 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSean O'Brien
PathFinder: Guided Search over Multi-Step Reasoning Paths
Dec 12, 2023
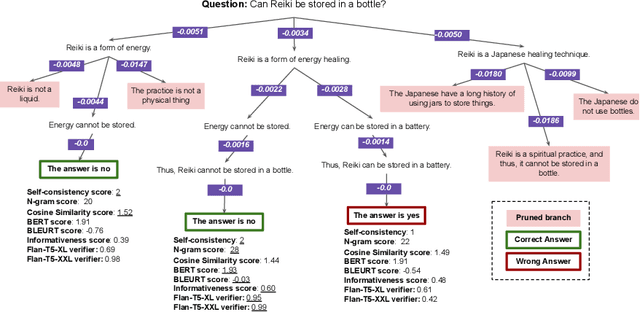

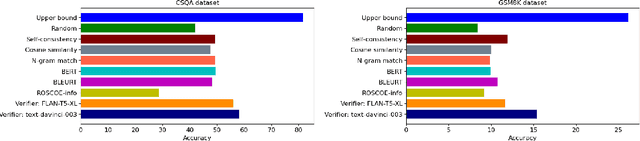
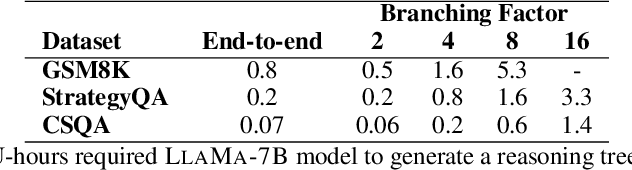
With recent advancements in large language models, methods like chain-of-thought prompting to elicit reasoning chains have been shown to improve results on reasoning tasks. However, tasks that require multiple steps of reasoning still pose significant challenges to state-of-the-art models. Drawing inspiration from the beam search algorithm, we propose PathFinder, a tree-search-based reasoning path generation approach. It enhances diverse branching and multi-hop reasoning through the integration of dynamic decoding, enabled by varying sampling methods and parameters. Using constrained reasoning, PathFinder integrates novel quality constraints, pruning, and exploration methods to enhance the efficiency and the quality of generation. Moreover, it includes scoring and ranking features to improve candidate selection. Our approach outperforms competitive baselines on three complex arithmetic and commonsense reasoning tasks by 6% on average. Our model generalizes well to longer, unseen reasoning chains, reflecting similar complexities to beam search with large branching factors.
Contrastive Decoding Improves Reasoning in Large Language Models
Sep 29, 2023We demonstrate that Contrastive Decoding -- a simple, computationally light, and training-free text generation method proposed by Li et al 2022 -- achieves large out-of-the-box improvements over greedy decoding on a variety of reasoning tasks. Originally shown to improve the perceived quality of long-form text generation, Contrastive Decoding searches for strings that maximize a weighted difference in likelihood between strong and weak models. We show that Contrastive Decoding leads LLaMA-65B to outperform LLaMA 2, GPT-3.5 and PaLM 2-L on the HellaSwag commonsense reasoning benchmark, and to outperform LLaMA 2, GPT-3.5 and PaLM-540B on the GSM8K math word reasoning benchmark, in addition to improvements on a collection of other tasks. Analysis suggests that Contrastive Decoding improves over existing methods by preventing some abstract reasoning errors, as well as by avoiding simpler modes such as copying sections of the input during chain-of-thought. Overall, Contrastive Decoding outperforms nucleus sampling for long-form generation and greedy decoding for reasoning tasks, making it a powerful general purpose method for generating text from language models.
Shepherd: A Critic for Language Model Generation
Aug 08, 2023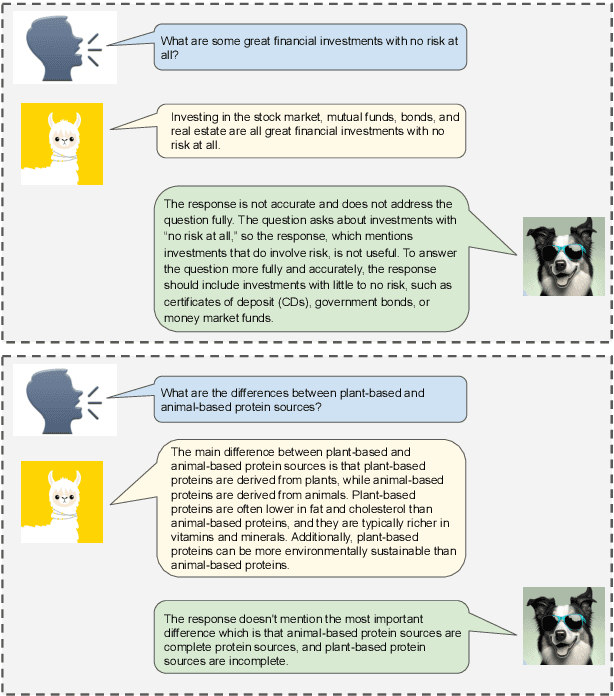

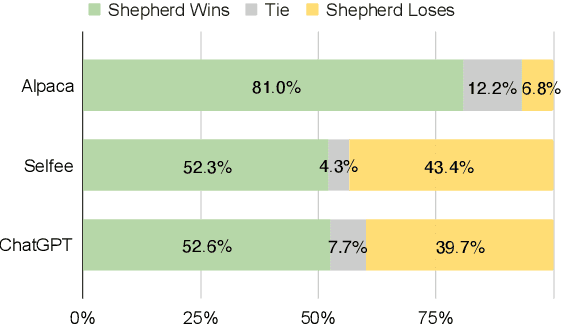

As large language models improve, there is increasing interest in techniques that leverage these models' capabilities to refine their own outputs. In this work, we introduce Shepherd, a language model specifically tuned to critique responses and suggest refinements, extending beyond the capabilities of an untuned model to identify diverse errors and provide suggestions to remedy them. At the core of our approach is a high quality feedback dataset, which we curate from community feedback and human annotations. Even though Shepherd is small (7B parameters), its critiques are either equivalent or preferred to those from established models including ChatGPT. Using GPT-4 for evaluation, Shepherd reaches an average win-rate of 53-87% compared to competitive alternatives. In human evaluation, Shepherd strictly outperforms other models and on average closely ties with ChatGPT.