 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Scene Analysis with Self-Supervised Multisensory Features
Oct 09, 2018
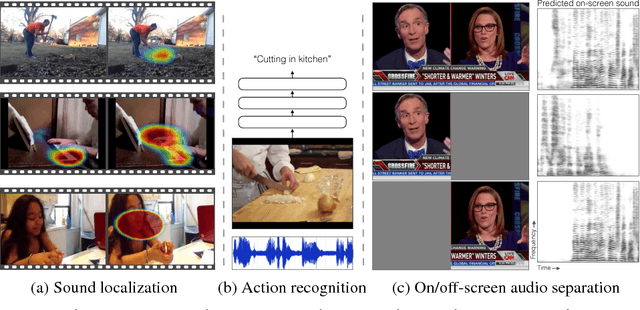

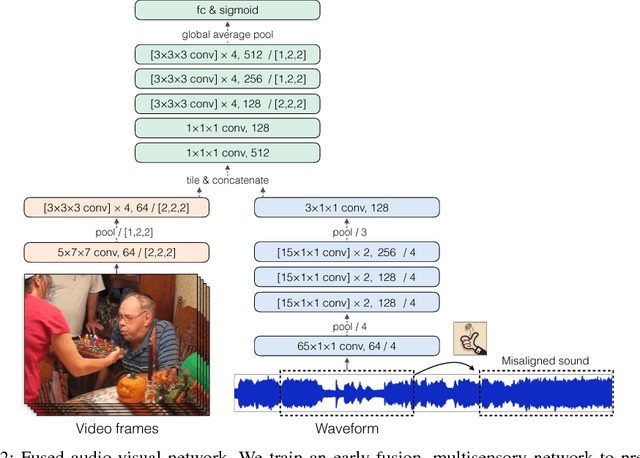
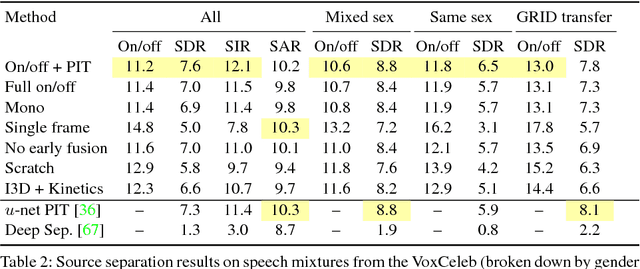
The thud of a bouncing ball, the onset of speech as lips open -- when visual and audio events occur together, it suggests that there might be a common, underlying event that produced both signals. In this paper, we argue that the visual and audio components of a video signal should be modeled jointly using a fused multisensory representation. We propose to learn such a representation in a self-supervised way, by training a neural network to predict whether video frames and audio are temporally aligned. We use this learned representation for three applications: (a) sound source localization, i.e. visualizing the source of sound in a video; (b) audio-visual action recognition; and (c) on/off-screen audio source separation, e.g. removing the off-screen translator's voice from a foreign official's speech. Code, models, and video results are available on our webpage: http://andrewowens.com/multisensory