 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-ETS: Learning a Diffusion Probabilistic Model for Electromyography-to-Speech Conversion
May 11, 2024Electromyography-to-Speech (ETS) conversion has demonstrated its potential for silent speech interfaces by generating audible speech from Electromyography (EMG) signals during silent articulations. ETS models usually consist of an EMG encoder which converts EMG signals to acoustic speech features, and a vocoder which then synthesises the speech signals. Due to an inadequate amount of available data and noisy signals, the synthesised speech often exhibits a low level of naturalness. In this work, we propose Diff-ETS, an ETS model which uses a score-based diffusion probabilistic model to enhance the naturalness of synthesised speech. The diffusion model is applied to improve the quality of the acoustic features predicted by an EMG encoder. In our experiments, we evaluated fine-tuning the diffusion model on predictions of a pre-trained EMG encoder, and training both models in an end-to-end fashion. We compared Diff-ETS with a baseline ETS model without diffusion using objective metrics and a listening test. The results indicated the proposed Diff-ETS significantly improved speech naturalness over the baseline.
A Survey of Privacy-Preserving Model Explanations: Privacy Risks, Attacks, and Countermeasures
Mar 31, 2024



As the adoption of explainable AI (XAI) continues to expand, the urgency to address its privacy implications intensifies. Despite a growing corpus of research in AI privacy and explainability, there is little attention on privacy-preserving model explanations. This article presents the first thorough survey about privacy attacks on model explanations and their countermeasures. Our contribution to this field comprises a thorough analysis of research papers with a connected taxonomy that facilitates the categorisation of privacy attacks and countermeasures based on the targeted explanations. This work also includes an initial investigation into the causes of privacy leaks. Finally, we discuss unresolved issues and prospective research directions uncovered in our analysis. This survey aims to be a valuable resource for the research community and offers clear insights for those new to this domain. To support ongoing research, we have established an online resource repository, which will be continuously updated with new and relevant findings. Interested readers are encouraged to access our repository at https://github.com/tamlhp/awesome-privex.
STAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Feb 02, 2024Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.
A Comprehensive Survey on Heart Sound Analysis in the Deep Learning Era
Jan 23, 2023

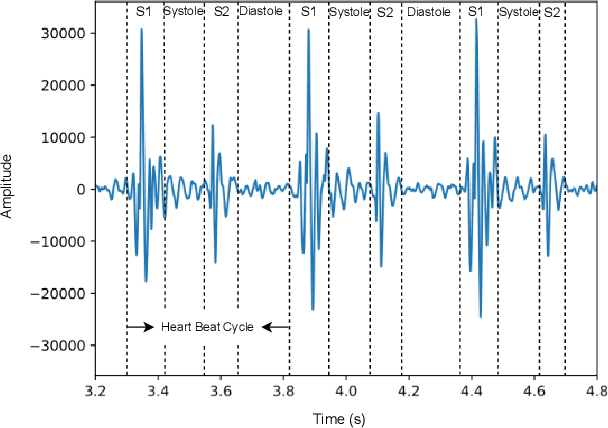
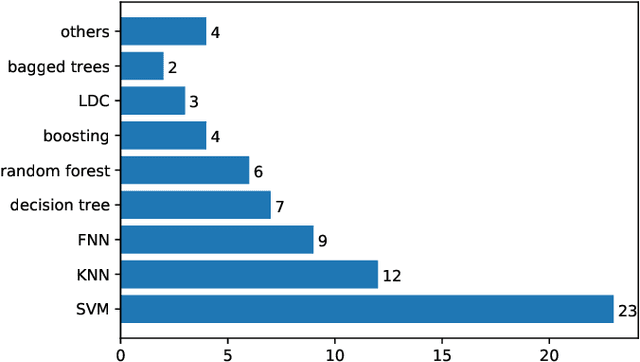
Heart sound auscultation has been demonstrated to be beneficial in clinical usage for early screening of cardiovascular diseases. Due to the high requirement of well-trained professionals for auscultation, automatic auscultation benefiting from signal processing and machine learning can help auxiliary diagnosis and reduce the burdens of training professional clinicians. Nevertheless, classic machine learning is limited to performance improvement in the era of big data. Deep learning has achieved better performance than classic machine learning in many research fields, as it employs more complex model architectures with stronger capability of extracting effective representations. Deep learning has been successfully applied to heart sound analysis in the past years. As most review works about heart sound analysis were given before 2017, the present survey is the first to work on a comprehensive overview to summarise papers on heart sound analysis with deep learning in the past six years 2017--2022. We introduce both classic machine learning and deep learning for comparison, and further offer insights about the advances and future research directions in deep learning for heart sound analysis.
Cutting Through the Noise: An Empirical Comparison of Psychoacoustic and Envelope-based Features for Machinery Fault Detection
Nov 03, 2022



Acoustic-based fault detection has a high potential to monitor the health condition of mechanical parts. However, the background noise of an industrial environment may negatively influence the performance of fault detection. Limited attention has been paid to improving the robustness of fault detection against industrial environmental noise. Therefore, we present the Lenze production background-noise (LPBN) real-world dataset and an automated and noise-robust auditory inspection (ARAI) system for the end-of-line inspection of geared motors. An acoustic array is used to acquire data from motors with a minor fault, major fault, or which are healthy. A benchmark is provided to compare the psychoacoustic features with different types of envelope features based on expert knowledge of the gearbox. To the best of our knowledge, we are the first to apply time-varying psychoacoustic features for fault detection. We train a state-of-the-art one-class-classifier, on samples from healthy motors and separate the faulty ones for fault detection using a threshold. The best-performing approaches achieve an area under curve of 0.87 (logarithm envelope), 0.86 (time-varying psychoacoustics), and 0.91 (combination of both).
Towards Efficient ECG-based Atrial Fibrillation Detection via Parameterised Hypercomplex Neural Networks
Oct 27, 2022



Atrial fibrillation (AF) is the most common cardiac arrhythmia and associated with a higher risk for serious conditions like stroke. Long-term recording of the electrocardiogram (ECG) with wearable devices embedded with an automatic and timely evaluation of AF helps to avoid life-threatening situations. However, the use of a deep neural network for auto-analysis of ECG on wearable devices is limited by its complexity. In this work, we propose lightweight convolutional neural networks (CNNs) for AF detection inspired by the recently proposed parameterised hypercomplex (PH) neural networks. Specifically, the convolutional and fully-connected layers of a real-valued CNN are replaced by PH convolutions and multiplications, respectively. PH layers are flexible to operate in any channel dimension n and able to capture inter-channel relations. We evaluate PH-CNNs on publicly available databases of dynamic and in-hospital ECG recordings and show comparable performance to corresponding real-valued CNNs while using approx. $1/n$ model parameters.
Knowledge Transfer For On-Device Speech Emotion Recognition with Neural Structured Learning
Oct 26, 2022



Speech emotion recognition (SER) has been a popular research topic in human-computer interaction (HCI). As edge devices are rapidly springing up, applying SER to edge devices is promising for a huge number of HCI applications. Although deep learning has been investigated to improve the performance of SER by training complex models, the memory space and computational capability of edge devices represents a constraint for embedding deep learning models. We propose a neural structured learning (NSL) framework through building synthesized graphs. An SER model is trained on a source dataset and used to build graphs on a target dataset. A lightweight model is then trained with the speech samples and graphs together as the input. Our experiments demonstrate that training a lightweight SER model on the target dataset with speech samples and graphs can not only produce small SER models, but also enhance the model performance over models with speech samples only.
Fast Yet Effective Speech Emotion Recognition with Self-distillation
Oct 26, 2022



Speech emotion recognition (SER) is the task of recognising human's emotional states from speech. SER is extremely prevalent in helping dialogue systems to truly understand our emotions and become a trustworthy human conversational partner. Due to the lengthy nature of speech, SER also suffers from the lack of abundant labelled data for powerful models like deep neural networks. Pre-trained complex models on large-scale speech datasets have been successfully applied to SER via transfer learning. However, fine-tuning complex models still requires large memory space and results in low inference efficiency. In this paper, we argue achieving a fast yet effective SER is possible with self-distillation, a method of simultaneously fine-tuning a pretrained model and training shallower versions of itself. The benefits of our self-distillation framework are threefold: (1) the adoption of self-distillation method upon the acoustic modality breaks through the limited ground-truth of speech data, and outperforms the existing models' performance on an SER dataset; (2) executing powerful models at different depth can achieve adaptive accuracy-efficiency trade-offs on resource-limited edge devices; (3) a new fine-tuning process rather than training from scratch for self-distillation leads to faster learning time and the state-of-the-art accuracy on data with small quantities of label information.
Towards KAB2S: Learning Key Knowledge from Single-Objective Problems to Multi-Objective Problem
Jun 26, 2022



As "a new frontier in evolutionary computation research", evolutionary transfer optimization(ETO) will overcome the traditional paradigm of zero reuse of related experience and knowledge from solved past problems in researches of evolutionary computation. In scheduling applications via ETO, a quite appealing and highly competitive framework "meeting" between them could be formed for both intelligent scheduling and green scheduling, especially for international pledge of "carbon neutrality" from China. To the best of our knowledge, our paper on scheduling here, serves as the 1st work of a class of ETO frameworks when multiobjective optimization problem "meets" single-objective optimization problems in discrete case (not multitasking optimization). More specifically, key knowledge conveyed for industrial applications, like positional building blocks with genetic algorithm based settings, could be used via the new core transfer mechanism and learning techniques for permutation flow shop scheduling problem(PFSP). Extensive studies on well-studied benchmarks validate firm effectiveness and great universality of our proposed ETO-PFSP framework empirically. Our investigations (1) enrich the ETO frameworks, (2) contribute to the classical and fundamental theory of building block for genetic algorithms and memetic algorithms, and (3) head towards the paradigm shift of evolutionary scheduling via learning by proposal and practice of paradigm of "knowledge and building-block based scheduling" (KAB2S) for "industrial intelligence" in China.
Example-based Explanations with Adversarial Attacks for Respiratory Sound Analysis
Mar 30, 2022



Respiratory sound classification is an important tool for remote screening of respiratory-related diseases such as pneumonia, asthma, and COVID-19. To facilitate the interpretability of classification results, especially ones based on deep learning, many explanation methods have been proposed using prototypes. However, existing explanation techniques often assume that the data is non-biased and the prediction results can be explained by a set of prototypical examples. In this work, we develop a unified example-based explanation method for selecting both representative data (prototypes) and outliers (criticisms). In particular, we propose a novel application of adversarial attacks to generate an explanation spectrum of data instances via an iterative fast gradient sign method. Such unified explanation can avoid over-generalisation and bias by allowing human experts to assess the model mistakes case by case. We performed a wide range of quantitative and qualitative evaluations to show that our approach generates effective and understandable explanation and is robust with many deep learning models