 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovariance-Adaptive Sequential Black-box Optimization for Diffusion Targeted Generation
Jun 02, 2024Diffusion models have demonstrated great potential in generating high-quality content for images, natural language, protein domains, etc. However, how to perform user-preferred targeted generation via diffusion models with only black-box target scores of users remains challenging. To address this issue, we first formulate the fine-tuning of the targeted reserve-time stochastic differential equation (SDE) associated with a pre-trained diffusion model as a sequential black-box optimization problem. Furthermore, we propose a novel covariance-adaptive sequential optimization algorithm to optimize cumulative black-box scores under unknown transition dynamics. Theoretically, we prove a $O(\frac{d^2}{\sqrt{T}})$ convergence rate for cumulative convex functions without smooth and strongly convex assumptions. Empirically, experiments on both numerical test problems and target-guided 3D-molecule generation tasks show the superior performance of our method in achieving better target scores.
Human-Generative AI Collaborative Problem Solving Who Leads and How Students Perceive the Interactions
May 19, 2024This research investigates distinct human-generative AI collaboration types and students' interaction experiences when collaborating with generative AI (i.e., ChatGPT) for problem-solving tasks and how these factors relate to students' sense of agency and perceived collaborative problem solving. By analyzing the surveys and reflections of 79 undergraduate students, we identified three human-generative AI collaboration types: even contribution, human leads, and AI leads. Notably, our study shows that 77.21% of students perceived they led or had even contributed to collaborative problem-solving when collaborating with ChatGPT. On the other hand, 15.19% of the human participants indicated that the collaborations were led by ChatGPT, indicating a potential tendency for students to rely on ChatGPT. Furthermore, 67.09% of students perceived their interaction experiences with ChatGPT to be positive or mixed. We also found a positive correlation between positive interaction experience and a sense of positive agency. The results of this study contribute to our understanding of the collaboration between students and generative AI and highlight the need to study further why some students let ChatGPT lead collaborative problem-solving and how to enhance their interaction experience through curriculum and technology design.
LIST: Learning to Index Spatio-Textual Data for Embedding based Spatial Keyword Queries
Mar 18, 2024



With the proliferation of spatio-textual data, Top-k KNN spatial keyword queries (TkQs), which return a list of objects based on a ranking function that evaluates both spatial and textual relevance, have found many real-life applications. Existing geo-textual indexes for TkQs use traditional retrieval models like BM25 to compute text relevance and usually exploit a simple linear function to compute spatial relevance, but its effectiveness is limited. To improve effectiveness, several deep learning models have recently been proposed, but they suffer severe efficiency issues. To the best of our knowledge, there are no efficient indexes specifically designed to accelerate the top-k search process for these deep learning models. To tackle these issues, we propose a novel technique, which Learns to Index the Spatio-Textual data for answering embedding based spatial keyword queries (called LIST). LIST is featured with two novel components. Firstly, we propose a lightweight and effective relevance model that is capable of learning both textual and spatial relevance. Secondly, we introduce a novel machine learning based Approximate Nearest Neighbor Search (ANNS) index, which utilizes a new learning-to-cluster technique to group relevant queries and objects together while separating irrelevant queries and objects. Two key challenges in building an effective and efficient index are the absence of high-quality labels and unbalanced clustering results. We develop a novel pseudo-label generation technique to address the two challenges. Experimental results show that LIST significantly outperforms state-of-the-art methods on effectiveness, with improvements up to 19.21% and 12.79% in terms of NDCG@1 and Recall@10, and is three orders of magnitude faster than the most effective baseline.
Make Me Happier: Evoking Emotions Through Image Diffusion Models
Mar 13, 2024
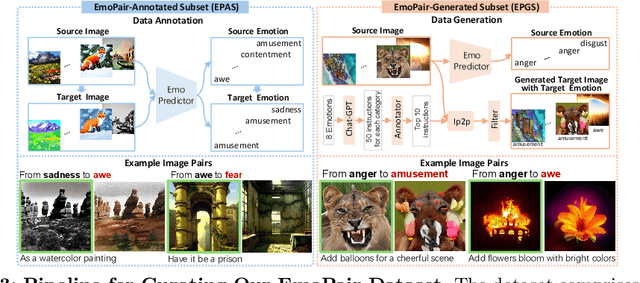
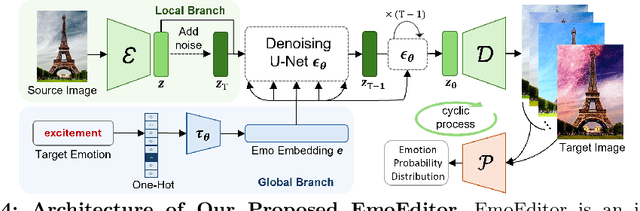
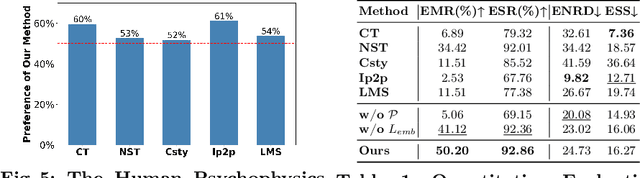
Despite the rapid progress in image generation, emotional image editing remains under-explored. The semantics, context, and structure of an image can evoke emotional responses, making emotional image editing techniques valuable for various real-world applications, including treatment of psychological disorders, commercialization of products, and artistic design. For the first time, we present a novel challenge of emotion-evoked image generation, aiming to synthesize images that evoke target emotions while retaining the semantics and structures of the original scenes. To address this challenge, we propose a diffusion model capable of effectively understanding and editing source images to convey desired emotions and sentiments. Moreover, due to the lack of emotion editing datasets, we provide a unique dataset consisting of 340,000 pairs of images and their emotion annotations. Furthermore, we conduct human psychophysics experiments and introduce four new evaluation metrics to systematically benchmark all the methods. Experimental results demonstrate that our method surpasses all competitive baselines. Our diffusion model is capable of identifying emotional cues from original images, editing images that elicit desired emotions, and meanwhile, preserving the semantic structure of the original images. All code, model, and data will be made public.
MosaicFusion: Diffusion Models as Data Augmenters for Large Vocabulary Instance Segmentation
Sep 22, 2023



We present MosaicFusion, a simple yet effective diffusion-based data augmentation approach for large vocabulary instance segmentation. Our method is training-free and does not rely on any label supervision. Two key designs enable us to employ an off-the-shelf text-to-image diffusion model as a useful dataset generator for object instances and mask annotations. First, we divide an image canvas into several regions and perform a single round of diffusion process to generate multiple instances simultaneously, conditioning on different text prompts. Second, we obtain corresponding instance masks by aggregating cross-attention maps associated with object prompts across layers and diffusion time steps, followed by simple thresholding and edge-aware refinement processing. Without bells and whistles, our MosaicFusion can produce a significant amount of synthetic labeled data for both rare and novel categories. Experimental results on the challenging LVIS long-tailed and open-vocabulary benchmarks demonstrate that MosaicFusion can significantly improve the performance of existing instance segmentation models, especially for rare and novel categories. Code will be released at https://github.com/Jiahao000/MosaicFusion.
Towards Building Voice-based Conversational Recommender Systems: Datasets, Potential Solutions, and Prospects
Jun 14, 2023



Conversational recommender systems (CRSs) have become crucial emerging research topics in the field of RSs, thanks to their natural advantages of explicitly acquiring user preferences via interactive conversations and revealing the reasons behind recommendations. However, the majority of current CRSs are text-based, which is less user-friendly and may pose challenges for certain users, such as those with visual impairments or limited writing and reading abilities. Therefore, for the first time, this paper investigates the potential of voice-based CRS (VCRSs) to revolutionize the way users interact with RSs in a natural, intuitive, convenient, and accessible fashion. To support such studies, we create two VCRSs benchmark datasets in the e-commerce and movie domains, after realizing the lack of such datasets through an exhaustive literature review. Specifically, we first empirically verify the benefits and necessity of creating such datasets. Thereafter, we convert the user-item interactions to text-based conversations through the ChatGPT-driven prompts for generating diverse and natural templates, and then synthesize the corresponding audios via the text-to-speech model. Meanwhile, a number of strategies are delicately designed to ensure the naturalness and high quality of voice conversations. On this basis, we further explore the potential solutions and point out possible directions to build end-to-end VCRSs by seamlessly extracting and integrating voice-based inputs, thus delivering performance-enhanced, self-explainable, and user-friendly VCRSs. Our study aims to establish the foundation and motivate further pioneering research in the emerging field of VCRSs. This aligns with the principles of explainable AI and AI for social good, viz., utilizing technology's potential to create a fair, sustainable, and just world.
Unfolded Self-Reconstruction LSH: Towards Machine Unlearning in Approximate Nearest Neighbour Search
Apr 06, 2023



Approximate nearest neighbour (ANN) search is an essential component of search engines, recommendation systems, etc. Many recent works focus on learning-based data-distribution-dependent hashing and achieve good retrieval performance. However, due to increasing demand for users' privacy and security, we often need to remove users' data information from Machine Learning (ML) models to satisfy specific privacy and security requirements. This need requires the ANN search algorithm to support fast online data deletion and insertion. Current learning-based hashing methods need retraining the hash function, which is prohibitable due to the vast time-cost of large-scale data. To address this problem, we propose a novel data-dependent hashing method named unfolded self-reconstruction locality-sensitive hashing (USR-LSH). Our USR-LSH unfolded the optimization update for instance-wise data reconstruction, which is better for preserving data information than data-independent LSH. Moreover, our USR-LSH supports fast online data deletion and insertion without retraining. To the best of our knowledge, we are the first to address the machine unlearning of retrieval problems. Empirically, we demonstrate that USR-LSH outperforms the state-of-the-art data-distribution-independent LSH in ANN tasks in terms of precision and recall. We also show that USR-LSH has significantly faster data deletion and insertion time than learning-based data-dependent hashing.
Masked Frequency Modeling for Self-Supervised Visual Pre-Training
Jun 15, 2022



We present Masked Frequency Modeling (MFM), a unified frequency-domain-based approach for self-supervised pre-training of visual models. Instead of randomly inserting mask tokens to the input embeddings in the spatial domain, in this paper, we shift the perspective to the frequency domain. Specifically, MFM first masks out a portion of frequency components of the input image and then predicts the missing frequencies on the frequency spectrum. Our key insight is that predicting masked components in the frequency domain is more ideal to reveal underlying image patterns rather than predicting masked patches in the spatial domain, due to the heavy spatial redundancy. Our findings suggest that with the right configuration of mask-and-predict strategy, both the structural information within high-frequency components and the low-level statistics among low-frequency counterparts are useful in learning good representations. For the first time, MFM demonstrates that, for both ViT and CNN, a simple non-Siamese framework can learn meaningful representations even using none of the following: (i) extra data, (ii) extra model, (iii) mask token. Experimental results on ImageNet and several robustness benchmarks show the competitive performance and advanced robustness of MFM compared with recent masked image modeling approaches. Furthermore, we also comprehensively investigate the effectiveness of classical image restoration tasks for representation learning from a unified frequency perspective and reveal their intriguing relations with our MFM approach. Project page: https://www.mmlab-ntu.com/project/mfm/index.html.
Unsupervised Object-Level Representation Learning from Scene Images
Jun 22, 2021



Contrastive self-supervised learning has largely narrowed the gap to supervised pre-training on ImageNet. However, its success highly relies on the object-centric priors of ImageNet, i.e., different augmented views of the same image correspond to the same object. Such a heavily curated constraint becomes immediately infeasible when pre-trained on more complex scene images with many objects. To overcome this limitation, we introduce Object-level Representation Learning (ORL), a new self-supervised learning framework towards scene images. Our key insight is to leverage image-level self-supervised pre-training as the prior to discover object-level semantic correspondence, thus realizing object-level representation learning from scene images. Extensive experiments on COCO show that ORL significantly improves the performance of self-supervised learning on scene images, even surpassing supervised ImageNet pre-training on several downstream tasks. Furthermore, ORL improves the downstream performance when more unlabeled scene images are available, demonstrating its great potential of harnessing unlabeled data in the wild. We hope our approach can motivate future research on more general-purpose unsupervised representation learning from scene data. Project page: https://www.mmlab-ntu.com/project/orl/.
Delving into Inter-Image Invariance for Unsupervised Visual Representations
Aug 26, 2020



Contrastive learning has recently shown immense potential in unsupervised visual representation learning. Existing studies in this track mainly focus on intra-image invariance learning. The learning typically uses rich intra-image transformations to construct positive pairs and then maximizes agreement using a contrastive loss. The merits of inter-image invariance, conversely, remain much less explored. One major obstacle to exploit inter-image invariance is that it is unclear how to reliably construct inter-image positive pairs, and further derive effective supervision from them since there are no pair annotations available. In this work, we present a rigorous and comprehensive study on inter-image invariance learning from three main constituting components: pseudo-label maintenance, sampling strategy, and decision boundary design. Through carefully-designed comparisons and analysis, we propose a unified framework that supports the integration of unsupervised intra- and inter-image invariance learning. With all the obtained recipes, our final model, namely InterCLR, achieves state-of-the-art performance on standard benchmarks. Code and models will be available at https://github.com/open-mmlab/OpenSelfSup.