 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring Relevant Feature Sets with Multiple Model Learning
Sep 05, 2012
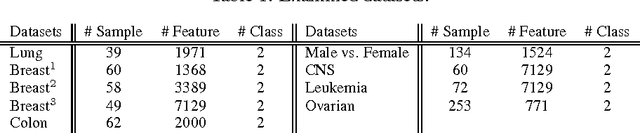
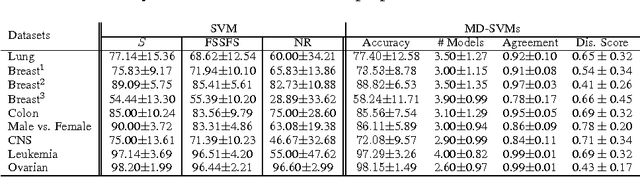

Feature selection is one of the most prominent learning tasks, especially in high-dimensional datasets in which the goal is to understand the mechanisms that underly the learning dataset. However most of them typically deliver just a flat set of relevant features and provide no further information on what kind of structures, e.g. feature groupings, might underly the set of relevant features. In this paper we propose a new learning paradigm in which our goal is to uncover the structures that underly the set of relevant features for a given learning problem. We uncover two types of features sets, non-replaceable features that contain important information about the target variable and cannot be replaced by other features, and functionally similar features sets that can be used interchangeably in learned models, given the presence of the non-replaceable features, with no change in the predictive performance. To do so we propose a new learning algorithm that learns a number of disjoint models using a model disjointness regularization constraint together with a constraint on the predictive agreement of the disjoint models. We explore the behavior of our approach on a number of high-dimensional datasets, and show that, as expected by their construction, these satisfy a number of properties. Namely, model disjointness, a high predictive agreement, and a similar predictive performance to models learned on the full set of relevant features. The ability to structure the set of relevant features in such a manner can become a valuable tool in different applications of scientific knowledge discovery.