Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dictionaries for Named Entity Recognition using Minimal Supervision
Apr 24, 2015

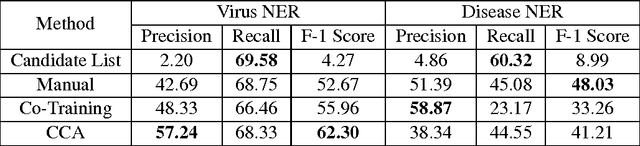
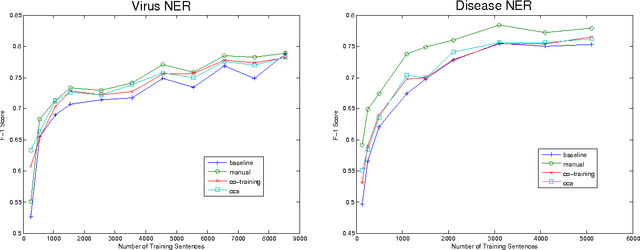
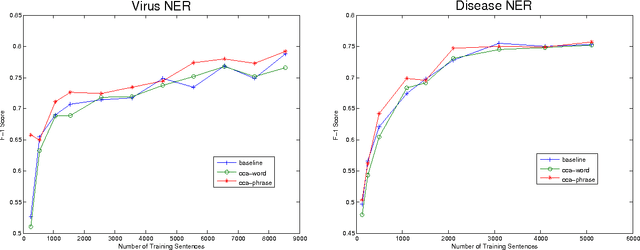
This paper describes an approach for automatic construction of dictionaries for Named Entity Recognition (NER) using large amounts of unlabeled data and a few seed examples. We use Canonical Correlation Analysis (CCA) to obtain lower dimensional embeddings (representations) for candidate phrases and classify these phrases using a small number of labeled examples. Our method achieves 16.5% and 11.3% F-1 score improvement over co-training on disease and virus NER respectively. We also show that by adding candidate phrase embeddings as features in a sequence tagger gives better performance compared to using word embeddings.
* In 14th Conference of the European Chapter of the Association for
Computational Linguistic, 2014
View paper on