 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanacea: Pareto Alignment via Preference Adaptation for LLMs
Feb 03, 2024Current methods for large language model alignment typically use scalar human preference labels. However, this convention tends to oversimplify the multi-dimensional and heterogeneous nature of human preferences, leading to reduced expressivity and even misalignment. This paper presents Panacea, an innovative approach that reframes alignment as a multi-dimensional preference optimization problem. Panacea trains a single model capable of adapting online and Pareto-optimally to diverse sets of preferences without the need for further tuning. A major challenge here is using a low-dimensional preference vector to guide the model's behavior, despite it being governed by an overwhelmingly large number of parameters. To address this, Panacea is designed to use singular value decomposition (SVD)-based low-rank adaptation, which allows the preference vector to be simply injected online as singular values. Theoretically, we prove that Panacea recovers the entire Pareto front with common loss aggregation methods under mild conditions. Moreover, our experiments demonstrate, for the first time, the feasibility of aligning a single LLM to represent a spectrum of human preferences through various optimization methods. Our work marks a step forward in effectively and efficiently aligning models to diverse and intricate human preferences in a controllable and Pareto-optimal manner.
Facing the Elephant in the Room: Visual Prompt Tuning or Full Finetuning?
Jan 23, 2024As the scale of vision models continues to grow, the emergence of Visual Prompt Tuning (VPT) as a parameter-efficient transfer learning technique has gained attention due to its superior performance compared to traditional full-finetuning. However, the conditions favoring VPT (the ``when") and the underlying rationale (the ``why") remain unclear. In this paper, we conduct a comprehensive analysis across 19 distinct datasets and tasks. To understand the ``when" aspect, we identify the scenarios where VPT proves favorable by two dimensions: task objectives and data distributions. We find that VPT is preferrable when there is 1) a substantial disparity between the original and the downstream task objectives (e.g., transitioning from classification to counting), or 2) a similarity in data distributions between the two tasks (e.g., both involve natural images). In exploring the ``why" dimension, our results indicate VPT's success cannot be attributed solely to overfitting and optimization considerations. The unique way VPT preserves original features and adds parameters appears to be a pivotal factor. Our study provides insights into VPT's mechanisms, and offers guidance for its optimal utilization.
CivRealm: A Learning and Reasoning Odyssey in Civilization for Decision-Making Agents
Jan 19, 2024The generalization of decision-making agents encompasses two fundamental elements: learning from past experiences and reasoning in novel contexts. However, the predominant emphasis in most interactive environments is on learning, often at the expense of complexity in reasoning. In this paper, we introduce CivRealm, an environment inspired by the Civilization game. Civilization's profound alignment with human history and society necessitates sophisticated learning, while its ever-changing situations demand strong reasoning to generalize. Particularly, CivRealm sets up an imperfect-information general-sum game with a changing number of players; it presents a plethora of complex features, challenging the agent to deal with open-ended stochastic environments that require diplomacy and negotiation skills. Within CivRealm, we provide interfaces for two typical agent types: tensor-based agents that focus on learning, and language-based agents that emphasize reasoning. To catalyze further research, we present initial results for both paradigms. The canonical RL-based agents exhibit reasonable performance in mini-games, whereas both RL- and LLM-based agents struggle to make substantial progress in the full game. Overall, CivRealm stands as a unique learning and reasoning challenge for decision-making agents. The code is available at https://github.com/bigai-ai/civrealm.
Avalon's Game of Thoughts: Battle Against Deception through Recursive Contemplation
Oct 06, 2023



Recent breakthroughs in large language models (LLMs) have brought remarkable success in the field of LLM-as-Agent. Nevertheless, a prevalent assumption is that the information processed by LLMs is consistently honest, neglecting the pervasive deceptive or misleading information in human society and AI-generated content. This oversight makes LLMs susceptible to malicious manipulations, potentially resulting in detrimental outcomes. This study utilizes the intricate Avalon game as a testbed to explore LLMs' potential in deceptive environments. Avalon, full of misinformation and requiring sophisticated logic, manifests as a "Game-of-Thoughts". Inspired by the efficacy of humans' recursive thinking and perspective-taking in the Avalon game, we introduce a novel framework, Recursive Contemplation (ReCon), to enhance LLMs' ability to identify and counteract deceptive information. ReCon combines formulation and refinement contemplation processes; formulation contemplation produces initial thoughts and speech, while refinement contemplation further polishes them. Additionally, we incorporate first-order and second-order perspective transitions into these processes respectively. Specifically, the first-order allows an LLM agent to infer others' mental states, and the second-order involves understanding how others perceive the agent's mental state. After integrating ReCon with different LLMs, extensive experiment results from the Avalon game indicate its efficacy in aiding LLMs to discern and maneuver around deceptive information without extra fine-tuning and data. Finally, we offer a possible explanation for the efficacy of ReCon and explore the current limitations of LLMs in terms of safety, reasoning, speaking style, and format, potentially furnishing insights for subsequent research.
CodeApex: A Bilingual Programming Evaluation Benchmark for Large Language Models
Sep 10, 2023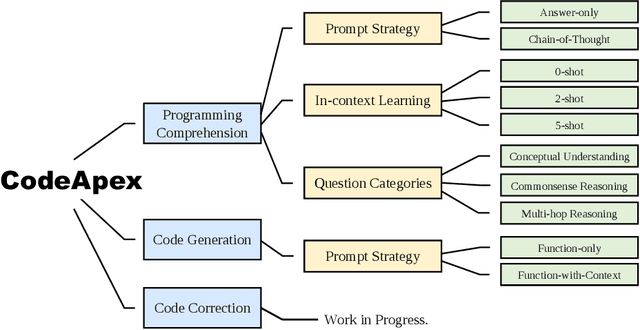
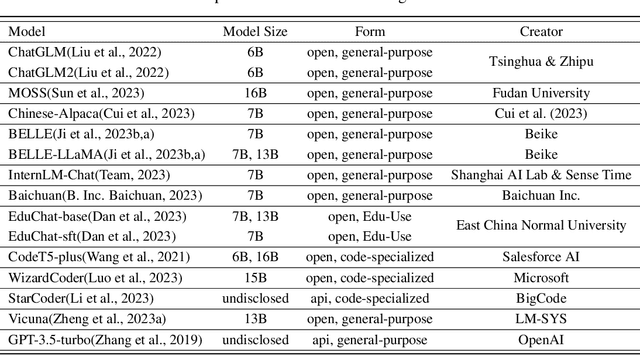

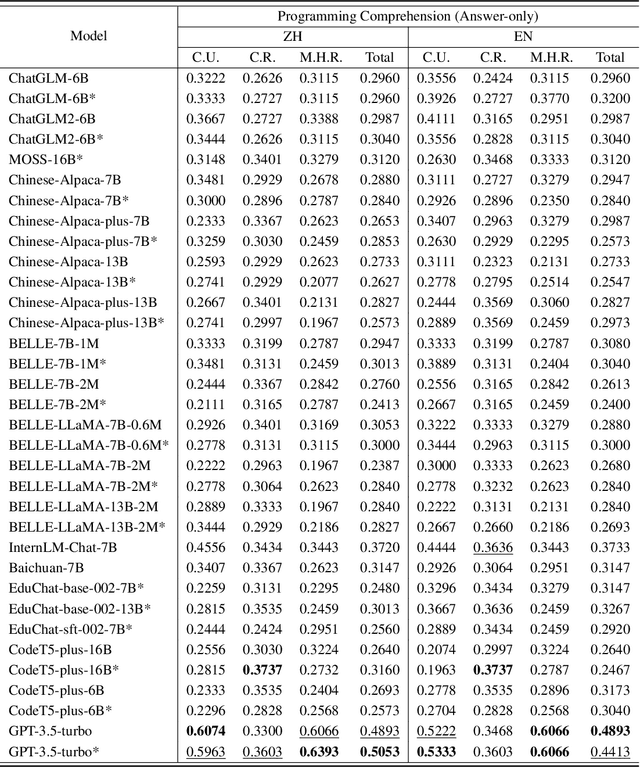
With the emergence of Large Language Models (LLMs), there has been a significant improvement in the programming capabilities of models, attracting growing attention from researchers. We propose CodeApex, a bilingual benchmark dataset focusing on the programming comprehension and code generation abilities of LLMs. CodeApex comprises three types of multiple-choice questions: conceptual understanding, commonsense reasoning, and multi-hop reasoning, designed to evaluate LLMs on programming comprehension tasks. Additionally, CodeApex utilizes algorithmic questions and corresponding test cases to assess the code quality generated by LLMs. We evaluate 14 state-of-the-art LLMs, including both general-purpose and specialized models. GPT exhibits the best programming capabilities, achieving approximate accuracies of 50% and 56% on the two tasks, respectively. There is still significant room for improvement in programming tasks. We hope that CodeApex can serve as a reference for evaluating the coding capabilities of LLMs, further promoting their development and growth. Datasets are released at https://github.com/APEXLAB/CodeApex.git. CodeApex submission website is https://apex.sjtu.edu.cn/codeapex/.
E^2VPT: An Effective and Efficient Approach for Visual Prompt Tuning
Jul 25, 2023



As the size of transformer-based models continues to grow, fine-tuning these large-scale pretrained vision models for new tasks has become increasingly parameter-intensive. Parameter-efficient learning has been developed to reduce the number of tunable parameters during fine-tuning. Although these methods show promising results, there is still a significant performance gap compared to full fine-tuning. To address this challenge, we propose an Effective and Efficient Visual Prompt Tuning (E^2VPT) approach for large-scale transformer-based model adaptation. Specifically, we introduce a set of learnable key-value prompts and visual prompts into self-attention and input layers, respectively, to improve the effectiveness of model fine-tuning. Moreover, we design a prompt pruning procedure to systematically prune low importance prompts while preserving model performance, which largely enhances the model's efficiency. Empirical results demonstrate that our approach outperforms several state-of-the-art baselines on two benchmarks, with considerably low parameter usage (e.g., 0.32% of model parameters on VTAB-1k). Our code is available at https://github.com/ChengHan111/E2VPT.
Heterogeneous Value Evaluation for Large Language Models
Jun 01, 2023



The emergent capabilities of Large Language Models (LLMs) have made it crucial to align their values with those of humans. Current methodologies typically attempt alignment with a homogeneous human value and requires human verification, yet lack consensus on the desired aspect and depth of alignment and resulting human biases. In this paper, we propose A2EHV, an Automated Alignment Evaluation with a Heterogeneous Value system that (1) is automated to minimize individual human biases, and (2) allows assessments against various target values to foster heterogeneous agents. Our approach pivots on the concept of value rationality, which represents the ability for agents to execute behaviors that satisfy a target value the most. The quantification of value rationality is facilitated by the Social Value Orientation framework from social psychology, which partitions the value space into four categories to assess social preferences from agents' behaviors. We evaluate the value rationality of eight mainstream LLMs and observe that large models are more inclined to align neutral values compared to those with strong personal values. By examining the behavior of these LLMs, we contribute to a deeper understanding of value alignment within a heterogeneous value system.
Dark, Beyond Deep: A Paradigm Shift to Cognitive AI with Humanlike Common Sense
Apr 20, 2020



Recent progress in deep learning is essentially based on a "big data for small tasks" paradigm, under which massive amounts of data are used to train a classifier for a single narrow task. In this paper, we call for a shift that flips this paradigm upside down. Specifically, we propose a "small data for big tasks" paradigm, wherein a single artificial intelligence (AI) system is challenged to develop "common sense", enabling it to solve a wide range of tasks with little training data. We illustrate the potential power of this new paradigm by reviewing models of common sense that synthesize recent breakthroughs in both machine and human vision. We identify functionality, physics, intent, causality, and utility (FPICU) as the five core domains of cognitive AI with humanlike common sense. When taken as a unified concept, FPICU is concerned with the questions of "why" and "how", beyond the dominant "what" and "where" framework for understanding vision. They are invisible in terms of pixels but nevertheless drive the creation, maintenance, and development of visual scenes. We therefore coin them the "dark matter" of vision. Just as our universe cannot be understood by merely studying observable matter, we argue that vision cannot be understood without studying FPICU. We demonstrate the power of this perspective to develop cognitive AI systems with humanlike common sense by showing how to observe and apply FPICU with little training data to solve a wide range of challenging tasks, including tool use, planning, utility inference, and social learning. In summary, we argue that the next generation of AI must embrace "dark" humanlike common sense for solving novel tasks.
* For high quality figures, please refer to http://wellyzhang.github.io/attach/dark.pdf
Cascaded Human-Object Interaction Recognition
Mar 11, 2020



Rapid progress has been witnessed for human-object interaction (HOI) recognition, but most existing models are confined to single-stage reasoning pipelines. Considering the intrinsic complexity of the task, we introduce a cascade architecture for a multi-stage, coarse-to-fine HOI understanding. At each stage, an instance localization network progressively refines HOI proposals and feeds them into an interaction recognition network. Each of the two networks is also connected to its predecessor at the previous stage, enabling cross-stage information propagation. The interaction recognition network has two crucial parts: a relation ranking module for high-quality HOI proposal selection and a triple-stream classifier for relation prediction. With our carefully-designed human-centric relation features, these two modules work collaboratively towards effective interaction understanding. Further beyond relation detection on a bounding-box level, we make our framework flexible to perform fine-grained pixel-wise relation segmentation; this provides a new glimpse into better relation modeling. Our approach reached the $1^{st}$ place in the ICCV2019 Person in Context Challenge, on both relation detection and segmentation tasks. It also shows promising results on V-COCO.
Learning Compositional Neural Information Fusion for Human Parsing
Jan 19, 2020



This work proposes to combine neural networks with the compositional hierarchy of human bodies for efficient and complete human parsing. We formulate the approach as a neural information fusion framework. Our model assembles the information from three inference processes over the hierarchy: direct inference (directly predicting each part of a human body using image information), bottom-up inference (assembling knowledge from constituent parts), and top-down inference (leveraging context from parent nodes). The bottom-up and top-down inferences explicitly model the compositional and decompositional relations in human bodies, respectively. In addition, the fusion of multi-source information is conditioned on the inputs, i.e., by estimating and considering the confidence of the sources. The whole model is end-to-end differentiable, explicitly modeling information flows and structures. Our approach is extensively evaluated on four popular datasets, outperforming the state-of-the-arts in all cases, with a fast processing speed of 23fps. Our code and results have been released to help ease future research in this direction.
* ICCV2019. Websie: https://github.com/ZzzjzzZ/CompositionalHumanParsing