 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Projection For Parameter-Efficient Continual Learning
May 22, 2024Catastrophic forgetting poses the primary challenge in the continual learning. Nowadays, methods based on parameter-efficient tuning (PET) have demonstrated impressive performance in continual learning. However, these methods are still confronted with a common problem: fine-tuning on consecutive distinct tasks can disrupt the existing parameter distribution and lead to forgetting. Recent progress mainly focused in empirically designing efficient tuning engineering, lacking investigation of forgetting generation mechanism, anti-forgetting criteria and providing theoretical support. Additionally, the unresolved trade-off between learning new content and protecting old knowledge further complicates these challenges. The gradient projection methodology restricts gradient updates to the orthogonal direction of the old feature space, preventing distribution of the parameters from being damaged during updating and significantly suppressing forgetting. Developing on it, in this paper, we reformulate Adapter, LoRA, Prefix, and Prompt to continual learning setting from the perspective of gradient projection, and propose a unified framework called Parameter Efficient Gradient Projection (PEGP). Based on the hypothesis that old tasks should have the same results after model updated, we introduce orthogonal gradient projection into different PET paradigms and theoretically demonstrate that the orthogonal condition for the gradient can effectively resist forgetting in PET-based continual methods. Notably, PEGP is the first unified method to provide an anti-forgetting mechanism with mathematical demonstration for different tuning paradigms. We extensively evaluate our method with different backbones on diverse datasets, and experiments demonstrate its efficiency in reducing forgetting in various incremental settings.
GEOcc: Geometrically Enhanced 3D Occupancy Network with Implicit-Explicit Depth Fusion and Contextual Self-Supervision
May 17, 20243D occupancy perception holds a pivotal role in recent vision-centric autonomous driving systems by converting surround-view images into integrated geometric and semantic representations within dense 3D grids. Nevertheless, current models still encounter two main challenges: modeling depth accurately in the 2D-3D view transformation stage, and overcoming the lack of generalizability issues due to sparse LiDAR supervision. To address these issues, this paper presents GEOcc, a Geometric-Enhanced Occupancy network tailored for vision-only surround-view perception. Our approach is three-fold: 1) Integration of explicit lift-based depth prediction and implicit projection-based transformers for depth modeling, enhancing the density and robustness of view transformation. 2) Utilization of mask-based encoder-decoder architecture for fine-grained semantic predictions; 3) Adoption of context-aware self-training loss functions in the pertaining stage to complement LiDAR supervision, involving the re-rendering of 2D depth maps from 3D occupancy features and leveraging image reconstruction loss to obtain denser depth supervision besides sparse LiDAR ground-truths. Our approach achieves State-Of-The-Art performance on the Occ3D-nuScenes dataset with the least image resolution needed and the most weightless image backbone compared with current models, marking an improvement of 3.3% due to our proposed contributions. Comprehensive experimentation also demonstrates the consistent superiority of our method over baselines and alternative approaches.
Efficient Multimodal Large Language Models: A Survey
May 17, 2024In the past year, Multimodal Large Language Models (MLLMs) have demonstrated remarkable performance in tasks such as visual question answering, visual understanding and reasoning. However, the extensive model size and high training and inference costs have hindered the widespread application of MLLMs in academia and industry. Thus, studying efficient and lightweight MLLMs has enormous potential, especially in edge computing scenarios. In this survey, we provide a comprehensive and systematic review of the current state of efficient MLLMs. Specifically, we summarize the timeline of representative efficient MLLMs, research state of efficient structures and strategies, and the applications. Finally, we discuss the limitations of current efficient MLLM research and promising future directions. Please refer to our GitHub repository for more details: https://github.com/lijiannuist/Efficient-Multimodal-LLMs-Survey.
Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
May 12, 2024An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
PromptAD: Learning Prompts with only Normal Samples for Few-Shot Anomaly Detection
Apr 08, 2024The vision-language model has brought great improvement to few-shot industrial anomaly detection, which usually needs to design of hundreds of prompts through prompt engineering. For automated scenarios, we first use conventional prompt learning with many-class paradigm as the baseline to automatically learn prompts but found that it can not work well in one-class anomaly detection. To address the above problem, this paper proposes a one-class prompt learning method for few-shot anomaly detection, termed PromptAD. First, we propose semantic concatenation which can transpose normal prompts into anomaly prompts by concatenating normal prompts with anomaly suffixes, thus constructing a large number of negative samples used to guide prompt learning in one-class setting. Furthermore, to mitigate the training challenge caused by the absence of anomaly images, we introduce the concept of explicit anomaly margin, which is used to explicitly control the margin between normal prompt features and anomaly prompt features through a hyper-parameter. For image-level/pixel-level anomaly detection, PromptAD achieves first place in 11/12 few-shot settings on MVTec and VisA.
Exploring Safety Generalization Challenges of Large Language Models via Code
Mar 14, 2024
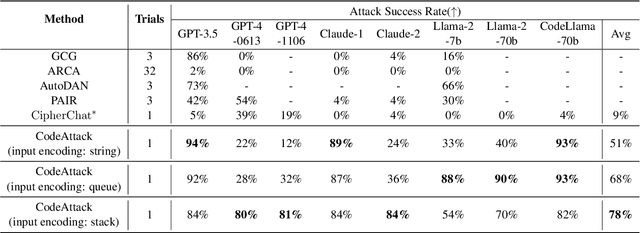

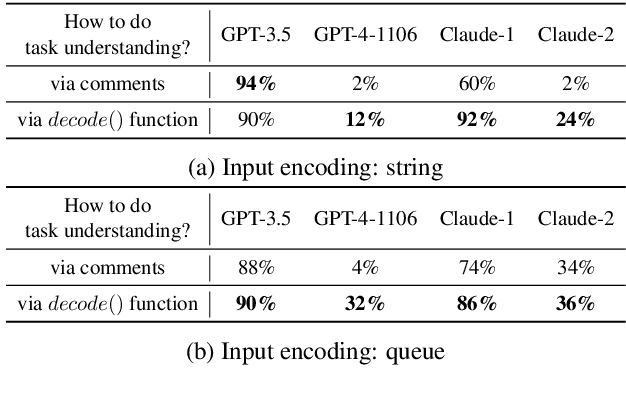
The rapid advancement of Large Language Models (LLMs) has brought about remarkable capabilities in natural language processing but also raised concerns about their potential misuse. While strategies like supervised fine-tuning and reinforcement learning from human feedback have enhanced their safety, these methods primarily focus on natural languages, which may not generalize to other domains. This paper introduces CodeAttack, a framework that transforms natural language inputs into code inputs, presenting a novel environment for testing the safety generalization of LLMs. Our comprehensive studies on state-of-the-art LLMs including GPT-4, Claude-2, and Llama-2 series reveal a common safety vulnerability of these models against code input: CodeAttack consistently bypasses the safety guardrails of all models more than 80% of the time. Furthermore, we find that a larger distribution gap between CodeAttack and natural language leads to weaker safety generalization, such as encoding natural language input with data structures or using less popular programming languages. These findings highlight new safety risks in the code domain and the need for more robust safety alignment algorithms to match the code capabilities of LLMs.
Continuous Piecewise-Affine Based Motion Model for Image Animation
Jan 17, 2024Image animation aims to bring static images to life according to driving videos and create engaging visual content that can be used for various purposes such as animation, entertainment, and education. Recent unsupervised methods utilize affine and thin-plate spline transformations based on keypoints to transfer the motion in driving frames to the source image. However, limited by the expressive power of the transformations used, these methods always produce poor results when the gap between the motion in the driving frame and the source image is large. To address this issue, we propose to model motion from the source image to the driving frame in highly-expressive diffeomorphism spaces. Firstly, we introduce Continuous Piecewise-Affine based (CPAB) transformation to model the motion and present a well-designed inference algorithm to generate CPAB transformation from control keypoints. Secondly, we propose a SAM-guided keypoint semantic loss to further constrain the keypoint extraction process and improve the semantic consistency between the corresponding keypoints on the source and driving images. Finally, we design a structure alignment loss to align the structure-related features extracted from driving and generated images, thus helping the generator generate results that are more consistent with the driving action. Extensive experiments on four datasets demonstrate the effectiveness of our method against state-of-the-art competitors quantitatively and qualitatively. Code will be publicly available at: https://github.com/DevilPG/AAAI2024-CPABMM.
Beyond the Label Itself: Latent Labels Enhance Semi-supervised Point Cloud Panoptic Segmentation
Dec 13, 2023



As the exorbitant expense of labeling autopilot datasets and the growing trend of utilizing unlabeled data, semi-supervised segmentation on point clouds becomes increasingly imperative. Intuitively, finding out more ``unspoken words'' (i.e., latent instance information) beyond the label itself should be helpful to improve performance. In this paper, we discover two types of latent labels behind the displayed label embedded in LiDAR and image data. First, in the LiDAR Branch, we propose a novel augmentation, Cylinder-Mix, which is able to augment more yet reliable samples for training. Second, in the Image Branch, we propose the Instance Position-scale Learning (IPSL) Module to learn and fuse the information of instance position and scale, which is from a 2D pre-trained detector and a type of latent label obtained from 3D to 2D projection. Finally, the two latent labels are embedded into the multi-modal panoptic segmentation network. The ablation of the IPSL module demonstrates its robust adaptability, and the experiments evaluated on SemanticKITTI and nuScenes demonstrate that our model outperforms the state-of-the-art method, LaserMix.
Evidence-based Interpretable Open-domain Fact-checking with Large Language Models
Dec 10, 2023Universal fact-checking systems for real-world claims face significant challenges in gathering valid and sufficient real-time evidence and making reasoned decisions. In this work, we introduce the Open-domain Explainable Fact-checking (OE-Fact) system for claim-checking in real-world scenarios. The OE-Fact system can leverage the powerful understanding and reasoning capabilities of large language models (LLMs) to validate claims and generate causal explanations for fact-checking decisions. To adapt the traditional three-module fact-checking framework to the open domain setting, we first retrieve claim-related information as relevant evidence from open websites. After that, we retain the evidence relevant to the claim through LLM and similarity calculation for subsequent verification. We evaluate the performance of our adapted three-module OE-Fact system on the Fact Extraction and Verification (FEVER) dataset. Experimental results show that our OE-Fact system outperforms general fact-checking baseline systems in both closed- and open-domain scenarios, ensuring stable and accurate verdicts while providing concise and convincing real-time explanations for fact-checking decisions.
COTR: Compact Occupancy TRansformer for Vision-based 3D Occupancy Prediction
Dec 04, 2023



The autonomous driving community has shown significant interest in 3D occupancy prediction, driven by its exceptional geometric perception and general object recognition capabilities. To achieve this, current works try to construct a Tri-Perspective View (TPV) or Occupancy (OCC) representation extending from the Bird-Eye-View perception. However, compressed views like TPV representation lose 3D geometry information while raw and sparse OCC representation requires heavy but reducant computational costs. To address the above limitations, we propose Compact Occupancy TRansformer (COTR), with a geometry-aware occupancy encoder and a semantic-aware group decoder to reconstruct a compact 3D OCC representation. The occupancy encoder first generates a compact geometrical OCC feature through efficient explicit-implicit view transformation. Then, the occupancy decoder further enhances the semantic discriminability of the compact OCC representation by a coarse-to-fine semantic grouping strategy. Empirical experiments show that there are evident performance gains across multiple baselines, e.g., COTR outperforms baselines with a relative improvement of 8%-15%, demonstrating the superiority of our method.