastically between solvers for the same instance. This has motivated research into machine learning models that can predict, for a given SAT instance, which solver to select among several options. Existing SAT solver selection methods all rely on some hand-picked instance features, which are costly to compute and ignore the structural information in SAT graphs. In this paper we present GraSS, a novel approach for automatic SAT solver selection based on tripartite graph representations of instances and a heterogeneous graph neural network (GNN) model. While GNNs have been previously adopted in other SAT-related tasks, they do not incorporate any domain-specific knowledge and ignore the runtime variation introduced by different clause orders. We enrich the graph representation with domain-specific decisions, such as novel node feature design, positional encodings for clauses in the graph, a GNN architecture tailored to our tripartite graphs and a runtime-sensitive loss function. Through extensive experiments, we demonstrate that this combination of raw representations and domain-specific choices leads to improvements in runtime for a pool of seven state-of-the-art solvers on both an industrial circuit design benchmark, and on instances from the 20-year Anniversary Track of the 2022 SAT Competition.
Instance-Conditioned Adaptation for Large-scale Generalization of Neural Combinatorial Optimization
May 03, 2024The neural combinatorial optimization (NCO) approach has shown great potential for solving routing problems without the requirement of expert knowledge. However, existing constructive NCO methods cannot directly solve large-scale instances, which significantly limits their application prospects. To address these crucial shortcomings, this work proposes a novel Instance-Conditioned Adaptation Model (ICAM) for better large-scale generalization of neural combinatorial optimization. In particular, we design a powerful yet lightweight instance-conditioned adaptation module for the NCO model to generate better solutions for instances across different scales. In addition, we develop an efficient three-stage reinforcement learning-based training scheme that enables the model to learn cross-scale features without any labeled optimal solution. Experimental results show that our proposed method is capable of obtaining excellent results with a very fast inference time in solving Traveling Salesman Problems (TSPs) and Capacitated Vehicle Routing Problems (CVRPs) across different scales. To the best of our knowledge, our model achieves state-of-the-art performance among all RL-based constructive methods for TSP and CVRP with up to 1,000 nodes.
Learning to Cut via Hierarchical Sequence/Set Model for Efficient Mixed-Integer Programming
Apr 19, 2024Cutting planes (cuts) play an important role in solving mixed-integer linear programs (MILPs), which formulate many important real-world applications. Cut selection heavily depends on (P1) which cuts to prefer and (P2) how many cuts to select. Although modern MILP solvers tackle (P1)-(P2) by human-designed heuristics, machine learning carries the potential to learn more effective heuristics. However, many existing learning-based methods learn which cuts to prefer, neglecting the importance of learning how many cuts to select. Moreover, we observe that (P3) what order of selected cuts to prefer significantly impacts the efficiency of MILP solvers as well. To address these challenges, we propose a novel hierarchical sequence/set model (HEM) to learn cut selection policies. Specifically, HEM is a bi-level model: (1) a higher-level module that learns how many cuts to select, (2) and a lower-level module -- that formulates the cut selection as a sequence/set to sequence learning problem -- to learn policies selecting an ordered subset with the cardinality determined by the higher-level module. To the best of our knowledge, HEM is the first data-driven methodology that well tackles (P1)-(P3) simultaneously. Experiments demonstrate that HEM significantly improves the efficiency of solving MILPs on eleven challenging MILP benchmarks, including two Huawei's real problems.
Self-Improved Learning for Scalable Neural Combinatorial Optimization
Mar 30, 2024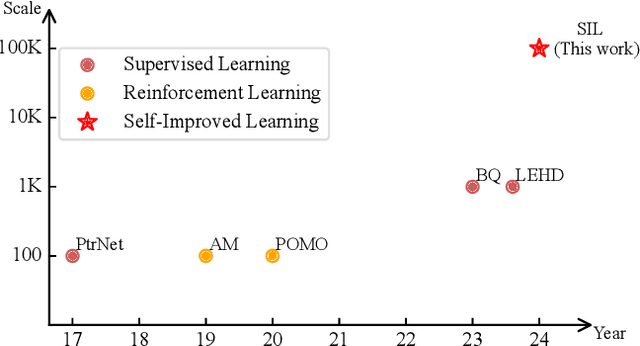


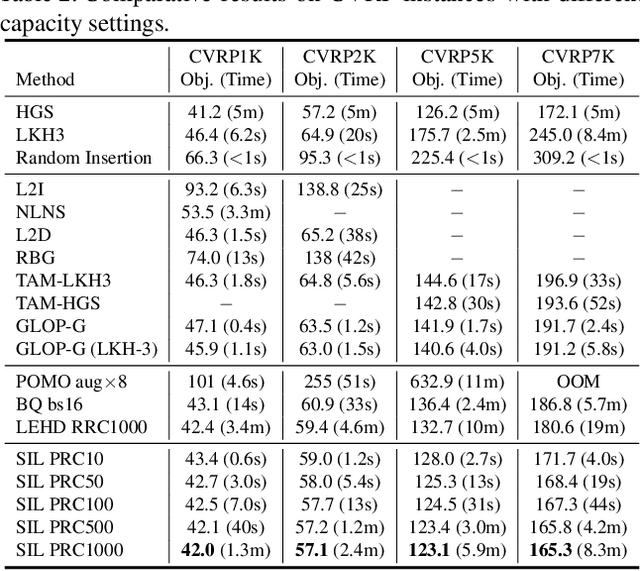
The end-to-end neural combinatorial optimization (NCO) method shows promising performance in solving complex combinatorial optimization problems without the need for expert design. However, existing methods struggle with large-scale problems, hindering their practical applicability. To overcome this limitation, this work proposes a novel Self-Improved Learning (SIL) method for better scalability of neural combinatorial optimization. Specifically, we develop an efficient self-improved mechanism that enables direct model training on large-scale problem instances without any labeled data. Powered by an innovative local reconstruction approach, this method can iteratively generate better solutions by itself as pseudo-labels to guide efficient model training. In addition, we design a linear complexity attention mechanism for the model to efficiently handle large-scale combinatorial problem instances with low computation overhead. Comprehensive experiments on the Travelling Salesman Problem (TSP) and the Capacitated Vehicle Routing Problem (CVRP) with up to 100K nodes in both uniform and real-world distributions demonstrate the superior scalability of our method.
HDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024
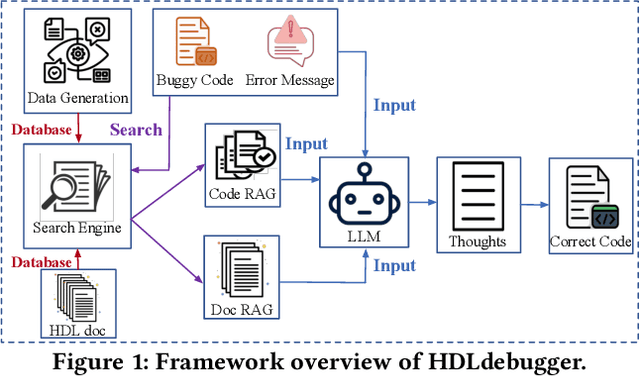

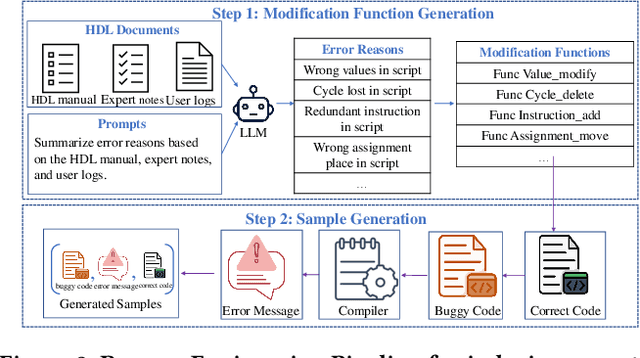
In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
Circuit Transformer: End-to-end Circuit Design by Predicting the Next Gate
Mar 14, 2024



Language, a prominent human ability to express through sequential symbols, has been computationally mastered by recent advances of large language models (LLMs). By predicting the next word recurrently with huge neural models, LLMs have shown unprecedented capabilities in understanding and reasoning. Circuit, as the "language" of electronic design, specifies the functionality of an electronic device by cascade connections of logic gates. Then, can circuits also be mastered by a a sufficiently large "circuit model", which can conquer electronic design tasks by simply predicting the next logic gate? In this work, we take the first step to explore such possibilities. Two primary barriers impede the straightforward application of LLMs to circuits: their complex, non-sequential structure, and the intolerance of hallucination due to strict constraints (e.g., equivalence). For the first barrier, we encode a circuit as a memory-less, depth-first traversal trajectory, which allows Transformer-based neural models to better leverage its structural information, and predict the next gate on the trajectory as a circuit model. For the second barrier, we introduce an equivalence-preserving decoding process, which ensures that every token in the generated trajectory adheres to the specified equivalence constraints. Moreover, the circuit model can also be regarded as a stochastic policy to tackle optimization-oriented circuit design tasks. Experimentally, we trained a Transformer-based model of 88M parameters, named "Circuit Transformer", which demonstrates impressive performance in end-to-end logic synthesis. With Monte-Carlo tree search, Circuit Transformer significantly improves over resyn2 while retaining strict equivalence, showcasing the potential of generative AI in conquering electronic design challenges.