Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel coordinate descent for the Adaboost problem
Oct 07, 2013
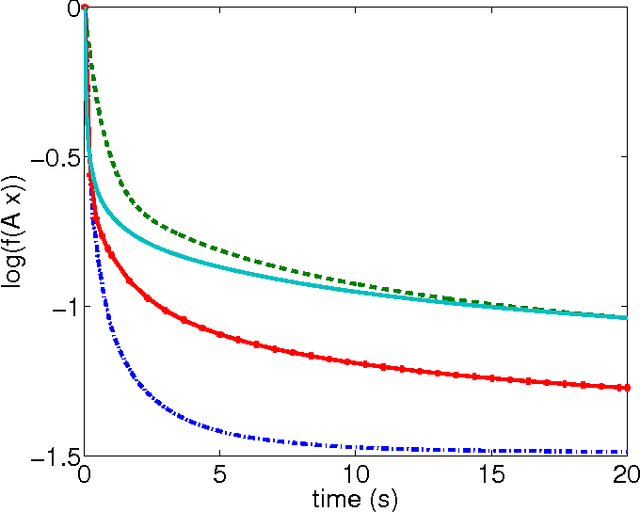
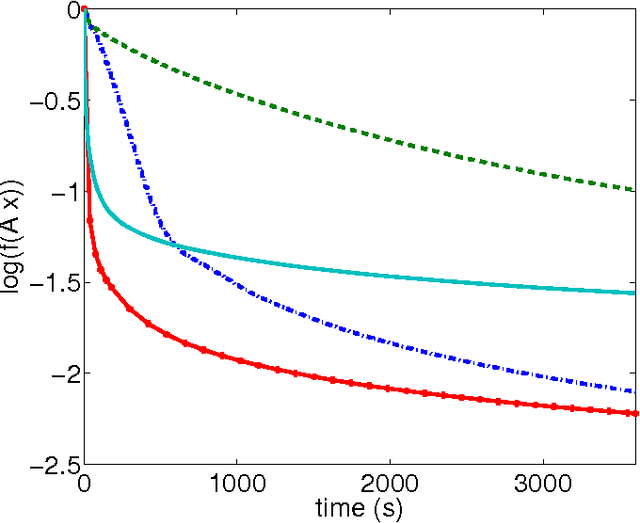
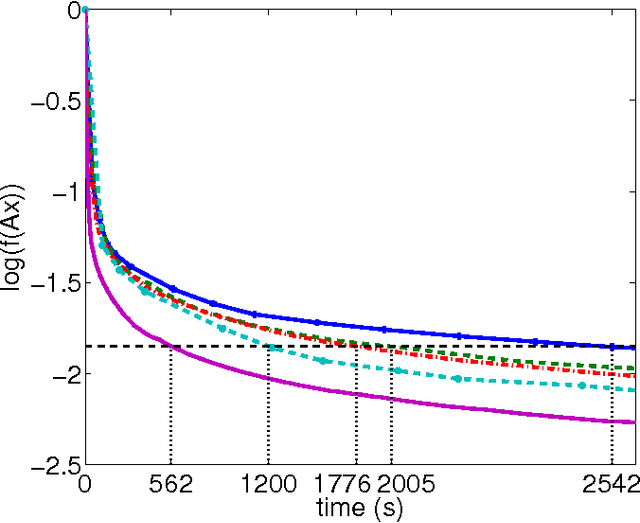
We design a randomised parallel version of Adaboost based on previous studies on parallel coordinate descent. The algorithm uses the fact that the logarithm of the exponential loss is a function with coordinate-wise Lipschitz continuous gradient, in order to define the step lengths. We provide the proof of convergence for this randomised Adaboost algorithm and a theoretical parallelisation speedup factor. We finally provide numerical examples on learning problems of various sizes that show that the algorithm is competitive with concurrent approaches, especially for large scale problems.
* 7 pages, 3 figures, extended version of the paper presented to
ICMLA'13
View paper on