 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing Language Agents via Policy Optimization with Action Decomposition
May 23, 2024Language models as intelligent agents push the boundaries of sequential decision-making agents but struggle with limited knowledge of environmental dynamics and exponentially huge action space. Recent efforts like GLAM and TWOSOME manually constrain the action space to a restricted subset and employ reinforcement learning to align agents' knowledge with specific environments. However, they overlook fine-grained credit assignments for intra-action tokens, which is essential for efficient language agent optimization, and rely on human's prior knowledge to restrict action space. This paper proposes decomposing language agent optimization from the action level to the token level, offering finer supervision for each intra-action token and manageable optimization complexity in environments with unrestricted action spaces. Beginning with the simplification of flattening all actions, we theoretically explore the discrepancies between action-level optimization and this naive token-level optimization. We then derive the Bellman backup with Action Decomposition (BAD) to integrate credit assignments for both intra-action and inter-action tokens, effectively eliminating the discrepancies. Implementing BAD within the PPO algorithm, we introduce Policy Optimization with Action Decomposition (POAD). POAD benefits from a finer-grained credit assignment process and lower optimization complexity, leading to enhanced learning efficiency and generalization abilities in aligning language agents with interactive environments. We validate POAD across diverse testbeds, with results affirming the advantages of our approach and the correctness of our theoretical analysis.
TRAD: Enhancing LLM Agents with Step-Wise Thought Retrieval and Aligned Decision
Mar 10, 2024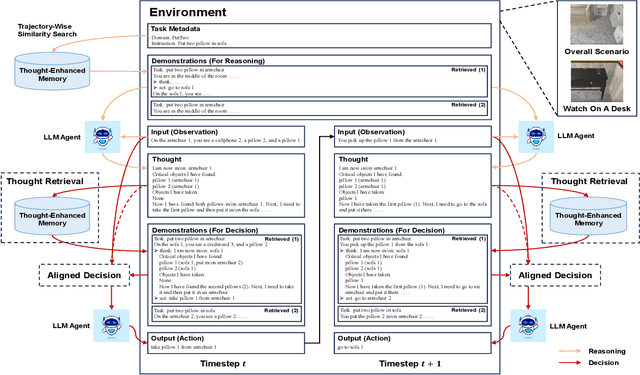

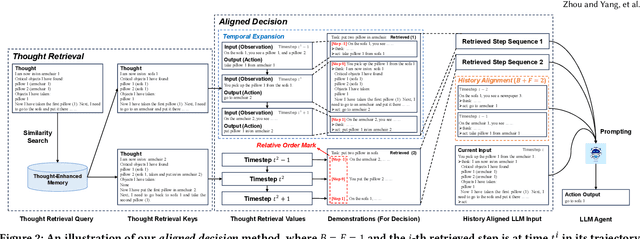

Numerous large language model (LLM) agents have been built for different tasks like web navigation and online shopping due to LLM's wide knowledge and text-understanding ability. Among these works, many of them utilize in-context examples to achieve generalization without the need for fine-tuning, while few of them have considered the problem of how to select and effectively utilize these examples. Recently, methods based on trajectory-level retrieval with task meta-data and using trajectories as in-context examples have been proposed to improve the agent's overall performance in some sequential decision making tasks. However, these methods can be problematic due to plausible examples retrieved without task-specific state transition dynamics and long input with plenty of irrelevant context. In this paper, we propose a novel framework (TRAD) to address these issues. TRAD first conducts Thought Retrieval, achieving step-level demonstration selection via thought matching, leading to more helpful demonstrations and less irrelevant input noise. Then, TRAD introduces Aligned Decision, complementing retrieved demonstration steps with their previous or subsequent steps, which enables tolerance for imperfect thought and provides a choice for balance between more context and less noise. Extensive experiments on ALFWorld and Mind2Web benchmarks show that TRAD not only outperforms state-of-the-art models but also effectively helps in reducing noise and promoting generalization. Furthermore, TRAD has been deployed in real-world scenarios of a global business insurance company and improves the success rate of robotic process automation.
Entropy-Regularized Token-Level Policy Optimization for Large Language Models
Feb 09, 2024Large Language Models (LLMs) have shown promise as intelligent agents in interactive decision-making tasks. Traditional approaches often depend on meticulously designed prompts, high-quality examples, or additional reward models for in-context learning, supervised fine-tuning, or RLHF. Reinforcement learning (RL) presents a dynamic alternative for LLMs to overcome these dependencies by engaging directly with task-specific environments. Nonetheless, it faces significant hurdles: 1) instability stemming from the exponentially vast action space requiring exploration; 2) challenges in assigning token-level credit based on action-level reward signals, resulting in discord between maximizing rewards and accurately modeling corpus data. In response to these challenges, we introduce Entropy-Regularized Token-level Policy Optimization (ETPO), an entropy-augmented RL method tailored for optimizing LLMs at the token level. At the heart of ETPO is our novel per-token soft Bellman update, designed to harmonize the RL process with the principles of language modeling. This methodology decomposes the Q-function update from a coarse action-level view to a more granular token-level perspective, backed by theoretical proof of optimization consistency. Crucially, this decomposition renders linear time complexity in action exploration. We assess the effectiveness of ETPO within a simulated environment that models data science code generation as a series of multi-step interactive tasks; results show that ETPO achieves effective performance improvement on the CodeLlama-7B model and surpasses a variant PPO baseline inherited from RLHF. This underlines ETPO's potential as a robust method for refining the interactive decision-making capabilities of LLMs.
Alphazero-like Tree-Search can Guide Large Language Model Decoding and Training
Sep 29, 2023



Large language models (LLMs) typically employ sampling or beam search, accompanied by prompts such as Chain-of-Thought (CoT), to boost reasoning and decoding ability. Recent work like Tree-of-Thought (ToT) and Reasoning via Planning (RAP) aim to augment the reasoning capabilities of LLMs by utilizing tree-search algorithms to guide multi-step reasoning. These methods mainly focus on LLMs' reasoning ability during inference and heavily rely on human-designed prompts to activate LLM as a value function, which lacks general applicability and scalability. To address these limitations, we present an AlphaZero-like tree-search framework for LLMs (termed TS-LLM), systematically illustrating how tree-search with a learned value function can guide LLMs' decoding ability. TS-LLM distinguishes itself in two key ways: (1) Leveraging a learned value function, our approach can be generally applied to different tasks beyond reasoning (such as RLHF alignment), and LLMs of any size, without prompting advanced, large-scale models. (2) It can guide LLM's decoding during both inference and training. Empirical evaluations across reasoning, planning, and RLHF alignment tasks validate the effectiveness of TS-LLM, even on trees with a depth of 64.
Large Sequence Models for Sequential Decision-Making: A Survey
Jun 24, 2023
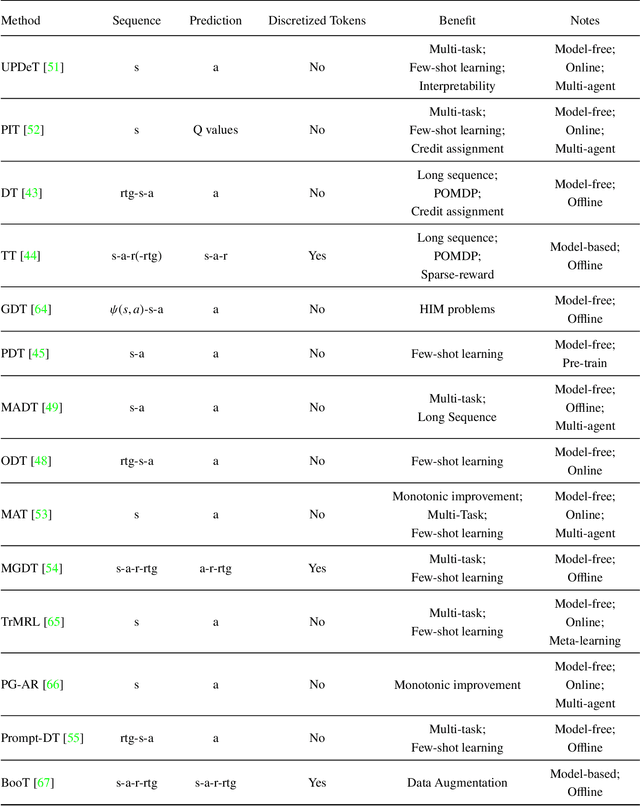
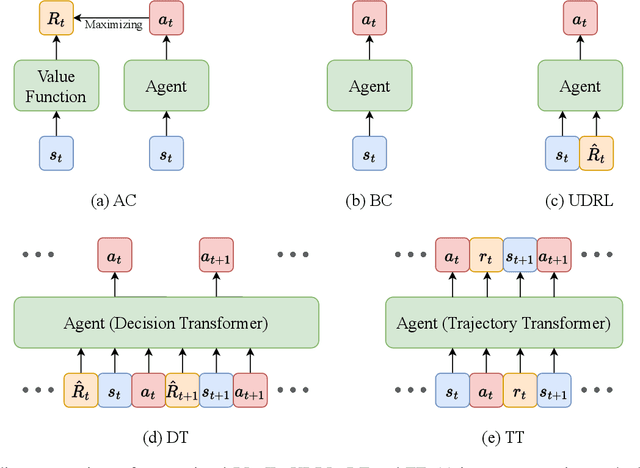
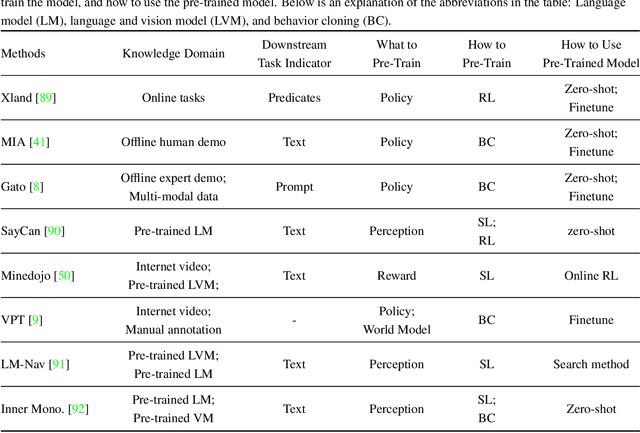
Transformer architectures have facilitated the development of large-scale and general-purpose sequence models for prediction tasks in natural language processing and computer vision, e.g., GPT-3 and Swin Transformer. Although originally designed for prediction problems, it is natural to inquire about their suitability for sequential decision-making and reinforcement learning problems, which are typically beset by long-standing issues involving sample efficiency, credit assignment, and partial observability. In recent years, sequence models, especially the Transformer, have attracted increasing interest in the RL communities, spawning numerous approaches with notable effectiveness and generalizability. This survey presents a comprehensive overview of recent works aimed at solving sequential decision-making tasks with sequence models such as the Transformer, by discussing the connection between sequential decision-making and sequence modeling, and categorizing them based on the way they utilize the Transformer. Moreover, this paper puts forth various potential avenues for future research intending to improve the effectiveness of large sequence models for sequential decision-making, encompassing theoretical foundations, network architectures, algorithms, and efficient training systems. As this article has been accepted by the Frontiers of Computer Science, here is an early version, and the most up-to-date version can be found at https://journal.hep.com.cn/fcs/EN/10.1007/s11704-023-2689-5
Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
May 30, 2022



Large sequence model (SM) such as GPT series and BERT has displayed outstanding performance and generalization capabilities on vision, language, and recently reinforcement learning tasks. A natural follow-up question is how to abstract multi-agent decision making into an SM problem and benefit from the prosperous development of SMs. In this paper, we introduce a novel architecture named Multi-Agent Transformer (MAT) that effectively casts cooperative multi-agent reinforcement learning (MARL) into SM problems wherein the task is to map agents' observation sequence to agents' optimal action sequence. Our goal is to build the bridge between MARL and SMs so that the modeling power of modern sequence models can be unleashed for MARL. Central to our MAT is an encoder-decoder architecture which leverages the multi-agent advantage decomposition theorem to transform the joint policy search problem into a sequential decision making process; this renders only linear time complexity for multi-agent problems and, most importantly, endows MAT with monotonic performance improvement guarantee. Unlike prior arts such as Decision Transformer fit only pre-collected offline data, MAT is trained by online trials and errors from the environment in an on-policy fashion. To validate MAT, we conduct extensive experiments on StarCraftII, Multi-Agent MuJoCo, Dexterous Hands Manipulation, and Google Research Football benchmarks. Results demonstrate that MAT achieves superior performance and data efficiency compared to strong baselines including MAPPO and HAPPO. Furthermore, we demonstrate that MAT is an excellent few-short learner on unseen tasks regardless of changes in the number of agents. See our project page at https://sites.google.com/view/multi-agent-transformer.
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
Dec 20, 2021



Offline reinforcement learning leverages previously-collected offline datasets to learn optimal policies with no necessity to access the real environment. Such a paradigm is also desirable for multi-agent reinforcement learning (MARL) tasks, given the increased interactions among agents and with the enviroment. Yet, in MARL, the paradigm of offline pre-training with online fine-tuning has not been studied, nor datasets or benchmarks for offline MARL research are available. In this paper, we facilitate the research by providing large-scale datasets, and use them to examine the usage of the Decision Transformer in the context of MARL. We investigate the generalisation of MARL offline pre-training in the following three aspects: 1) between single agents and multiple agents, 2) from offline pretraining to the online fine-tuning, and 3) to that of multiple downstream tasks with few-shot and zero-shot capabilities. We start by introducing the first offline MARL dataset with diverse quality levels based on the StarCraftII environment, and then propose the novel architecture of multi-agent decision transformer (MADT) for effective offline learning. MADT leverages transformer's modelling ability of sequence modelling and integrates it seamlessly with both offline and online MARL tasks. A crucial benefit of MADT is that it learns generalizable policies that can transfer between different types of agents under different task scenarios. On StarCraft II offline dataset, MADT outperforms the state-of-the-art offline RL baselines. When applied to online tasks, the pre-trained MADT significantly improves sample efficiency, and enjoys strong performance both few-short and zero-shot cases. To our best knowledge, this is the first work that studies and demonstrates the effectiveness of offline pre-trained models in terms of sample efficiency and generalisability enhancements in MARL.
Settling the Variance of Multi-Agent Policy Gradients
Aug 20, 2021


Policy gradient (PG) methods are popular reinforcement learning (RL) methods where a baseline is often applied to reduce the variance of gradient estimates. In multi-agent RL (MARL), although the PG theorem can be naturally extended, the effectiveness of multi-agent PG (MAPG) methods degrades as the variance of gradient estimates increases rapidly with the number of agents. In this paper, we offer a rigorous analysis of MAPG methods by, firstly, quantifying the contributions of the number of agents and agents' explorations to the variance of MAPG estimators. Based on this analysis, we derive the optimal baseline (OB) that achieves the minimal variance. In comparison to the OB, we measure the excess variance of existing MARL algorithms such as vanilla MAPG and COMA. Considering using deep neural networks, we also propose a surrogate version of OB, which can be seamlessly plugged into any existing PG methods in MARL. On benchmarks of Multi-Agent MuJoCo and StarCraft challenges, our OB technique effectively stabilises training and improves the performance of multi-agent PPO and COMA algorithms by a significant margin.
MALib: A Parallel Framework for Population-based Multi-agent Reinforcement Learning
Jun 05, 2021



Population-based multi-agent reinforcement learning (PB-MARL) refers to the series of methods nested with reinforcement learning (RL) algorithms, which produces a self-generated sequence of tasks arising from the coupled population dynamics. By leveraging auto-curricula to induce a population of distinct emergent strategies, PB-MARL has achieved impressive success in tackling multi-agent tasks. Despite remarkable prior arts of distributed RL frameworks, PB-MARL poses new challenges for parallelizing the training frameworks due to the additional complexity of multiple nested workloads between sampling, training and evaluation involved with heterogeneous policy interactions. To solve these problems, we present MALib, a scalable and efficient computing framework for PB-MARL. Our framework is comprised of three key components: (1) a centralized task dispatching model, which supports the self-generated tasks and scalable training with heterogeneous policy combinations; (2) a programming architecture named Actor-Evaluator-Learner, which achieves high parallelism for both training and sampling, and meets the evaluation requirement of auto-curriculum learning; (3) a higher-level abstraction of MARL training paradigms, which enables efficient code reuse and flexible deployments on different distributed computing paradigms. Experiments on a series of complex tasks such as multi-agent Atari Games show that MALib achieves throughput higher than 40K FPS on a single machine with $32$ CPU cores; 5x speedup than RLlib and at least 3x speedup than OpenSpiel in multi-agent training tasks. MALib is publicly available at https://github.com/sjtu-marl/malib.