 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Your Models Still Fair? Fairness Attacks on Graph Neural Networks via Node Injections
Jun 05, 2024Despite the remarkable capabilities demonstrated by Graph Neural Networks (GNNs) in graph-related tasks, recent research has revealed the fairness vulnerabilities in GNNs when facing malicious adversarial attacks. However, all existing fairness attacks require manipulating the connectivity between existing nodes, which may be prohibited in reality. To this end, we introduce a Node Injection-based Fairness Attack (NIFA), exploring the vulnerabilities of GNN fairness in such a more realistic setting. In detail, NIFA first designs two insightful principles for node injection operations, namely the uncertainty-maximization principle and homophily-increase principle, and then optimizes injected nodes' feature matrix to further ensure the effectiveness of fairness attacks. Comprehensive experiments on three real-world datasets consistently demonstrate that NIFA can significantly undermine the fairness of mainstream GNNs, even including fairness-aware GNNs, by injecting merely 1% of nodes. We sincerely hope that our work can stimulate increasing attention from researchers on the vulnerability of GNN fairness, and encourage the development of corresponding defense mechanisms.
Evaluating LLMs at Evaluating Temporal Generalization
May 14, 2024The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
Vector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
Structure-aware Fine-tuning for Code Pre-trained Models
Apr 11, 2024Over the past few years, we have witnessed remarkable advancements in Code Pre-trained Models (CodePTMs). These models achieved excellent representation capabilities by designing structure-based pre-training tasks for code. However, how to enhance the absorption of structural knowledge when fine-tuning CodePTMs still remains a significant challenge. To fill this gap, in this paper, we present Structure-aware Fine-tuning (SAT), a novel structure-enhanced and plug-and-play fine-tuning method for CodePTMs. We first propose a structure loss to quantify the difference between the information learned by CodePTMs and the knowledge extracted from code structure. Specifically, we use the attention scores extracted from Transformer layer as the learned structural information, and the shortest path length between leaves in abstract syntax trees as the structural knowledge. Subsequently, multi-task learning is introduced to improve the performance of fine-tuning. Experiments conducted on four pre-trained models and two generation tasks demonstrate the effectiveness of our proposed method as a plug-and-play solution. Furthermore, we observed that SAT can benefit CodePTMs more with limited training data.
Decoy Effect In Search Interaction: Understanding User Behavior and Measuring System Vulnerability
Mar 27, 2024

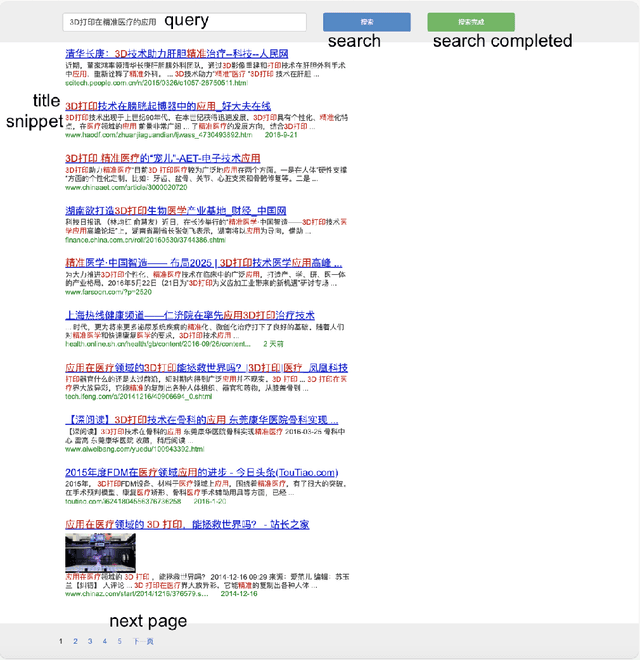
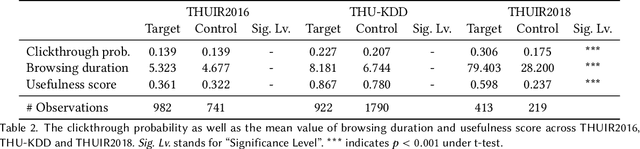
This study examines the decoy effect's underexplored influence on user search interactions and methods for measuring information retrieval (IR) systems' vulnerability to this effect. It explores how decoy results alter users' interactions on search engine result pages, focusing on metrics like click-through likelihood, browsing time, and perceived document usefulness. By analyzing user interaction logs from multiple datasets, the study demonstrates that decoy results significantly affect users' behavior and perceptions. Furthermore, it investigates how different levels of task difficulty and user knowledge modify the decoy effect's impact, finding that easier tasks and lower knowledge levels lead to higher engagement with target documents. In terms of IR system evaluation, the study introduces the DEJA-VU metric to assess systems' susceptibility to the decoy effect, testing it on specific retrieval tasks. The results show differences in systems' effectiveness and vulnerability, contributing to our understanding of cognitive biases in search behavior and suggesting pathways for creating more balanced and bias-aware IR evaluations.
Vision-Based Dexterous Motion Planning by Dynamic Movement Primitives with Human Hand Demonstration
Mar 25, 2024This paper proposes a vision-based framework for a 7-degree-of-freedom robotic manipulator, with the primary objective of facilitating its capacity to acquire information from human hand demonstrations for the execution of dexterous pick-and-place tasks. Most existing works only focus on the position demonstration without considering the orientations. In this paper, by employing a single depth camera, MediaPipe is applied to generate the three-dimensional coordinates of a human hand, thereby comprehensively recording the hand's motion, encompassing the trajectory of the wrist, orientation of the hand, and the grasp motion. A mean filter is applied during data pre-processing to smooth the raw data. The demonstration is designed to pick up an object at a specific angle, navigate around obstacles in its path and subsequently, deposit it within a sloped container. The robotic system demonstrates its learning capabilities, facilitated by the implementation of Dynamic Movement Primitives, enabling the assimilation of user actions into its trajectories with different start and end poi
Apollo: An Lightweight Multilingual Medical LLM towards Democratizing Medical AI to 6B People
Mar 09, 2024
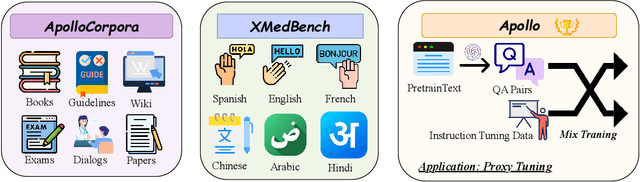
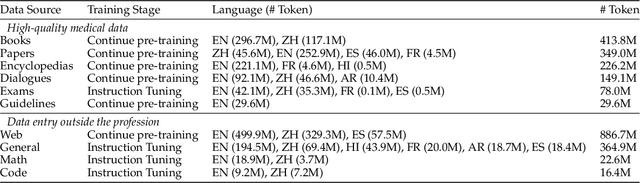

Despite the vast repository of global medical knowledge predominantly being in English, local languages are crucial for delivering tailored healthcare services, particularly in areas with limited medical resources. To extend the reach of medical AI advancements to a broader population, we aim to develop medical LLMs across the six most widely spoken languages, encompassing a global population of 6.1 billion. This effort culminates in the creation of the ApolloCorpora multilingual medical dataset and the XMedBench benchmark. In the multilingual medical benchmark, the released Apollo models, at various relatively-small sizes (i.e., 0.5B, 1.8B, 2B, 6B, and 7B), achieve the best performance among models of equivalent size. Especially, Apollo-7B is the state-of-the-art multilingual medical LLMs up to 70B. Additionally, these lite models could be used to improve the multi-lingual medical capabilities of larger models without fine-tuning in a proxy-tuning fashion. We will open-source training corpora, code, model weights and evaluation benchmark.
GraphWiz: An Instruction-Following Language Model for Graph Problems
Mar 06, 2024Large language models (LLMs) have achieved impressive success across several fields, but their proficiency in understanding and resolving complex graph problems is less explored. To bridge this gap, we introduce GraphInstruct, a novel and comprehensive instruction-tuning dataset designed to equip language models with the ability to tackle a broad spectrum of graph problems using explicit reasoning paths. Utilizing GraphInstruct, we build GraphWiz, an open-source language model capable of resolving various graph problem types while generating clear reasoning processes. To enhance the model's capability and reliability, we incorporate the Direct Preference Optimization (DPO) framework into the graph problem-solving context. The enhanced model, GraphWiz-DPO, achieves an average accuracy of 65% across nine tasks with different complexity levels, surpassing GPT-4 which has an average accuracy of 43.8%. Moreover, our research delves into the delicate balance between training data volume and model performance, highlighting the potential for overfitting with increased data. We also explore the transferability of the model's reasoning ability across different graph tasks, indicating the model's adaptability and practical application potential. Our investigation offers a new blueprint and valuable insights for developing LLMs specialized in graph reasoning and problem-solving.
Compress to Impress: Unleashing the Potential of Compressive Memory in Real-World Long-Term Conversations
Feb 19, 2024Existing retrieval-based methods have made significant strides in maintaining long-term conversations. However, these approaches face challenges in memory database management and accurate memory retrieval, hindering their efficacy in dynamic, real-world interactions. This study introduces a novel framework, COmpressive Memory-Enhanced Dialogue sYstems (COMEDY), which eschews traditional retrieval modules and memory databases. Instead, COMEDY adopts a ''One-for-All'' approach, utilizing a single language model to manage memory generation, compression, and response generation. Central to this framework is the concept of compressive memory, which intergrates session-specific summaries, user-bot dynamics, and past events into a concise memory format. To support COMEDY, we curated a large-scale Chinese instruction-tuning dataset, Dolphin, derived from real user-chatbot interactions. Comparative evaluations demonstrate COMEDY's superiority over traditional retrieval-based methods in producing more nuanced and human-like conversational experiences. Our codes are available at https://github.com/nuochenpku/COMEDY.
Beyond Surface: Probing LLaMA Across Scales and Layers
Dec 14, 2023This paper presents an in-depth analysis of Large Language Models (LLMs), focusing on LLaMA, a prominent open-source foundational model in natural language processing. Instead of assessing LLaMA through its generative output, we design multiple-choice tasks to probe its intrinsic understanding in high-order tasks such as reasoning and computation. We examine the model horizontally, comparing different sizes, and vertically, assessing different layers. We unveil several key and uncommon findings based on the designed probing tasks: (1) Horizontally, enlarging model sizes almost could not automatically impart additional knowledge or computational prowess. Instead, it can enhance reasoning abilities, especially in math problem solving, and helps reduce hallucinations, but only beyond certain size thresholds; (2) In vertical analysis, the lower layers of LLaMA lack substantial arithmetic and factual knowledge, showcasing logical thinking, multilingual and recognitive abilities, with top layers housing most computational power and real-world knowledge.