 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
GINopic: Topic Modeling with Graph Isomorphism Network
Apr 02, 2024
Topic modeling is a widely used approach for analyzing and exploring large document collections. Recent research efforts have incorporated pre-trained contextualized language models, such as BERT embeddings, into topic modeling. However, they often neglect the intrinsic informational value conveyed by mutual dependencies between words. In this study, we introduce GINopic, a topic modeling framework based on graph isomorphism networks to capture the correlation between words. By conducting intrinsic (quantitative as well as qualitative) and extrinsic evaluations on diverse benchmark datasets, we demonstrate the effectiveness of GINopic compared to existing topic models and highlight its potential for advancing topic modeling.
Neural Multimodal Topic Modeling: A Comprehensive Evaluation
Mar 26, 2024Neural topic models can successfully find coherent and diverse topics in textual data. However, they are limited in dealing with multimodal datasets (e.g., images and text). This paper presents the first systematic and comprehensive evaluation of multimodal topic modeling of documents containing both text and images. In the process, we propose two novel topic modeling solutions and two novel evaluation metrics. Overall, our evaluation on an unprecedented rich and diverse collection of datasets indicates that both of our models generate coherent and diverse topics. Nevertheless, the extent to which one method outperforms the other depends on the metrics and dataset combinations, which suggests further exploration of hybrid solutions in the future. Notably, our succinct human evaluation aligns with the outcomes determined by our proposed metrics. This alignment not only reinforces the credibility of our metrics but also highlights the potential for their application in guiding future multimodal topic modeling endeavors.
Membership Inference Attacks and Privacy in Topic Modeling
Mar 07, 2024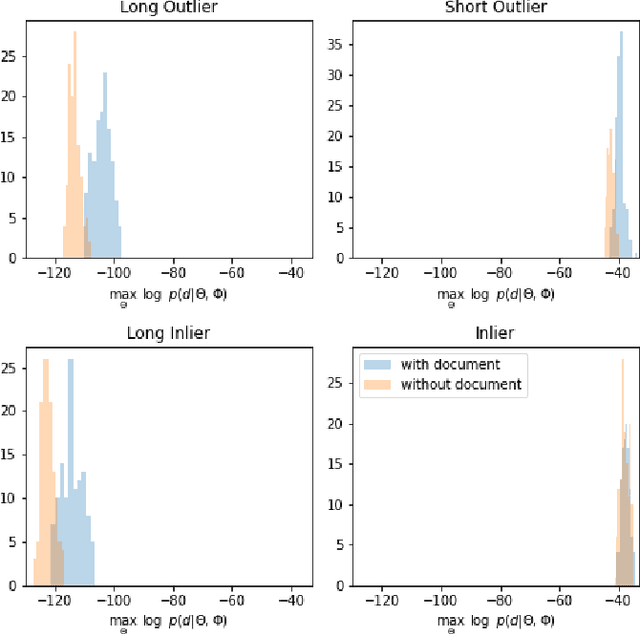
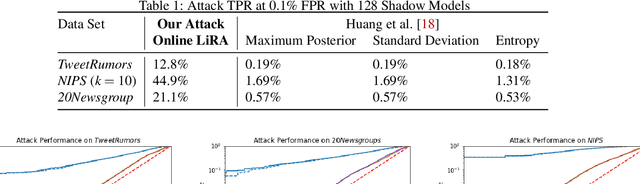
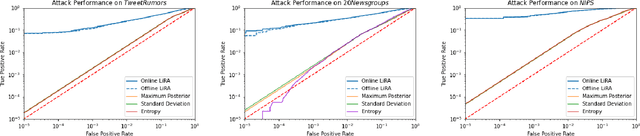
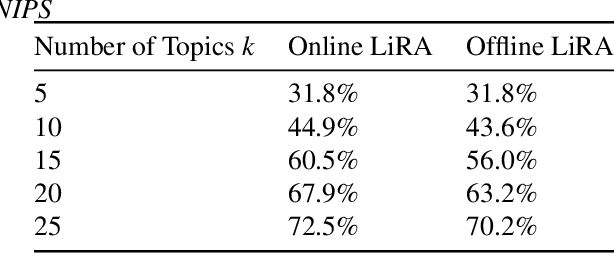
Recent research shows that large language models are susceptible to privacy attacks that infer aspects of the training data. However, it is unclear if simpler generative models, like topic models, share similar vulnerabilities. In this work, we propose an attack against topic models that can confidently identify members of the training data in Latent Dirichlet Allocation. Our results suggest that the privacy risks associated with generative modeling are not restricted to large neural models. Additionally, to mitigate these vulnerabilities, we explore differentially private (DP) topic modeling. We propose a framework for private topic modeling that incorporates DP vocabulary selection as a pre-processing step, and show that it improves privacy while having limited effects on practical utility.
Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM
Apr 18, 2024Data analysts have long sought to turn unstructured text data into meaningful concepts. Though common, topic modeling and clustering focus on lower-level keywords and require significant interpretative work. We introduce concept induction, a computational process that instead produces high-level concepts, defined by explicit inclusion criteria, from unstructured text. For a dataset of toxic online comments, where a state-of-the-art BERTopic model outputs "women, power, female," concept induction produces high-level concepts such as "Criticism of traditional gender roles" and "Dismissal of women's concerns." We present LLooM, a concept induction algorithm that leverages large language models to iteratively synthesize sampled text and propose human-interpretable concepts of increasing generality. We then instantiate LLooM in a mixed-initiative text analysis tool, enabling analysts to shift their attention from interpreting topics to engaging in theory-driven analysis. Through technical evaluations and four analysis scenarios ranging from literature review to content moderation, we find that LLooM's concepts improve upon the prior art of topic models in terms of quality and data coverage. In expert case studies, LLooM helped researchers to uncover new insights even from familiar datasets, for example by suggesting a previously unnoticed concept of attacks on out-party stances in a political social media dataset.
Uncovering Latent Arguments in Social Media Messaging by Employing LLMs-in-the-Loop Strategy
Apr 16, 2024The widespread use of social media has led to a surge in popularity for automated methods of analyzing public opinion. Supervised methods are adept at text categorization, yet the dynamic nature of social media discussions poses a continual challenge for these techniques due to the constant shifting of the focus. On the other hand, traditional unsupervised methods for extracting themes from public discourse, such as topic modeling, often reveal overarching patterns that might not capture specific nuances. Consequently, a significant portion of research into social media discourse still depends on labor-intensive manual coding techniques and a human-in-the-loop approach, which are both time-consuming and costly. In this work, we study the problem of discovering arguments associated with a specific theme. We propose a generic LLMs-in-the-Loop strategy that leverages the advanced capabilities of Large Language Models (LLMs) to extract latent arguments from social media messaging. To demonstrate our approach, we apply our framework to contentious topics. We use two publicly available datasets: (1) the climate campaigns dataset of 14k Facebook ads with 25 themes and (2) the COVID-19 vaccine campaigns dataset of 9k Facebook ads with 14 themes. Furthermore, we analyze demographic targeting and the adaptation of messaging based on real-world events.
A solution for the mean parametrization of the von Mises-Fisher distribution
Apr 10, 2024The von Mises-Fisher distribution as an exponential family can be expressed in terms of either its natural or its mean parameters. Unfortunately, however, the normalization function for the distribution in terms of its mean parameters is not available in closed form, limiting the practicality of the mean parametrization and complicating maximum-likelihood estimation more generally. We derive a second-order ordinary differential equation, the solution to which yields the mean-parameter normalizer along with its first two derivatives, as well as the variance function of the family. We also provide closed-form approximations to the solution of the differential equation. This allows rapid evaluation of both densities and natural parameters in terms of mean parameters. We show applications to topic modeling with mixtures of von Mises-Fisher distributions using Bregman Clustering.
Topic Modeling as Multi-Objective Contrastive Optimization
Feb 12, 2024Recent representation learning approaches enhance neural topic models by optimizing the weighted linear combination of the evidence lower bound (ELBO) of the log-likelihood and the contrastive learning objective that contrasts pairs of input documents. However, document-level contrastive learning might capture low-level mutual information, such as word ratio, which disturbs topic modeling. Moreover, there is a potential conflict between the ELBO loss that memorizes input details for better reconstruction quality, and the contrastive loss which attempts to learn topic representations that generalize among input documents. To address these issues, we first introduce a novel contrastive learning method oriented towards sets of topic vectors to capture useful semantics that are shared among a set of input documents. Secondly, we explicitly cast contrastive topic modeling as a gradient-based multi-objective optimization problem, with the goal of achieving a Pareto stationary solution that balances the trade-off between the ELBO and the contrastive objective. Extensive experiments demonstrate that our framework consistently produces higher-performing neural topic models in terms of topic coherence, topic diversity, and downstream performance.
Topic Modeling Analysis of Aviation Accident Reports: A Comparative Study between LDA and NMF Models
Mar 04, 2024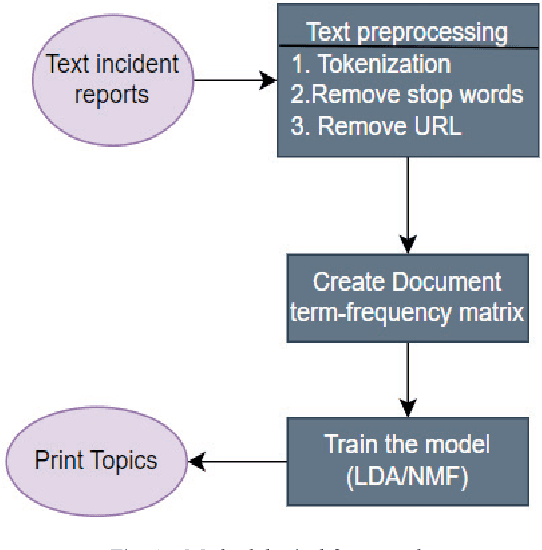
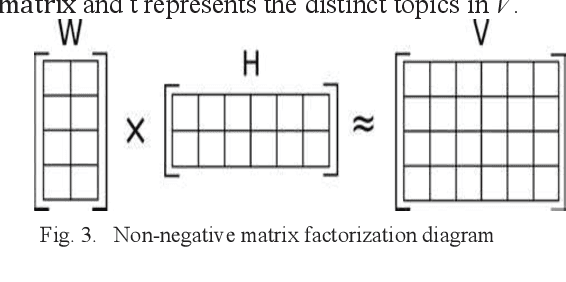
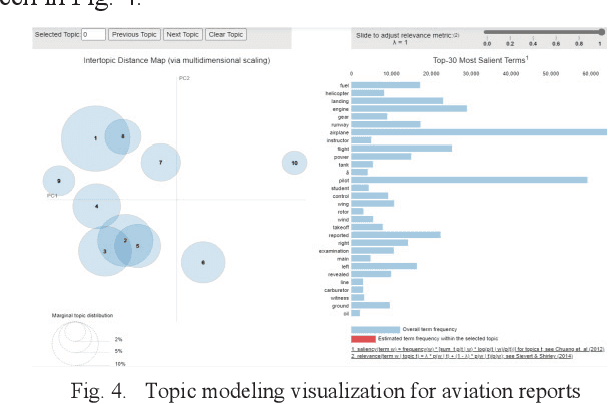
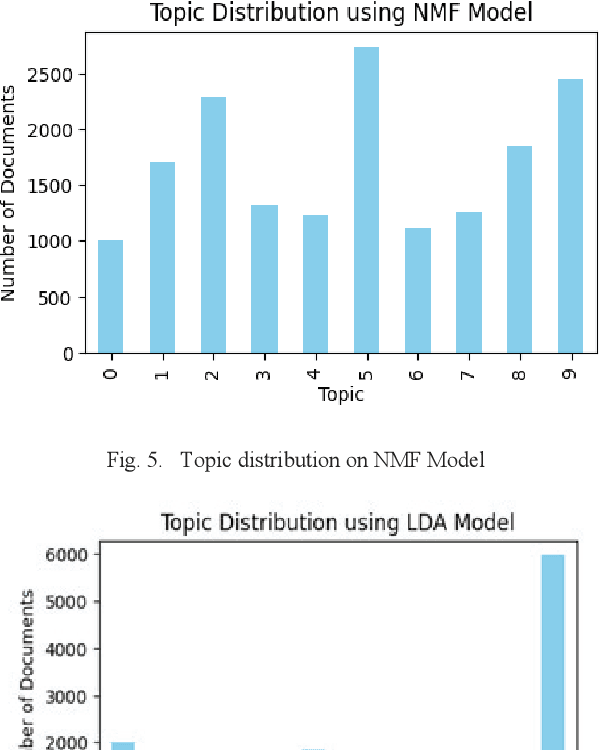
Aviation safety is paramount in the modern world, with a continuous commitment to reducing accidents and improving safety standards. Central to this endeavor is the analysis of aviation accident reports, rich textual resources that hold insights into the causes and contributing factors behind aviation mishaps. This paper compares two prominent topic modeling techniques, Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF), in the context of aviation accident report analysis. The study leverages the National Transportation Safety Board (NTSB) Dataset with the primary objective of automating and streamlining the process of identifying latent themes and patterns within accident reports. The Coherence Value (C_v) metric was used to evaluate the quality of generated topics. LDA demonstrates higher topic coherence, indicating stronger semantic relevance among words within topics. At the same time, NMF excelled in producing distinct and granular topics, enabling a more focused analysis of specific aspects of aviation accidents.
Dual Simplex Volume Maximization for Simplex-Structured Matrix Factorization
Mar 29, 2024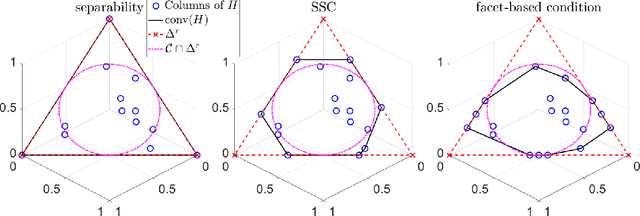
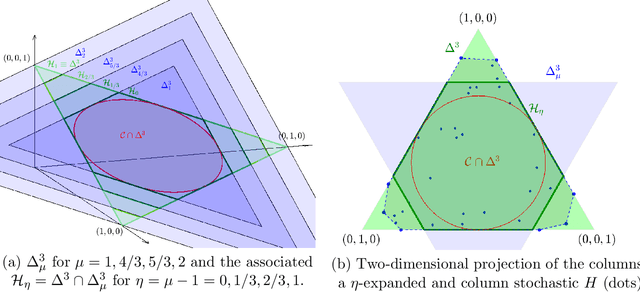
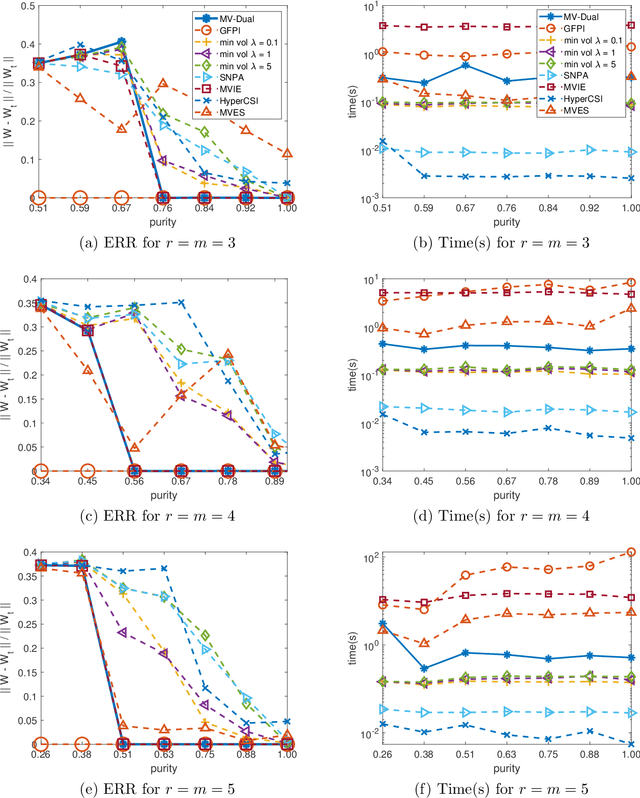
Simplex-structured matrix factorization (SSMF) is a generalization of nonnegative matrix factorization, a fundamental interpretable data analysis model, and has applications in hyperspectral unmixing and topic modeling. To obtain identifiable solutions, a standard approach is to find minimum-volume solutions. By taking advantage of the duality/polarity concept for polytopes, we convert minimum-volume SSMF in the primal space to a maximum-volume problem in the dual space. We first prove the identifiability of this maximum-volume dual problem. Then, we use this dual formulation to provide a novel optimization approach which bridges the gap between two existing families of algorithms for SSMF, namely volume minimization and facet identification. Numerical experiments show that the proposed approach performs favorably compared to the state-of-the-art SSMF algorithms.
On the Affinity, Rationality, and Diversity of Hierarchical Topic Modeling
Feb 01, 2024Hierarchical topic modeling aims to discover latent topics from a corpus and organize them into a hierarchy to understand documents with desirable semantic granularity. However, existing work struggles with producing topic hierarchies of low affinity, rationality, and diversity, which hampers document understanding. To overcome these challenges, we in this paper propose Transport Plan and Context-aware Hierarchical Topic Model (TraCo). Instead of early simple topic dependencies, we propose a transport plan dependency method. It constrains dependencies to ensure their sparsity and balance, and also regularizes topic hierarchy building with them. This improves affinity and diversity of hierarchies. We further propose a context-aware disentangled decoder. Rather than previously entangled decoding, it distributes different semantic granularity to topics at different levels by disentangled decoding. This facilitates the rationality of hierarchies. Experiments on benchmark datasets demonstrate that our method surpasses state-of-the-art baselines, effectively improving the affinity, rationality, and diversity of hierarchical topic modeling with better performance on downstream tasks.