 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering LLM-Generated Code: A Zero-Shot Synthetic Code Detector via Code Rewriting
May 30, 2024Large Language Models (LLMs) have exhibited remarkable proficiency in generating code. However, the misuse of LLM-generated (Synthetic) code has prompted concerns within both educational and industrial domains, highlighting the imperative need for the development of synthetic code detectors. Existing methods for detecting LLM-generated content are primarily tailored for general text and often struggle with code content due to the distinct grammatical structure of programming languages and massive "low-entropy" tokens. Building upon this, our work proposes a novel zero-shot synthetic code detector based on the similarity between the code and its rewritten variants. Our method relies on the intuition that the differences between the LLM-rewritten and original codes tend to be smaller when the original code is synthetic. We utilize self-supervised contrastive learning to train a code similarity model and assess our approach on two synthetic code detection benchmarks. Our results demonstrate a notable enhancement over existing synthetic content detectors designed for general texts, with an improvement of 20.5% in the APPS benchmark and 29.1% in the MBPP benchmark.
LLMs Meet Multimodal Generation and Editing: A Survey
May 29, 2024With the recent advancement in large language models (LLMs), there is a growing interest in combining LLMs with multimodal learning. Previous surveys of multimodal large language models (MLLMs) mainly focus on understanding. This survey elaborates on multimodal generation across different domains, including image, video, 3D, and audio, where we highlight the notable advancements with milestone works in these fields. Specifically, we exhaustively investigate the key technical components behind methods and multimodal datasets utilized in these studies. Moreover, we dig into tool-augmented multimodal agents that can use existing generative models for human-computer interaction. Lastly, we also comprehensively discuss the advancement in AI safety and investigate emerging applications as well as future prospects. Our work provides a systematic and insightful overview of multimodal generation, which is expected to advance the development of Artificial Intelligence for Generative Content (AIGC) and world models. A curated list of all related papers can be found at https://github.com/YingqingHe/Awesome-LLMs-meet-Multimodal-Generation
S-Eval: Automatic and Adaptive Test Generation for Benchmarking Safety Evaluation of Large Language Models
May 28, 2024Large Language Models have gained considerable attention for their revolutionary capabilities. However, there is also growing concern on their safety implications, making a comprehensive safety evaluation for LLMs urgently needed before model deployment. In this work, we propose S-Eval, a new comprehensive, multi-dimensional and open-ended safety evaluation benchmark. At the core of S-Eval is a novel LLM-based automatic test prompt generation and selection framework, which trains an expert testing LLM Mt combined with a range of test selection strategies to automatically construct a high-quality test suite for the safety evaluation. The key to the automation of this process is a novel expert safety-critique LLM Mc able to quantify the riskiness score of an LLM's response, and additionally produce risk tags and explanations. Besides, the generation process is also guided by a carefully designed risk taxonomy with four different levels, covering comprehensive and multi-dimensional safety risks of concern. Based on these, we systematically construct a new and large-scale safety evaluation benchmark for LLMs consisting of 220,000 evaluation prompts, including 20,000 base risk prompts (10,000 in Chinese and 10,000 in English) and 200,000 corresponding attack prompts derived from 10 popular adversarial instruction attacks against LLMs. Moreover, considering the rapid evolution of LLMs and accompanied safety threats, S-Eval can be flexibly configured and adapted to include new risks, attacks and models. S-Eval is extensively evaluated on 20 popular and representative LLMs. The results confirm that S-Eval can better reflect and inform the safety risks of LLMs compared to existing benchmarks. We also explore the impacts of parameter scales, language environments, and decoding parameters on the evaluation, providing a systematic methodology for evaluating the safety of LLMs.
How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites
Apr 29, 2024



In this report, we introduce InternVL 1.5, an open-source multimodal large language model (MLLM) to bridge the capability gap between open-source and proprietary commercial models in multimodal understanding. We introduce three simple improvements: (1) Strong Vision Encoder: we explored a continuous learning strategy for the large-scale vision foundation model -- InternViT-6B, boosting its visual understanding capabilities, and making it can be transferred and reused in different LLMs. (2) Dynamic High-Resolution: we divide images into tiles ranging from 1 to 40 of 448$\times$448 pixels according to the aspect ratio and resolution of the input images, which supports up to 4K resolution input. (3) High-Quality Bilingual Dataset: we carefully collected a high-quality bilingual dataset that covers common scenes, document images, and annotated them with English and Chinese question-answer pairs, significantly enhancing performance in OCR- and Chinese-related tasks. We evaluate InternVL 1.5 through a series of benchmarks and comparative studies. Compared to both open-source and proprietary models, InternVL 1.5 shows competitive performance, achieving state-of-the-art results in 8 of 18 benchmarks. Code has been released at https://github.com/OpenGVLab/InternVL.
InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
Apr 09, 2024The Large Vision-Language Model (LVLM) field has seen significant advancements, yet its progression has been hindered by challenges in comprehending fine-grained visual content due to limited resolution. Recent efforts have aimed to enhance the high-resolution understanding capabilities of LVLMs, yet they remain capped at approximately 1500 x 1500 pixels and constrained to a relatively narrow resolution range. This paper represents InternLM-XComposer2-4KHD, a groundbreaking exploration into elevating LVLM resolution capabilities up to 4K HD (3840 x 1600) and beyond. Concurrently, considering the ultra-high resolution may not be necessary in all scenarios, it supports a wide range of diverse resolutions from 336 pixels to 4K standard, significantly broadening its scope of applicability. Specifically, this research advances the patch division paradigm by introducing a novel extension: dynamic resolution with automatic patch configuration. It maintains the training image aspect ratios while automatically varying patch counts and configuring layouts based on a pre-trained Vision Transformer (ViT) (336 x 336), leading to dynamic training resolution from 336 pixels to 4K standard. Our research demonstrates that scaling training resolution up to 4K HD leads to consistent performance enhancements without hitting the ceiling of potential improvements. InternLM-XComposer2-4KHD shows superb capability that matches or even surpasses GPT-4V and Gemini Pro in 10 of the 16 benchmarks. The InternLM-XComposer2-4KHD model series with 7B parameters are publicly available at https://github.com/InternLM/InternLM-XComposer.
Does Knowledge Graph Really Matter for Recommender Systems?
Apr 04, 2024Recommender systems (RSs) are designed to provide personalized recommendations to users. Recently, knowledge graphs (KGs) have been widely introduced in RSs to improve recommendation accuracy. In this study, however, we demonstrate that RSs do not necessarily perform worse even if the KG is downgraded to the user-item interaction graph only (or removed). We propose an evaluation framework KG4RecEval to systematically evaluate how much a KG contributes to the recommendation accuracy of a KG-based RS, using our defined metric KGER (KG utilization efficiency in recommendation). We consider the scenarios where knowledge in a KG gets completely removed, randomly distorted and decreased, and also where recommendations are for cold-start users. Our extensive experiments on four commonly used datasets and a number of state-of-the-art KG-based RSs reveal that: to remove, randomly distort or decrease knowledge does not necessarily decrease recommendation accuracy, even for cold-start users. These findings inspire us to rethink how to better utilize knowledge from existing KGs, whereby we discuss and provide insights into what characteristics of datasets and KG-based RSs may help improve KG utilization efficiency.
Bounding Box Stability against Feature Dropout Reflects Detector Generalization across Environments
Mar 20, 2024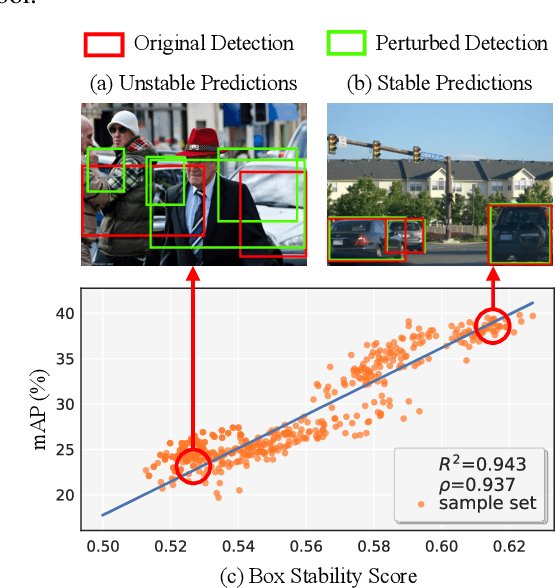
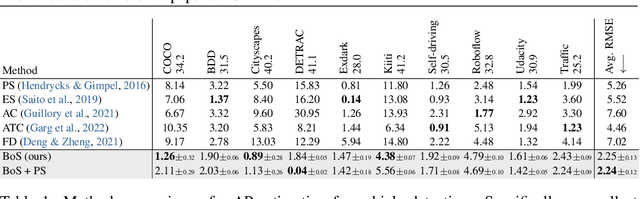
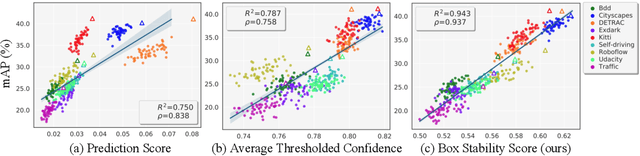
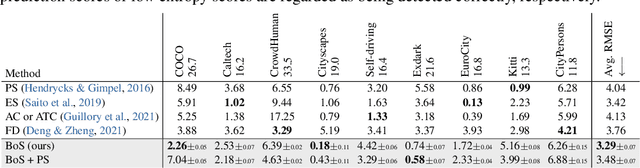
Bounding boxes uniquely characterize object detection, where a good detector gives accurate bounding boxes of categories of interest. However, in the real-world where test ground truths are not provided, it is non-trivial to find out whether bounding boxes are accurate, thus preventing us from assessing the detector generalization ability. In this work, we find under feature map dropout, good detectors tend to output bounding boxes whose locations do not change much, while bounding boxes of poor detectors will undergo noticeable position changes. We compute the box stability score (BoS score) to reflect this stability. Specifically, given an image, we compute a normal set of bounding boxes and a second set after feature map dropout. To obtain BoS score, we use bipartite matching to find the corresponding boxes between the two sets and compute the average Intersection over Union (IoU) across the entire test set. We contribute to finding that BoS score has a strong, positive correlation with detection accuracy measured by mean average precision (mAP) under various test environments. This relationship allows us to predict the accuracy of detectors on various real-world test sets without accessing test ground truths, verified on canonical detection tasks such as vehicle detection and pedestrian detection. Code and data are available at https://github.com/YangYangGirl/BoS.
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
Mar 07, 2024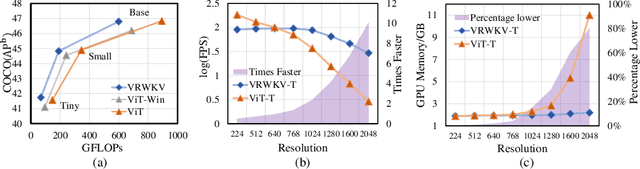

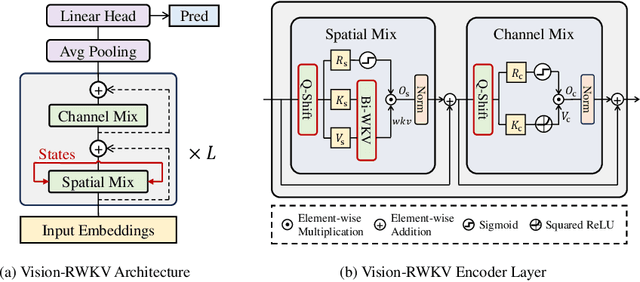
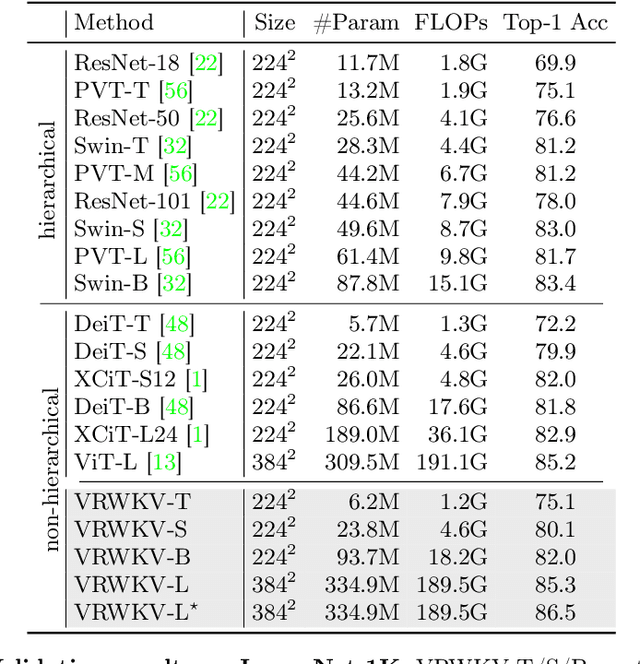
Transformers have revolutionized computer vision and natural language processing, but their high computational complexity limits their application in high-resolution image processing and long-context analysis. This paper introduces Vision-RWKV (VRWKV), a model adapted from the RWKV model used in the NLP field with necessary modifications for vision tasks. Similar to the Vision Transformer (ViT), our model is designed to efficiently handle sparse inputs and demonstrate robust global processing capabilities, while also scaling up effectively, accommodating both large-scale parameters and extensive datasets. Its distinctive advantage lies in its reduced spatial aggregation complexity, which renders it exceptionally adept at processing high-resolution images seamlessly, eliminating the necessity for windowing operations. Our evaluations demonstrate that VRWKV surpasses ViT's performance in image classification and has significantly faster speeds and lower memory usage processing high-resolution inputs. In dense prediction tasks, it outperforms window-based models, maintaining comparable speeds. These results highlight VRWKV's potential as a more efficient alternative for visual perception tasks. Code is released at \url{https://github.com/OpenGVLab/Vision-RWKV}.
The All-Seeing Project V2: Towards General Relation Comprehension of the Open World
Feb 29, 2024We present the All-Seeing Project V2: a new model and dataset designed for understanding object relations in images. Specifically, we propose the All-Seeing Model V2 (ASMv2) that integrates the formulation of text generation, object localization, and relation comprehension into a relation conversation (ReC) task. Leveraging this unified task, our model excels not only in perceiving and recognizing all objects within the image but also in grasping the intricate relation graph between them, diminishing the relation hallucination often encountered by Multi-modal Large Language Models (MLLMs). To facilitate training and evaluation of MLLMs in relation understanding, we created the first high-quality ReC dataset ({AS-V2) which is aligned with the format of standard instruction tuning data. In addition, we design a new benchmark, termed Circular-based Relation Probing Evaluation (CRPE) for comprehensively evaluating the relation comprehension capabilities of MLLMs. Notably, our ASMv2 achieves an overall accuracy of 52.04 on this relation-aware benchmark, surpassing the 43.14 of LLaVA-1.5 by a large margin. We hope that our work can inspire more future research and contribute to the evolution towards artificial general intelligence. Our project is released at https://github.com/OpenGVLab/all-seeing.
RoboCodeX: Multimodal Code Generation for Robotic Behavior Synthesis
Feb 25, 2024Robotic behavior synthesis, the problem of understanding multimodal inputs and generating precise physical control for robots, is an important part of Embodied AI. Despite successes in applying multimodal large language models for high-level understanding, it remains challenging to translate these conceptual understandings into detailed robotic actions while achieving generalization across various scenarios. In this paper, we propose a tree-structured multimodal code generation framework for generalized robotic behavior synthesis, termed RoboCodeX. RoboCodeX decomposes high-level human instructions into multiple object-centric manipulation units consisting of physical preferences such as affordance and safety constraints, and applies code generation to introduce generalization ability across various robotics platforms. To further enhance the capability to map conceptual and perceptual understanding into control commands, a specialized multimodal reasoning dataset is collected for pre-training and an iterative self-updating methodology is introduced for supervised fine-tuning. Extensive experiments demonstrate that RoboCodeX achieves state-of-the-art performance in both simulators and real robots on four different kinds of manipulation tasks and one navigation task.