 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Customized Medical Decision Algorithms Utilizing Graph Neural Networks
May 23, 2024Aiming at the limitations of traditional medical decision system in processing large-scale heterogeneous medical data and realizing highly personalized recommendation, this paper introduces a personalized medical decision algorithm utilizing graph neural network (GNN). This research innovatively integrates graph neural network technology into the medical and health field, aiming to build a high-precision representation model of patient health status by mining the complex association between patients' clinical characteristics, genetic information, living habits. In this study, medical data is preprocessed to transform it into a graph structure, where nodes represent different data entities (such as patients, diseases, genes, etc.) and edges represent interactions or relationships between entities. The core of the algorithm is to design a novel multi-scale fusion mechanism, combining the historical medical records, physiological indicators and genetic characteristics of patients, to dynamically adjust the attention allocation strategy of the graph neural network, so as to achieve highly customized analysis of individual cases. In the experimental part, this study selected several publicly available medical data sets for validation, and the results showed that compared with traditional machine learning methods and a single graph neural network model, the proposed personalized medical decision algorithm showed significantly superior performance in terms of disease prediction accuracy, treatment effect evaluation and patient risk stratification.
Imp: Highly Capable Large Multimodal Models for Mobile Devices
May 20, 2024By harnessing the capabilities of large language models (LLMs), recent large multimodal models (LMMs) have shown remarkable versatility in open-world multimodal understanding. Nevertheless, they are usually parameter-heavy and computation-intensive, thus hindering their applicability in resource-constrained scenarios. To this end, several lightweight LMMs have been proposed successively to maximize the capabilities under constrained scale (e.g., 3B). Despite the encouraging results achieved by these methods, most of them only focus on one or two aspects of the design space, and the key design choices that influence model capability have not yet been thoroughly investigated. In this paper, we conduct a systematic study for lightweight LMMs from the aspects of model architecture, training strategy, and training data. Based on our findings, we obtain Imp -- a family of highly capable LMMs at the 2B-4B scales. Notably, our Imp-3B model steadily outperforms all the existing lightweight LMMs of similar size, and even surpasses the state-of-the-art LMMs at the 13B scale. With low-bit quantization and resolution reduction techniques, our Imp model can be deployed on a Qualcomm Snapdragon 8Gen3 mobile chip with a high inference speed of about 13 tokens/s.
Research on Intelligent Aided Diagnosis System of Medical Image Based on Computer Deep Learning
Apr 29, 2024This paper combines Struts and Hibernate two architectures together, using DAO (Data Access Object) to store and access data. Then a set of dual-mode humidity medical image library suitable for deep network is established, and a dual-mode medical image assisted diagnosis method based on the image is proposed. Through the test of various feature extraction methods, the optimal operating characteristic under curve product (AUROC) is 0.9985, the recall rate is 0.9814, and the accuracy is 0.9833. This method can be applied to clinical diagnosis, and it is a practical method. Any outpatient doctor can register quickly through the system, or log in to the platform to upload the image to obtain more accurate images. Through the system, each outpatient physician can quickly register or log in to the platform for image uploading, thus obtaining more accurate images. The segmentation of images can guide doctors in clinical departments. Then the image is analyzed to determine the location and nature of the tumor, so as to make targeted treatment.
Effective Unsupervised Constrained Text Generation based on Perturbed Masking
Apr 24, 2024Unsupervised constrained text generation aims to generate text under a given set of constraints without any supervised data. Current state-of-the-art methods stochastically sample edit positions and actions, which may cause unnecessary search steps. In this paper, we propose PMCTG to improve effectiveness by searching for the best edit position and action in each step. Specifically, PMCTG extends perturbed masking technique to effectively search for the most incongruent token to edit. Then it introduces four multi-aspect scoring functions to select edit action to further reduce search difficulty. Since PMCTG does not require supervised data, it could be applied to different generation tasks. We show that under the unsupervised setting, PMCTG achieves new state-of-the-art results in two representative tasks, namely keywords-to-sentence generation and paraphrasing.
Using Adaptive Empathetic Responses for Teaching English
Apr 21, 2024Existing English-teaching chatbots rarely incorporate empathy explicitly in their feedback, but empathetic feedback could help keep students engaged and reduce learner anxiety. Toward this end, we propose the task of negative emotion detection via audio, for recognizing empathetic feedback opportunities in language learning. We then build the first spoken English-teaching chatbot with adaptive, empathetic feedback. This feedback is synthesized through automatic prompt optimization of ChatGPT and is evaluated with English learners. We demonstrate the effectiveness of our system through a preliminary user study.
Semi-supervised Fréchet Regression
Apr 16, 2024This paper explores the field of semi-supervised Fr\'echet regression, driven by the significant costs associated with obtaining non-Euclidean labels. Methodologically, we propose two novel methods: semi-supervised NW Fr\'echet regression and semi-supervised kNN Fr\'echet regression, both based on graph distance acquired from all feature instances. These methods extend the scope of existing semi-supervised Euclidean regression methods. We establish their convergence rates with limited labeled data and large amounts of unlabeled data, taking into account the low-dimensional manifold structure of the feature space. Through comprehensive simulations across diverse settings and applications to real data, we demonstrate the superior performance of our methods over their supervised counterparts. This study addresses existing research gaps and paves the way for further exploration and advancements in the field of semi-supervised Fr\'echet regression.
AttentionStore: Cost-effective Attention Reuse across Multi-turn Conversations in Large Language Model Serving
Mar 23, 2024Interacting with humans through multi-turn conversations is a fundamental feature of large language models (LLMs). However, existing LLM serving engines for executing multi-turn conversations are inefficient due to the need to repeatedly compute the key-value (KV) caches of historical tokens, incurring high serving costs. To address the problem, this paper proposes AttentionStore, a new attention mechanism that enables the reuse of KV caches (i.e., attention reuse) across multi-turn conversations, significantly reducing the repetitive computation overheads. AttentionStore maintains a hierarchical KV caching system that leverages cost-effective memory/storage mediums to save KV caches for all requests. To reduce KV cache access overheads from slow mediums, AttentionStore employs layer-wise pre-loading and asynchronous saving schemes to overlap the KV cache access with the GPU computation. To ensure that the KV caches to be accessed are placed in the fastest hierarchy, AttentionStore employs scheduler-aware fetching and eviction schemes to consciously place the KV caches in different layers based on the hints from the inference job scheduler. To avoid the invalidation of the saved KV caches incurred by context window overflow, AttentionStore enables the saved KV caches to remain valid via decoupling the positional encoding and effectively truncating the KV caches. Extensive experimental results demonstrate that AttentionStore significantly decreases the time to the first token (TTFT) by up to 88%, improves the prompt prefilling throughput by 8.2$\times$ for multi-turn conversations, and reduces the end-to-end inference cost by up to 56%. For long sequence inference, AttentionStore reduces the TTFT by up to 95% and improves the prompt prefilling throughput by 22$\times$.
LocalRQA: From Generating Data to Locally Training, Testing, and Deploying Retrieval-Augmented QA Systems
Mar 01, 2024



Retrieval-augmented question-answering systems combine retrieval techniques with large language models to provide answers that are more accurate and informative. Many existing toolkits allow users to quickly build such systems using off-the-shelf models, but they fall short in supporting researchers and developers to customize the model training, testing, and deployment process. We propose LocalRQA, an open-source toolkit that features a wide selection of model training algorithms, evaluation methods, and deployment tools curated from the latest research. As a showcase, we build QA systems using online documentation obtained from Databricks and Faire's websites. We find 7B-models trained and deployed using LocalRQA reach a similar performance compared to using OpenAI's text-ada-002 and GPT-4-turbo.
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Feb 23, 2024
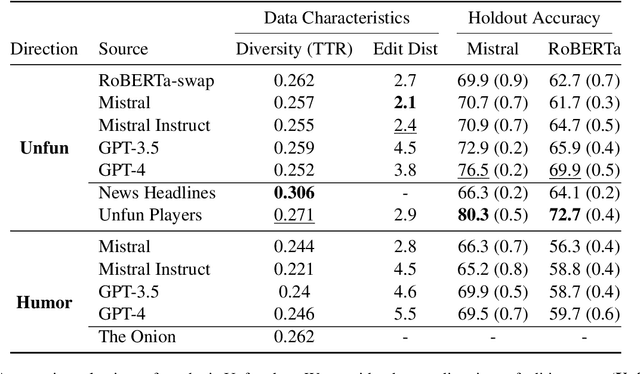
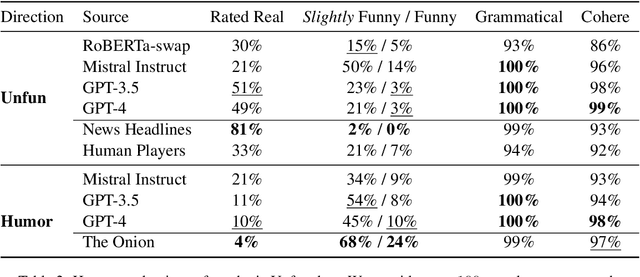
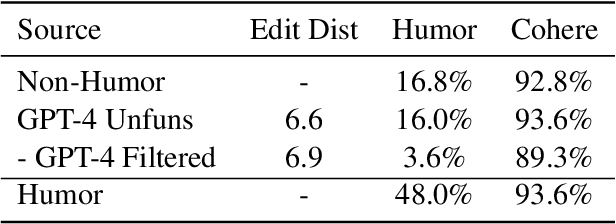
Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to `unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
Parallel Structures in Pre-training Data Yield In-Context Learning
Feb 19, 2024Pre-trained language models (LMs) are capable of in-context learning (ICL): they can adapt to a task with only a few examples given in the prompt without any parameter update. However, it is unclear where this capability comes from as there is a stark distribution shift between pre-training text and ICL prompts. In this work, we study what patterns of the pre-training data contribute to ICL. We find that LMs' ICL ability depends on $\textit{parallel structures}$ in the pre-training data -- pairs of phrases following similar templates in the same context window. Specifically, we detect parallel structures by checking whether training on one phrase improves prediction of the other, and conduct ablation experiments to study their effect on ICL. We show that removing parallel structures in the pre-training data reduces LMs' ICL accuracy by 51% (vs 2% from random ablation). This drop persists even when excluding common patterns such as n-gram repetitions and long-range dependency, showing the diversity and generality of parallel structures. A closer look at the detected parallel structures indicates that they cover diverse linguistic tasks and span long distances in the data.