 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective In-Context Example Selection through Data Compression
May 19, 2024In-context learning has been extensively validated in large language models. However, the mechanism and selection strategy for in-context example selection, which is a crucial ingredient in this approach, lacks systematic and in-depth research. In this paper, we propose a data compression approach to the selection of in-context examples. We introduce a two-stage method that can effectively choose relevant examples and retain sufficient information about the training dataset within the in-context examples. Our method shows a significant improvement of an average of 5.90% across five different real-world datasets using four language models.
To Search or to Recommend: Predicting Open-App Motivation with Neural Hawkes Process
Apr 04, 2024



Incorporating Search and Recommendation (S&R) services within a singular application is prevalent in online platforms, leading to a new task termed open-app motivation prediction, which aims to predict whether users initiate the application with the specific intent of information searching, or to explore recommended content for entertainment. Studies have shown that predicting users' motivation to open an app can help to improve user engagement and enhance performance in various downstream tasks. However, accurately predicting open-app motivation is not trivial, as it is influenced by user-specific factors, search queries, clicked items, as well as their temporal occurrences. Furthermore, these activities occur sequentially and exhibit intricate temporal dependencies. Inspired by the success of the Neural Hawkes Process (NHP) in modeling temporal dependencies in sequences, this paper proposes a novel neural Hawkes process model to capture the temporal dependencies between historical user browsing and querying actions. The model, referred to as Neural Hawkes Process-based Open-App Motivation prediction model (NHP-OAM), employs a hierarchical transformer and a novel intensity function to encode multiple factors, and open-app motivation prediction layer to integrate time and user-specific information for predicting users' open-app motivations. To demonstrate the superiority of our NHP-OAM model and construct a benchmark for the Open-App Motivation Prediction task, we not only extend the public S&R dataset ZhihuRec but also construct a new real-world Open-App Motivation Dataset (OAMD). Experiments on these two datasets validate NHP-OAM's superiority over baseline models. Further downstream application experiments demonstrate NHP-OAM's effectiveness in predicting users' Open-App Motivation, highlighting the immense application value of NHP-OAM.
Exploring the Nexus of Large Language Models and Legal Systems: A Short Survey
Apr 01, 2024With the advancement of Artificial Intelligence (AI) and Large Language Models (LLMs), there is a profound transformation occurring in the realm of natural language processing tasks within the legal domain. The capabilities of LLMs are increasingly demonstrating unique roles in the legal sector, bringing both distinctive benefits and various challenges. This survey delves into the synergy between LLMs and the legal system, such as their applications in tasks like legal text comprehension, case retrieval, and analysis. Furthermore, this survey highlights key challenges faced by LLMs in the legal domain, including bias, interpretability, and ethical considerations, as well as how researchers are addressing these issues. The survey showcases the latest advancements in fine-tuned legal LLMs tailored for various legal systems, along with legal datasets available for fine-tuning LLMs in various languages. Additionally, it proposes directions for future research and development.
Large Language Models Enhanced Collaborative Filtering
Mar 26, 2024



Recent advancements in Large Language Models (LLMs) have attracted considerable interest among researchers to leverage these models to enhance Recommender Systems (RSs). Existing work predominantly utilizes LLMs to generate knowledge-rich texts or utilizes LLM-derived embeddings as features to improve RSs. Although the extensive world knowledge embedded in LLMs generally benefits RSs, the application can only take limited number of users and items as inputs, without adequately exploiting collaborative filtering information. Considering its crucial role in RSs, one key challenge in enhancing RSs with LLMs lies in providing better collaborative filtering information through LLMs. In this paper, drawing inspiration from the in-context learning and chain of thought reasoning in LLMs, we propose the Large Language Models enhanced Collaborative Filtering (LLM-CF) framework, which distils the world knowledge and reasoning capabilities of LLMs into collaborative filtering. We also explored a concise and efficient instruction-tuning method, which improves the recommendation capabilities of LLMs while preserving their general functionalities (e.g., not decreasing on the LLM benchmark). Comprehensive experiments on three real-world datasets demonstrate that LLM-CF significantly enhances several backbone recommendation models and consistently outperforms competitive baselines, showcasing its effectiveness in distilling the world knowledge and reasoning capabilities of LLM into collaborative filtering.
Logic Rules as Explanations for Legal Case Retrieval
Mar 03, 2024
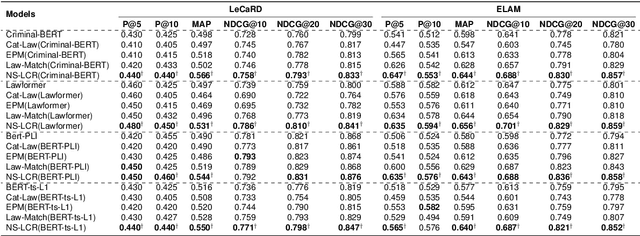
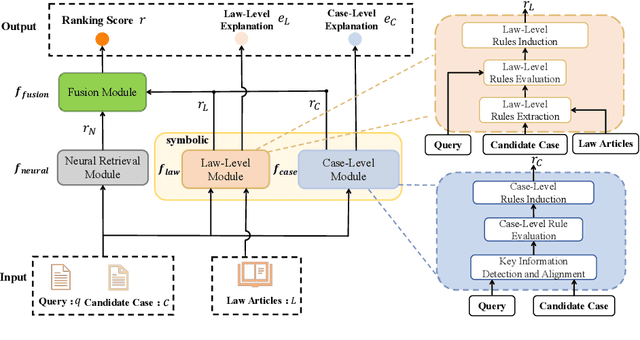
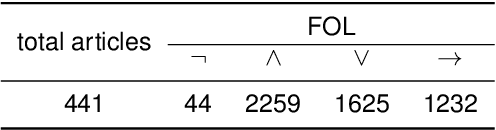
In this paper, we address the issue of using logic rules to explain the results from legal case retrieval. The task is critical to legal case retrieval because the users (e.g., lawyers or judges) are highly specialized and require the system to provide logical, faithful, and interpretable explanations before making legal decisions. Recently, research efforts have been made to learn explainable legal case retrieval models. However, these methods usually select rationales (key sentences) from the legal cases as explanations, failing to provide faithful and logically correct explanations. In this paper, we propose Neural-Symbolic enhanced Legal Case Retrieval (NS-LCR), a framework that explicitly conducts reasoning on the matching of legal cases through learning case-level and law-level logic rules. The learned rules are then integrated into the retrieval process in a neuro-symbolic manner. Benefiting from the logic and interpretable nature of the logic rules, NS-LCR is equipped with built-in faithful explainability. We also show that NS-LCR is a model-agnostic framework that can be plugged in for multiple legal retrieval models. To showcase NS-LCR's superiority, we enhance existing benchmarks by adding manually annotated logic rules and introducing a novel explainability metric using Large Language Models (LLMs). Our comprehensive experiments reveal NS-LCR's effectiveness for ranking, alongside its proficiency in delivering reliable explanations for legal case retrieval.
Generative Retrieval with Semantic Tree-Structured Item Identifiers via Contrastive Learning
Sep 23, 2023



The retrieval phase is a vital component in recommendation systems, requiring the model to be effective and efficient. Recently, generative retrieval has become an emerging paradigm for document retrieval, showing notable performance. These methods enjoy merits like being end-to-end differentiable, suggesting their viability in recommendation. However, these methods fall short in efficiency and effectiveness for large-scale recommendations. To obtain efficiency and effectiveness, this paper introduces a generative retrieval framework, namely SEATER, which learns SEmAntic Tree-structured item identifiERs via contrastive learning. Specifically, we employ an encoder-decoder model to extract user interests from historical behaviors and retrieve candidates via tree-structured item identifiers. SEATER devises a balanced k-ary tree structure of item identifiers, allocating semantic space to each token individually. This strategy maintains semantic consistency within the same level, while distinct levels correlate to varying semantic granularities. This structure also maintains consistent and fast inference speed for all items. Considering the tree structure, SEATER learns identifier tokens' semantics, hierarchical relationships, and inter-token dependencies. To achieve this, we incorporate two contrastive learning tasks with the generation task to optimize both the model and identifiers. The infoNCE loss aligns the token embeddings based on their hierarchical positions. The triplet loss ranks similar identifiers in desired orders. In this way, SEATER achieves both efficiency and effectiveness. Extensive experiments on three public datasets and an industrial dataset have demonstrated that SEATER outperforms state-of-the-art models significantly.
KuaiSAR: A Unified Search And Recommendation Dataset
Jun 18, 2023



The confluence of Search and Recommendation (S&R) services is vital to online services, including e-commerce and video platforms. The integration of S&R modeling is a highly intuitive approach adopted by industry practitioners. However, there is a noticeable lack of research conducted in this area within academia, primarily due to the absence of publicly available datasets. Consequently, a substantial gap has emerged between academia and industry regarding research endeavors in joint optimization using user behavior data from both S&R services. To bridge this gap, we introduce the first large-scale, real-world dataset KuaiSAR of integrated Search And Recommendation behaviors collected from Kuaishou, a leading short-video app in China with over 350 million daily active users. Previous research in this field has predominantly employed publicly available semi-synthetic datasets and simulated, with artificially fabricated search behaviors. Distinct from previous datasets, KuaiSAR contains genuine user behaviors, including the occurrence of each interaction within either search or recommendation service, and the users' transitions between the two services. This work aids in joint modeling of S&R, and utilizing search data for recommender systems (and recommendation data for search engines). Furthermore, due to the various feedback labels associated with user-video interactions, KuaiSAR also supports a broad range of tasks, including intent recommendation, multi-task learning, and modeling of long sequential multi-behavioral patterns. We believe this dataset will serve as a catalyst for innovative research and bridge the gap between academia and industry in understanding the S&R services in practical, real-world applications.
When Search Meets Recommendation: Learning Disentangled Search Representation for Recommendation
May 18, 2023



Modern online service providers such as online shopping platforms often provide both search and recommendation (S&R) services to meet different user needs. Rarely has there been any effective means of incorporating user behavior data from both S&R services. Most existing approaches either simply treat S&R behaviors separately, or jointly optimize them by aggregating data from both services, ignoring the fact that user intents in S&R can be distinctively different. In our paper, we propose a Search-Enhanced framework for the Sequential Recommendation (SESRec) that leverages users' search interests for recommendation, by disentangling similar and dissimilar representations within S&R behaviors. Specifically, SESRec first aligns query and item embeddings based on users' query-item interactions for the computations of their similarities. Two transformer encoders are used to learn the contextual representations of S&R behaviors independently. Then a contrastive learning task is designed to supervise the disentanglement of similar and dissimilar representations from behavior sequences of S&R. Finally, we extract user interests by the attention mechanism from three perspectives, i.e., the contextual representations, the two separated behaviors containing similar and dissimilar interests. Extensive experiments on both industrial and public datasets demonstrate that SESRec consistently outperforms state-of-the-art models. Empirical studies further validate that SESRec successfully disentangle similar and dissimilar user interests from their S&R behaviors.
Uncovering ChatGPT's Capabilities in Recommender Systems
May 11, 2023



The debut of ChatGPT has recently attracted the attention of the natural language processing (NLP) community and beyond. Existing studies have demonstrated that ChatGPT shows significant improvement in a range of downstream NLP tasks, but the capabilities and limitations of ChatGPT in terms of recommendations remain unclear. In this study, we aim to conduct an empirical analysis of ChatGPT's recommendation ability from an Information Retrieval (IR) perspective, including point-wise, pair-wise, and list-wise ranking. To achieve this goal, we re-formulate the above three recommendation policies into a domain-specific prompt format. Through extensive experiments on four datasets from different domains, we demonstrate that ChatGPT outperforms other large language models across all three ranking policies. Based on the analysis of unit cost improvements, we identify that ChatGPT with list-wise ranking achieves the best trade-off between cost and performance compared to point-wise and pair-wise ranking. Moreover, ChatGPT shows the potential for mitigating the cold start problem and explainable recommendation. To facilitate further explorations in this area, the full code and detailed original results are open-sourced at https://github.com/rainym00d/LLM4RS.
A Short Survey of Viewing Large Language Models in Legal Aspect
Mar 16, 2023

Large language models (LLMs) have transformed many fields, including natural language processing, computer vision, and reinforcement learning. These models have also made a significant impact in the field of law, where they are being increasingly utilized to automate various legal tasks, such as legal judgement prediction, legal document analysis, and legal document writing. However, the integration of LLMs into the legal field has also raised several legal problems, including privacy concerns, bias, and explainability. In this survey, we explore the integration of LLMs into the field of law. We discuss the various applications of LLMs in legal tasks, examine the legal challenges that arise from their use, and explore the data resources that can be used to specialize LLMs in the legal domain. Finally, we discuss several promising directions and conclude this paper. By doing so, we hope to provide an overview of the current state of LLMs in law and highlight the potential benefits and challenges of their integration.