 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIT-RAG: Black-Box RAG with Factual Information and Token Reduction
Mar 21, 2024



Due to the extraordinarily large number of parameters, fine-tuning Large Language Models (LLMs) to update long-tail or out-of-date knowledge is impractical in lots of applications. To avoid fine-tuning, we can alternatively treat a LLM as a black-box (i.e., freeze the parameters of the LLM) and augment it with a Retrieval-Augmented Generation (RAG) system, namely black-box RAG. Recently, black-box RAG has achieved success in knowledge-intensive tasks and has gained much attention. Existing black-box RAG methods typically fine-tune the retriever to cater to LLMs' preferences and concatenate all the retrieved documents as the input, which suffers from two issues: (1) Ignorance of Factual Information. The LLM preferred documents may not contain the factual information for the given question, which can mislead the retriever and hurt the effectiveness of black-box RAG; (2) Waste of Tokens. Simply concatenating all the retrieved documents brings large amounts of unnecessary tokens for LLMs, which degenerates the efficiency of black-box RAG. To address these issues, this paper proposes a novel black-box RAG framework which utilizes the factual information in the retrieval and reduces the number of tokens for augmentation, dubbed FIT-RAG. FIT-RAG utilizes the factual information by constructing a bi-label document scorer. Besides, it reduces the tokens by introducing a self-knowledge recognizer and a sub-document-level token reducer. FIT-RAG achieves both superior effectiveness and efficiency, which is validated by extensive experiments across three open-domain question-answering datasets: TriviaQA, NQ and PopQA. FIT-RAG can improve the answering accuracy of Llama2-13B-Chat by 14.3\% on TriviaQA, 19.9\% on NQ and 27.5\% on PopQA, respectively. Furthermore, it can save approximately half of the tokens on average across the three datasets.
Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond
Mar 21, 2024



Trajectory computing is a pivotal domain encompassing trajectory data management and mining, garnering widespread attention due to its crucial role in various practical applications such as location services, urban traffic, and public safety. Traditional methods, focusing on simplistic spatio-temporal features, face challenges of complex calculations, limited scalability, and inadequate adaptability to real-world complexities. In this paper, we present a comprehensive review of the development and recent advances in deep learning for trajectory computing (DL4Traj). We first define trajectory data and provide a brief overview of widely-used deep learning models. Systematically, we explore deep learning applications in trajectory management (pre-processing, storage, analysis, and visualization) and mining (trajectory-related forecasting, trajectory-related recommendation, trajectory classification, travel time estimation, anomaly detection, and mobility generation). Notably, we encapsulate recent advancements in Large Language Models (LLMs) that hold the potential to augment trajectory computing. Additionally, we summarize application scenarios, public datasets, and toolkits. Finally, we outline current challenges in DL4Traj research and propose future directions. Relevant papers and open-source resources have been collated and are continuously updated at: \href{https://github.com/yoshall/Awesome-Trajectory-Computing}{DL4Traj Repo}.
FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis
Jan 19, 2024Text-to-SQL, which provides zero-code interface for operating relational databases, has gained much attention in financial analysis; because, financial professionals may not well-skilled in SQL programming. However, until now, there is no practical Text-to-SQL benchmark dataset for financial analysis, and existing Text-to-SQL methods have not considered the unique characteristics of databases in financial applications, such as commonly existing wide tables. To address these issues, we collect a practical Text-to-SQL benchmark dataset and propose a model-agnostic Large Language Model (LLMs)-based Text-to-SQL framework for financial analysis. The benchmark dataset, BULL, is collected from the practical financial analysis business of Hundsun Technologies Inc., including databases for fund, stock, and macro economy. Besides, the proposed LLMs-based Text-to-SQL framework, FinSQL, provides a systematic treatment for financial Text-to-SQL from the perspectives of prompt construction, parameter-efficient fine-tuning and output calibration. Extensive experimental results on BULL demonstrate that FinSQL achieves the state-of-the-art Text-to-SQL performance at a small cost; furthermore, FinSQL can bring up to 36.64% performance improvement in scenarios requiring few-shot cross-database model transfer.
Starling: An I/O-Efficient Disk-Resident Graph Index Framework for High-Dimensional Vector Similarity Search on Data Segment
Jan 16, 2024High-dimensional vector similarity search (HVSS) is gaining prominence as a powerful tool for various data science and AI applications. As vector data scales up, in-memory indexes pose a significant challenge due to the substantial increase in main memory requirements. A potential solution involves leveraging disk-based implementation, which stores and searches vector data on high-performance devices like NVMe SSDs. However, implementing HVSS for data segments proves to be intricate in vector databases where a single machine comprises multiple segments for system scalability. In this context, each segment operates with limited memory and disk space, necessitating a delicate balance between accuracy, efficiency, and space cost. Existing disk-based methods fall short as they do not holistically address all these requirements simultaneously. In this paper, we present Starling, an I/O-efficient disk-resident graph index framework that optimizes data layout and search strategy within the segment. It has two primary components: (1) a data layout incorporating an in-memory navigation graph and a reordered disk-based graph with enhanced locality, reducing the search path length and minimizing disk bandwidth wastage; and (2) a block search strategy designed to minimize costly disk I/O operations during vector query execution. Through extensive experiments, we validate the effectiveness, efficiency, and scalability of Starling. On a data segment with 2GB memory and 10GB disk capacity, Starling can accommodate up to 33 million vectors in 128 dimensions, offering HVSS with over 0.9 average precision and top-10 recall rate, and latency under 1 millisecond. The results showcase Starling's superior performance, exhibiting 43.9$\times$ higher throughput with 98% lower query latency compared to state-of-the-art methods while maintaining the same level of accuracy.
View-based Explanations for Graph Neural Networks
Jan 08, 2024Generating explanations for graph neural networks (GNNs) has been studied to understand their behavior in analytical tasks such as graph classification. Existing approaches aim to understand the overall results of GNNs rather than providing explanations for specific class labels of interest, and may return explanation structures that are hard to access, nor directly queryable.We propose GVEX, a novel paradigm that generates Graph Views for EXplanation. (1) We design a two-tier explanation structure called explanation views. An explanation view consists of a set of graph patterns and a set of induced explanation subgraphs. Given a database G of multiple graphs and a specific class label l assigned by a GNN-based classifier M, it concisely describes the fraction of G that best explains why l is assigned by M. (2) We propose quality measures and formulate an optimization problem to compute optimal explanation views for GNN explanation. We show that the problem is $\Sigma^2_P$-hard. (3) We present two algorithms. The first one follows an explain-and-summarize strategy that first generates high-quality explanation subgraphs which best explain GNNs in terms of feature influence maximization, and then performs a summarization step to generate patterns. We show that this strategy provides an approximation ratio of 1/2. Our second algorithm performs a single-pass to an input node stream in batches to incrementally maintain explanation views, having an anytime quality guarantee of 1/4 approximation. Using real-world benchmark data, we experimentally demonstrate the effectiveness, efficiency, and scalability of GVEX. Through case studies, we showcase the practical applications of GVEX.
MUST: An Effective and Scalable Framework for Multimodal Search of Target Modality
Dec 11, 2023We investigate the problem of multimodal search of target modality, where the task involves enhancing a query in a specific target modality by integrating information from auxiliary modalities. The goal is to retrieve relevant objects whose contents in the target modality match the specified multimodal query. The paper first introduces two baseline approaches that integrate techniques from the Database, Information Retrieval, and Computer Vision communities. These baselines either merge the results of separate vector searches for each modality or perform a single-channel vector search by fusing all modalities. However, both baselines have limitations in terms of efficiency and accuracy as they fail to adequately consider the varying importance of fusing information across modalities. To overcome these limitations, the paper proposes a novel framework, called MUST. Our framework employs a hybrid fusion mechanism, combining different modalities at multiple stages. Notably, we leverage vector weight learning to determine the importance of each modality, thereby enhancing the accuracy of joint similarity measurement. Additionally, the proposed framework utilizes a fused proximity graph index, enabling efficient joint search for multimodal queries. MUST offers several other advantageous properties, including pluggable design to integrate any advanced embedding techniques, user flexibility to customize weight preferences, and modularized index construction. Extensive experiments on real-world datasets demonstrate the superiority of MUST over the baselines in terms of both search accuracy and efficiency. Our framework achieves over 10x faster search times while attaining an average of 93% higher accuracy. Furthermore, MUST exhibits scalability to datasets containing more than 10 million data elements.
MultiEM: Efficient and Effective Unsupervised Multi-Table Entity Matching
Aug 02, 2023
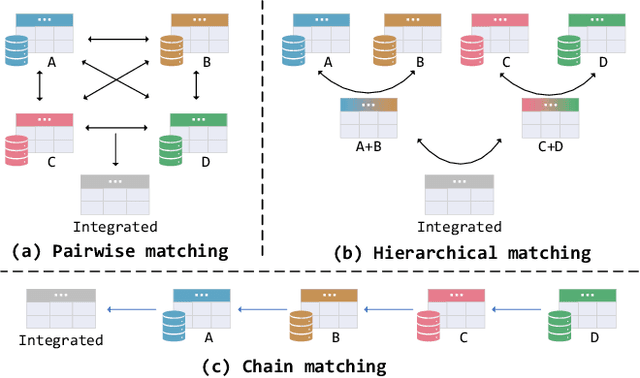
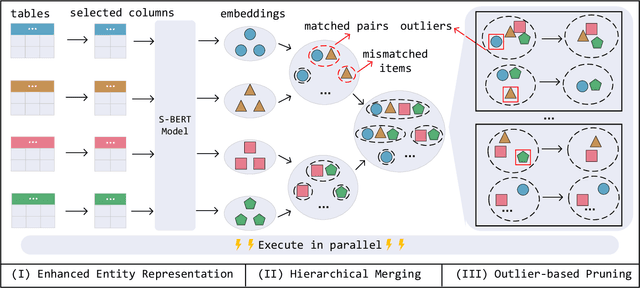

Entity Matching (EM), which aims to identify all entity pairs referring to the same real-world entity from relational tables, is one of the most important tasks in real-world data management systems. Due to the labeling process of EM being extremely labor-intensive, unsupervised EM is more applicable than supervised EM in practical scenarios. Traditional unsupervised EM assumes that all entities come from two tables; however, it is more common to match entities from multiple tables in practical applications, that is, multi-table entity matching (multi-table EM). Unfortunately, effective and efficient unsupervised multi-table EM remains under-explored. To fill this gap, this paper formally studies the problem of unsupervised multi-table entity matching and proposes an effective and efficient solution, termed as MultiEM. MultiEM is a parallelable pipeline of enhanced entity representation, table-wise hierarchical merging, and density-based pruning. Extensive experimental results on six real-world benchmark datasets demonstrate the superiority of MultiEM in terms of effectiveness and efficiency.
C3: Zero-shot Text-to-SQL with ChatGPT
Jul 14, 2023



This paper proposes a ChatGPT-based zero-shot Text-to-SQL method, dubbed C3, which achieves 82.3\% in terms of execution accuracy on the holdout test set of Spider and becomes the state-of-the-art zero-shot Text-to-SQL method on the Spider Challenge. C3 consists of three key components: Clear Prompting (CP), Calibration with Hints (CH), and Consistent Output (CO), which are corresponding to the model input, model bias and model output respectively. It provides a systematic treatment for zero-shot Text-to-SQL. Extensive experiments have been conducted to verify the effectiveness and efficiency of our proposed method.
Real-time Workload Pattern Analysis for Large-scale Cloud Databases
Jul 05, 2023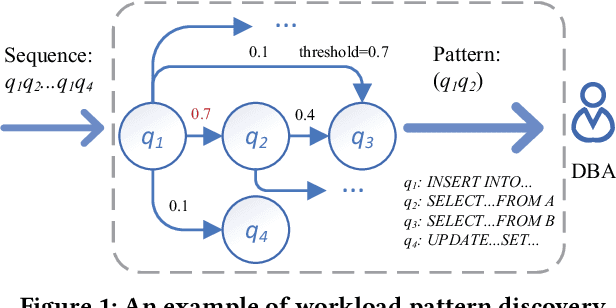
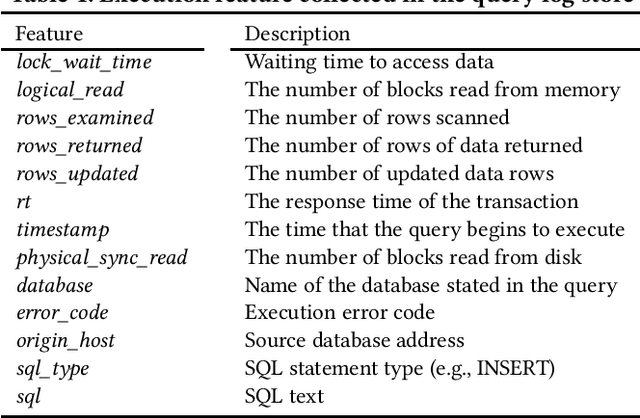
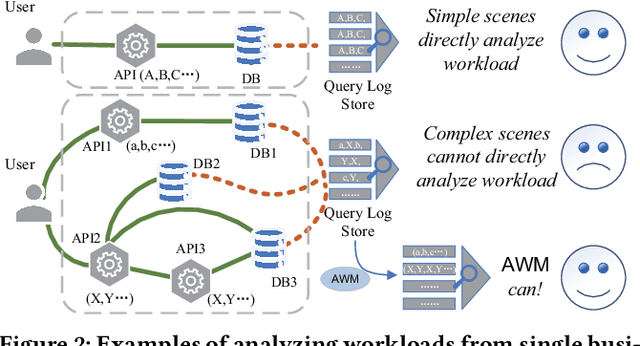
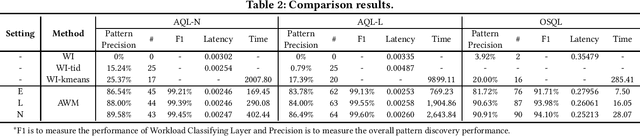
Hosting database services on cloud systems has become a common practice. This has led to the increasing volume of database workloads, which provides the opportunity for pattern analysis. Discovering workload patterns from a business logic perspective is conducive to better understanding the trends and characteristics of the database system. However, existing workload pattern discovery systems are not suitable for large-scale cloud databases which are commonly employed by the industry. This is because the workload patterns of large-scale cloud databases are generally far more complicated than those of ordinary databases. In this paper, we propose Alibaba Workload Miner (AWM), a real-time system for discovering workload patterns in complicated large-scale workloads. AWM encodes and discovers the SQL query patterns logged from user requests and optimizes the querying processing based on the discovered patterns. First, Data Collection & Preprocessing Module collects streaming query logs and encodes them into high-dimensional feature embeddings with rich semantic contexts and execution features. Next, Online Workload Mining Module separates encoded queries by business groups and discovers the workload patterns for each group. Meanwhile, Offline Training Module collects labels and trains the classification model using the labels. Finally, Pattern-based Optimizing Module optimizes query processing in cloud databases by exploiting discovered patterns. Extensive experimental results on one synthetic dataset and two real-life datasets (extracted from Alibaba Cloud databases) show that AWM enhances the accuracy of pattern discovery by 66% and reduce the latency of online inference by 22%, compared with the state-of-the-arts.
Knowledge-refined Denoising Network for Robust Recommendation
Apr 28, 2023



Knowledge graph (KG), which contains rich side information, becomes an essential part to boost the recommendation performance and improve its explainability. However, existing knowledge-aware recommendation methods directly perform information propagation on KG and user-item bipartite graph, ignoring the impacts of \textit{task-irrelevant knowledge propagation} and \textit{vulnerability to interaction noise}, which limits their performance. To solve these issues, we propose a robust knowledge-aware recommendation framework, called \textit{Knowledge-refined Denoising Network} (KRDN), to prune the task-irrelevant knowledge associations and noisy implicit feedback simultaneously. KRDN consists of an adaptive knowledge refining strategy and a contrastive denoising mechanism, which are able to automatically distill high-quality KG triplets for aggregation and prune noisy implicit feedback respectively. Besides, we also design the self-adapted loss function and the gradient estimator for model optimization. The experimental results on three benchmark datasets demonstrate the effectiveness and robustness of KRDN over the state-of-the-art knowledge-aware methods like KGIN, MCCLK, and KGCL, and also outperform robust recommendation models like SGL and SimGCL.