 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptively Learning to Select-Rank in Online Platforms
Jun 07, 2024Ranking algorithms are fundamental to various online platforms across e-commerce sites to content streaming services. Our research addresses the challenge of adaptively ranking items from a candidate pool for heterogeneous users, a key component in personalizing user experience. We develop a user response model that considers diverse user preferences and the varying effects of item positions, aiming to optimize overall user satisfaction with the ranked list. We frame this problem within a contextual bandits framework, with each ranked list as an action. Our approach incorporates an upper confidence bound to adjust predicted user satisfaction scores and selects the ranking action that maximizes these adjusted scores, efficiently solved via maximum weight imperfect matching. We demonstrate that our algorithm achieves a cumulative regret bound of $O(d\sqrt{NKT})$ for ranking $K$ out of $N$ items in a $d$-dimensional context space over $T$ rounds, under the assumption that user responses follow a generalized linear model. This regret alleviates dependence on the ambient action space, whose cardinality grows exponentially with $N$ and $K$ (thus rendering direct application of existing adaptive learning algorithms -- such as UCB or Thompson sampling -- infeasible). Experiments conducted on both simulated and real-world datasets demonstrate our algorithm outperforms the baseline.
ReasonPix2Pix: Instruction Reasoning Dataset for Advanced Image Editing
May 18, 2024Instruction-based image editing focuses on equipping a generative model with the capacity to adhere to human-written instructions for editing images. Current approaches typically comprehend explicit and specific instructions. However, they often exhibit a deficiency in executing active reasoning capacities required to comprehend instructions that are implicit or insufficiently defined. To enhance active reasoning capabilities and impart intelligence to the editing model, we introduce ReasonPix2Pix, a comprehensive reasoning-attentive instruction editing dataset. The dataset is characterized by 1) reasoning instruction, 2) more realistic images from fine-grained categories, and 3) increased variances between input and edited images. When fine-tuned with our dataset under supervised conditions, the model demonstrates superior performance in instructional editing tasks, independent of whether the tasks require reasoning or not. The code, model, and dataset will be publicly available.
Conformal Alignment: Knowing When to Trust Foundation Models with Guarantees
May 16, 2024Before deploying outputs from foundation models in high-stakes tasks, it is imperative to ensure that they align with human values. For instance, in radiology report generation, reports generated by a vision-language model must align with human evaluations before their use in medical decision-making. This paper presents Conformal Alignment, a general framework for identifying units whose outputs meet a user-specified alignment criterion. It is guaranteed that on average, a prescribed fraction of selected units indeed meet the alignment criterion, regardless of the foundation model or the data distribution. Given any pre-trained model and new units with model-generated outputs, Conformal Alignment leverages a set of reference data with ground-truth alignment status to train an alignment predictor. It then selects new units whose predicted alignment scores surpass a data-dependent threshold, certifying their corresponding outputs as trustworthy. Through applications to question answering and radiology report generation, we demonstrate that our method is able to accurately identify units with trustworthy outputs via lightweight training over a moderate amount of reference data. En route, we investigate the informativeness of various features in alignment prediction and combine them with standard models to construct the alignment predictor.
Confidence on the Focal: Conformal Prediction with Selection-Conditional Coverage
Mar 06, 2024



Conformal prediction builds marginally valid prediction intervals which cover the unknown outcome of a randomly drawn new test point with a prescribed probability. In practice, a common scenario is that, after seeing the test unit(s), practitioners decide which test unit(s) to focus on in a data-driven manner, and wish to quantify the uncertainty for the focal unit(s). In such cases, marginally valid prediction intervals for these focal units can be misleading due to selection bias. This paper presents a general framework for constructing a prediction set with finite-sample exact coverage conditional on the unit being selected. Its general form works for arbitrary selection rules, and generalizes Mondrian Conformal Prediction to multiple test units and non-equivariant classifiers. We then work out computationally efficient implementation of our framework for a number of realistic selection rules, including top-K selection, optimization-based selection, selection based on conformal p-values, and selection based on properties of preliminary conformal prediction sets. The performance of our methods is demonstrated via applications in drug discovery and health risk prediction.
SepRep-Net: Multi-source Free Domain Adaptation via Model Separation And Reparameterization
Feb 13, 2024



We consider multi-source free domain adaptation, the problem of adapting multiple existing models to a new domain without accessing the source data. Among existing approaches, methods based on model ensemble are effective in both the source and target domains, but incur significantly increased computational costs. Towards this dilemma, in this work, we propose a novel framework called SepRep-Net, which tackles multi-source free domain adaptation via model Separation and Reparameterization.Concretely, SepRep-Net reassembled multiple existing models to a unified network, while maintaining separate pathways (Separation). During training, separate pathways are optimized in parallel with the information exchange regularly performed via an additional feature merging unit. With our specific design, these pathways can be further reparameterized into a single one to facilitate inference (Reparameterization). SepRep-Net is characterized by 1) effectiveness: competitive performance on the target domain, 2) efficiency: low computational costs, and 3) generalizability: maintaining more source knowledge than existing solutions. As a general approach, SepRep-Net can be seamlessly plugged into various methods. Extensive experiments validate the performance of SepRep-Net on mainstream benchmarks.
SPA: A Graph Spectral Alignment Perspective for Domain Adaptation
Oct 27, 2023



Unsupervised domain adaptation (UDA) is a pivotal form in machine learning to extend the in-domain model to the distinctive target domains where the data distributions differ. Most prior works focus on capturing the inter-domain transferability but largely overlook rich intra-domain structures, which empirically results in even worse discriminability. In this work, we introduce a novel graph SPectral Alignment (SPA) framework to tackle the tradeoff. The core of our method is briefly condensed as follows: (i)-by casting the DA problem to graph primitives, SPA composes a coarse graph alignment mechanism with a novel spectral regularizer towards aligning the domain graphs in eigenspaces; (ii)-we further develop a fine-grained message propagation module -- upon a novel neighbor-aware self-training mechanism -- in order for enhanced discriminability in the target domain. On standardized benchmarks, the extensive experiments of SPA demonstrate that its performance has surpassed the existing cutting-edge DA methods. Coupled with dense model analysis, we conclude that our approach indeed possesses superior efficacy, robustness, discriminability, and transferability. Code and data are available at: https://github.com/CrownX/SPA.
SeeDS: Semantic Separable Diffusion Synthesizer for Zero-shot Food Detection
Oct 07, 2023
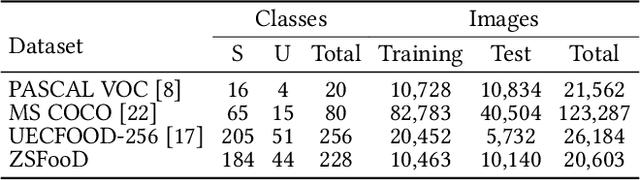
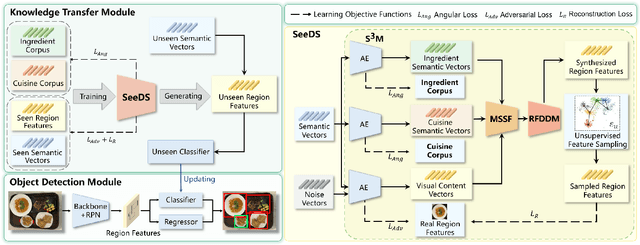
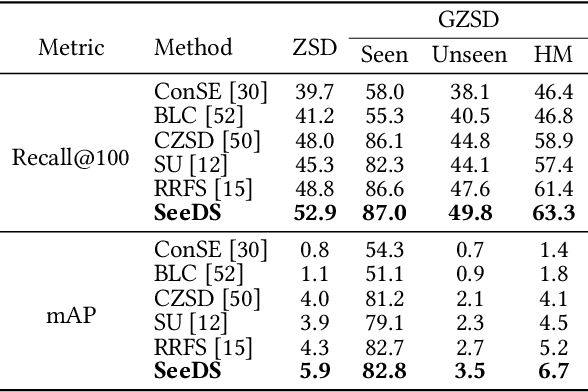
Food detection is becoming a fundamental task in food computing that supports various multimedia applications, including food recommendation and dietary monitoring. To deal with real-world scenarios, food detection needs to localize and recognize novel food objects that are not seen during training, demanding Zero-Shot Detection (ZSD). However, the complexity of semantic attributes and intra-class feature diversity poses challenges for ZSD methods in distinguishing fine-grained food classes. To tackle this, we propose the Semantic Separable Diffusion Synthesizer (SeeDS) framework for Zero-Shot Food Detection (ZSFD). SeeDS consists of two modules: a Semantic Separable Synthesizing Module (S$^3$M) and a Region Feature Denoising Diffusion Model (RFDDM). The S$^3$M learns the disentangled semantic representation for complex food attributes from ingredients and cuisines, and synthesizes discriminative food features via enhanced semantic information. The RFDDM utilizes a novel diffusion model to generate diversified region features and enhances ZSFD via fine-grained synthesized features. Extensive experiments show the state-of-the-art ZSFD performance of our proposed method on two food datasets, ZSFooD and UECFOOD-256. Moreover, SeeDS also maintains effectiveness on general ZSD datasets, PASCAL VOC and MS COCO. The code and dataset can be found at https://github.com/LanceZPF/SeeDS.
Uncertainty Quantification over Graph with Conformalized Graph Neural Networks
May 23, 2023



Graph Neural Networks (GNNs) are powerful machine learning prediction models on graph-structured data. However, GNNs lack rigorous uncertainty estimates, limiting their reliable deployment in settings where the cost of errors is significant. We propose conformalized GNN (CF-GNN), extending conformal prediction (CP) to graph-based models for guaranteed uncertainty estimates. Given an entity in the graph, CF-GNN produces a prediction set/interval that provably contains the true label with pre-defined coverage probability (e.g. 90%). We establish a permutation invariance condition that enables the validity of CP on graph data and provide an exact characterization of the test-time coverage. Moreover, besides valid coverage, it is crucial to reduce the prediction set size/interval length for practical use. We observe a key connection between non-conformity scores and network structures, which motivates us to develop a topology-aware output correction model that learns to update the prediction and produces more efficient prediction sets/intervals. Extensive experiments show that CF-GNN achieves any pre-defined target marginal coverage while significantly reducing the prediction set/interval size by up to 74% over the baselines. It also empirically achieves satisfactory conditional coverage over various raw and network features.
Topological properties and organizing principles of semantic networks
Apr 24, 2023



Interpreting natural language is an increasingly important task in computer algorithms due to the growing availability of unstructured textual data. Natural Language Processing (NLP) applications rely on semantic networks for structured knowledge representation. The fundamental properties of semantic networks must be taken into account when designing NLP algorithms, yet they remain to be structurally investigated. We study the properties of semantic networks from ConceptNet, defined by 7 semantic relations from 11 different languages. We find that semantic networks have universal basic properties: they are sparse, highly clustered, and exhibit power-law degree distributions. Our findings show that the majority of the considered networks are scale-free. Some networks exhibit language-specific properties determined by grammatical rules, for example networks from highly inflected languages, such as e.g. Latin, German, French and Spanish, show peaks in the degree distribution that deviate from a power law. We find that depending on the semantic relation type and the language, the link formation in semantic networks is guided by different principles. In some networks the connections are similarity-based, while in others the connections are more complementarity-based. Finally, we demonstrate how knowledge of similarity and complementarity in semantic networks can improve NLP algorithms in missing link inference.
UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers
Jan 31, 2023



Real-world data contains a vast amount of multimodal information, among which vision and language are the two most representative modalities. Moreover, increasingly heavier models, e.g., Transformers, have attracted the attention of researchers to model compression. However, how to compress multimodal models, especially vison-language Transformers, is still under-explored. This paper proposes the \textbf{U}nified and \textbf{P}r\textbf{o}gressive \textbf{P}runing (UPop) as a universal vison-language Transformer compression framework, which incorporates 1) unifiedly searching multimodal subnets in a continuous optimization space from the original model, which enables automatic assignment of pruning ratios among compressible modalities and structures; 2) progressively searching and retraining the subnet, which maintains convergence between the search and retrain to attain higher compression ratios. Experiments on multiple generative and discriminative vision-language tasks, including Visual Reasoning, Image Caption, Visual Question Answer, Image-Text Retrieval, Text-Image Retrieval, and Image Classification, demonstrate the effectiveness and versatility of the proposed UPop framework.