 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards robust prediction of material properties for nuclear reactor design under scarce data -- a study in creep rupture property
May 28, 2024Advances in Deep Learning bring further investigation into credibility and robustness, especially for safety-critical engineering applications such as the nuclear industry. The key challenges include the availability of data set (often scarce and sparse) and insufficient consideration of the uncertainty in the data, model, and prediction. This paper therefore presents a meta-learning based approach that is both uncertainty- and prior knowledge-informed, aiming at trustful predictions of material properties for the nuclear reactor design. It is suited for robust learning under limited data. Uncertainty has been accounted for where a distribution of predictor functions are produced for extrapolation. Results suggest it achieves superior performance than existing empirical methods in rupture life prediction, a case which is typically under a small data regime. While demonstrated herein with rupture properties, this learning approach is transferable to solve similar problems of data scarcity across the nuclear industry. It is of great importance to boosting the AI analytics in the nuclear industry by proving the applicability and robustness while providing tools that can be trusted.
DoGaussian: Distributed-Oriented Gaussian Splatting for Large-Scale 3D Reconstruction Via Gaussian Consensus
May 22, 2024The recent advances in 3D Gaussian Splatting (3DGS) show promising results on the novel view synthesis (NVS) task. With its superior rendering performance and high-fidelity rendering quality, 3DGS is excelling at its previous NeRF counterparts. The most recent 3DGS method focuses either on improving the instability of rendering efficiency or reducing the model size. On the other hand, the training efficiency of 3DGS on large-scale scenes has not gained much attention. In this work, we propose DoGaussian, a method that trains 3DGS distributedly. Our method first decomposes a scene into K blocks and then introduces the Alternating Direction Method of Multipliers (ADMM) into the training procedure of 3DGS. During training, our DoGaussian maintains one global 3DGS model on the master node and K local 3DGS models on the slave nodes. The K local 3DGS models are dropped after training and we only query the global 3DGS model during inference. The training time is reduced by scene decomposition, and the training convergence and stability are guaranteed through the consensus on the shared 3D Gaussians. Our method accelerates the training of 3DGS by 6+ times when evaluated on large-scale scenes while concurrently achieving state-of-the-art rendering quality. Our project page is available at https://aibluefisher.github.io/DoGaussian.
ViViD: Video Virtual Try-on using Diffusion Models
May 20, 2024Video virtual try-on aims to transfer a clothing item onto the video of a target person. Directly applying the technique of image-based try-on to the video domain in a frame-wise manner will cause temporal-inconsistent outcomes while previous video-based try-on solutions can only generate low visual quality and blurring results. In this work, we present ViViD, a novel framework employing powerful diffusion models to tackle the task of video virtual try-on. Specifically, we design the Garment Encoder to extract fine-grained clothing semantic features, guiding the model to capture garment details and inject them into the target video through the proposed attention feature fusion mechanism. To ensure spatial-temporal consistency, we introduce a lightweight Pose Encoder to encode pose signals, enabling the model to learn the interactions between clothing and human posture and insert hierarchical Temporal Modules into the text-to-image stable diffusion model for more coherent and lifelike video synthesis. Furthermore, we collect a new dataset, which is the largest, with the most diverse types of garments and the highest resolution for the task of video virtual try-on to date. Extensive experiments demonstrate that our approach is able to yield satisfactory video try-on results. The dataset, codes, and weights will be publicly available. Project page: https://becauseimbatman0.github.io/ViViD.
Variational Schrödinger Diffusion Models
May 08, 2024Schr\"odinger bridge (SB) has emerged as the go-to method for optimizing transportation plans in diffusion models. However, SB requires estimating the intractable forward score functions, inevitably resulting in the costly implicit training loss based on simulated trajectories. To improve the scalability while preserving efficient transportation plans, we leverage variational inference to linearize the forward score functions (variational scores) of SB and restore simulation-free properties in training backward scores. We propose the variational Schr\"odinger diffusion model (VSDM), where the forward process is a multivariate diffusion and the variational scores are adaptively optimized for efficient transport. Theoretically, we use stochastic approximation to prove the convergence of the variational scores and show the convergence of the adaptively generated samples based on the optimal variational scores. Empirically, we test the algorithm in simulated examples and observe that VSDM is efficient in generations of anisotropic shapes and yields straighter sample trajectories compared to the single-variate diffusion. We also verify the scalability of the algorithm in real-world data and achieve competitive unconditional generation performance in CIFAR10 and conditional generation in time series modeling. Notably, VSDM no longer depends on warm-up initializations and has become tuning-friendly in training large-scale experiments.
HAGAN: Hybrid Augmented Generative Adversarial Network for Medical Image Synthesis
May 08, 2024Medical Image Synthesis (MIS) plays an important role in the intelligent medical field, which greatly saves the economic and time costs of medical diagnosis. However, due to the complexity of medical images and similar characteristics of different tissue cells, existing methods face great challenges in meeting their biological consistency. To this end, we propose the Hybrid Augmented Generative Adversarial Network (HAGAN) to maintain the authenticity of structural texture and tissue cells. HAGAN contains Attention Mixed (AttnMix) Generator, Hierarchical Discriminator and Reverse Skip Connection between Discriminator and Generator. The AttnMix consistency differentiable regularization encourages the perception in structural and textural variations between real and fake images, which improves the pathological integrity of synthetic images and the accuracy of features in local areas. The Hierarchical Discriminator introduces pixel-by-pixel discriminant feedback to generator for enhancing the saliency and discriminance of global and local details simultaneously. The Reverse Skip Connection further improves the accuracy for fine details by fusing real and synthetic distribution features. Our experimental evaluations on three datasets of different scales, i.e., COVID-CT, ACDC and BraTS2018, demonstrate that HAGAN outperforms the existing methods and achieves state-of-the-art performance in both high-resolution and low-resolution.
Representation Learning of Daily Movement Data Using Text Encoders
May 07, 2024Time-series representation learning is a key area of research for remote healthcare monitoring applications. In this work, we focus on a dataset of recordings of in-home activity from people living with Dementia. We design a representation learning method based on converting activity to text strings that can be encoded using a language model fine-tuned to transform data from the same participants within a $30$-day window to similar embeddings in the vector space. This allows for clustering and vector searching over participants and days, and the identification of activity deviations to aid with personalised delivery of care.
* Accepted at ICLR 2024 Workshop on Learning from Time Series For Health: https://openreview.net/forum?id=mmxNNwxvWG
When LLMs Meet Cybersecurity: A Systematic Literature Review
May 06, 2024The rapid advancements in large language models (LLMs) have opened new avenues across various fields, including cybersecurity, which faces an ever-evolving threat landscape and need for innovative technologies. Despite initial explorations into the application of LLMs in cybersecurity, there is a lack of a comprehensive overview of this research area. This paper bridge this gap by providing a systematic literature review, encompassing an analysis of over 180 works, spanning across 25 LLMs and more than 10 downstream scenarios. Our comprehensive overview addresses three critical research questions: the construction of cybersecurity-oriented LLMs, LLMs' applications in various cybersecurity tasks, and the existing challenges and further research in this area. This study aims to shed light on the extensive potential of LLMs in enhancing cybersecurity practices, and serve as a valuable resource for applying LLMs in this doamin. We also maintain and regularly updated list of practical guides on LLMs for cybersecurity at https://github.com/tmylla/Awesome-LLM4Cybersecurity.
FEEL: A Framework for Evaluating Emotional Support Capability with Large Language Models
Mar 23, 2024Emotional Support Conversation (ESC) is a typical dialogue that can effec-tively assist the user in mitigating emotional pressures. However, owing to the inherent subjectivity involved in analyzing emotions, current non-artificial methodologies face challenges in effectively appraising the emo-tional support capability. These metrics exhibit a low correlation with human judgments. Concurrently, manual evaluation methods extremely will cause high costs. To solve these problems, we propose a novel model FEEL (Framework for Evaluating Emotional Support Capability with Large Lan-guage Models), employing Large Language Models (LLMs) as evaluators to assess emotional support capabilities. The model meticulously considers var-ious evaluative aspects of ESC to apply a more comprehensive and accurate evaluation method for ESC. Additionally, it employs a probability distribu-tion approach for a more stable result and integrates an ensemble learning strategy, leveraging multiple LLMs with assigned weights to enhance evalua-tion accuracy. To appraise the performance of FEEL, we conduct extensive experiments on existing ESC model dialogues. Experimental results demon-strate our model exhibits a substantial enhancement in alignment with human evaluations compared to the baselines. Our source code is available at https://github.com/Ansisy/FEEL.
BSDP: Brain-inspired Streaming Dual-level Perturbations for Online Open World Object Detection
Mar 05, 2024

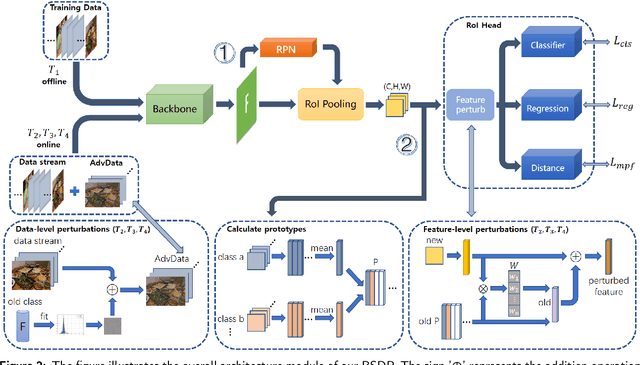
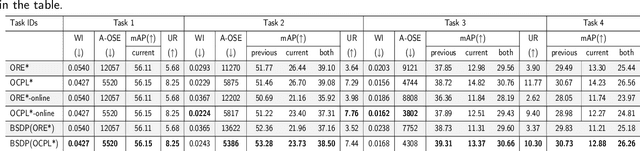
Humans can easily distinguish the known and unknown categories and can recognize the unknown object by learning it once instead of repeating it many times without forgetting the learned object. Hence, we aim to make deep learning models simulate the way people learn. We refer to such a learning manner as OnLine Open World Object Detection(OLOWOD). Existing OWOD approaches pay more attention to the identification of unknown categories, while the incremental learning part is also very important. Besides, some neuroscience research shows that specific noises allow the brain to form new connections and neural pathways which may improve learning speed and efficiency. In this paper, we take the dual-level information of old samples as perturbations on new samples to make the model good at learning new knowledge without forgetting the old knowledge. Therefore, we propose a simple plug-and-play method, called Brain-inspired Streaming Dual-level Perturbations(BSDP), to solve the OLOWOD problem. Specifically, (1) we first calculate the prototypes of previous categories and use the distance between samples and the prototypes as the sample selecting strategy to choose old samples for replay; (2) then take the prototypes as the streaming feature-level perturbations of new samples, so as to improve the plasticity of the model through revisiting the old knowledge; (3) and also use the distribution of the features of the old category samples to generate adversarial data in the form of streams as the data-level perturbations to enhance the robustness of the model to new categories. We empirically evaluate BSDP on PASCAL VOC and MS-COCO, and the excellent results demonstrate the promising performance of our proposed method and learning manner.
Provable Risk-Sensitive Distributional Reinforcement Learning with General Function Approximation
Feb 28, 2024In the realm of reinforcement learning (RL), accounting for risk is crucial for making decisions under uncertainty, particularly in applications where safety and reliability are paramount. In this paper, we introduce a general framework on Risk-Sensitive Distributional Reinforcement Learning (RS-DisRL), with static Lipschitz Risk Measures (LRM) and general function approximation. Our framework covers a broad class of risk-sensitive RL, and facilitates analysis of the impact of estimation functions on the effectiveness of RSRL strategies and evaluation of their sample complexity. We design two innovative meta-algorithms: \texttt{RS-DisRL-M}, a model-based strategy for model-based function approximation, and \texttt{RS-DisRL-V}, a model-free approach for general value function approximation. With our novel estimation techniques via Least Squares Regression (LSR) and Maximum Likelihood Estimation (MLE) in distributional RL with augmented Markov Decision Process (MDP), we derive the first $\widetilde{\mathcal{O}}(\sqrt{K})$ dependency of the regret upper bound for RSRL with static LRM, marking a pioneering contribution towards statistically efficient algorithms in this domain.