
Find open-source code to catalyze your research
Get code for papers directly on Google, Arxiv, Scholar, Twitter, and more
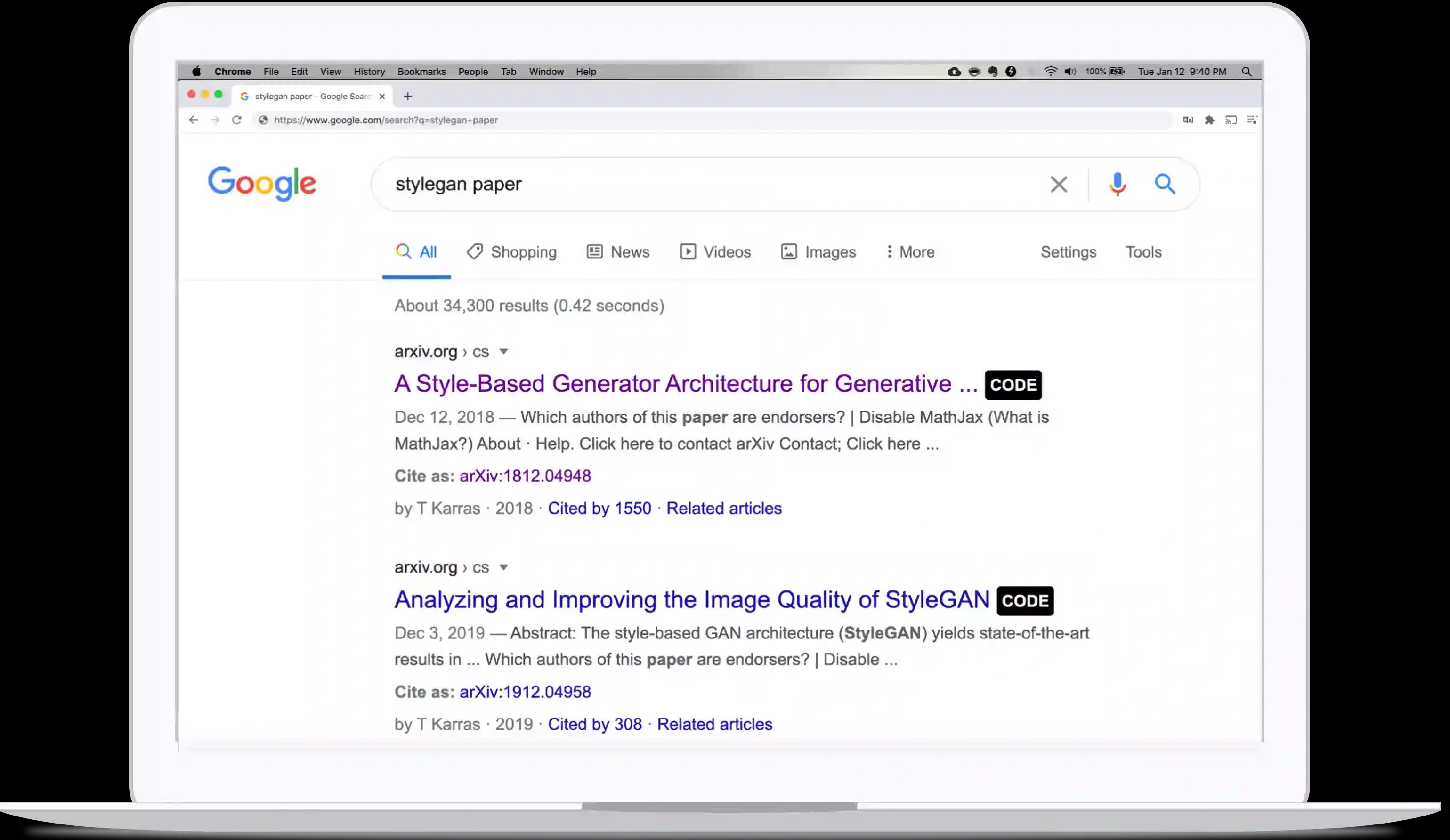
Loved by 50,000+ engineers & researchers
As seen on:


Popular topics:


Image-To-Image Translation
Style transfer from an image to another, super resolution (enhancement), image synthesis, etc.

Information Extraction
Named entity recognition, relationship extraction, website parsing, text parsing & analytics, etc.

Text Classification
Topic labeling and tagging, categorizing support tickets, spam detection, etc.


Join leading engineers & researchers from

