 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Separation and Synthesis via Generative Adversarial Networks
Nov 07, 2018
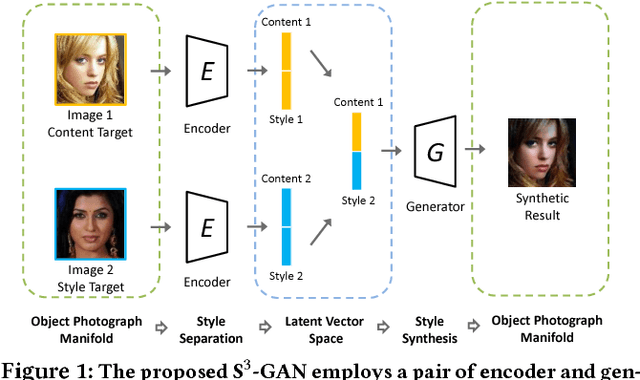
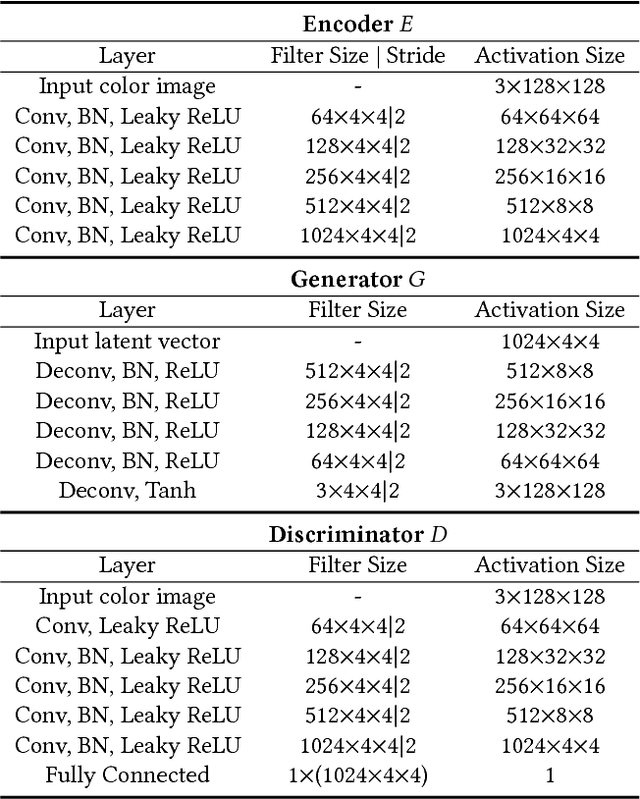
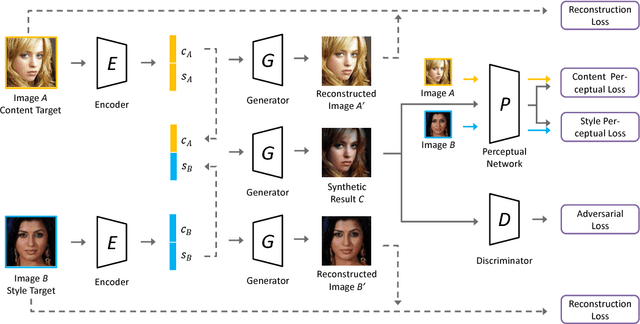
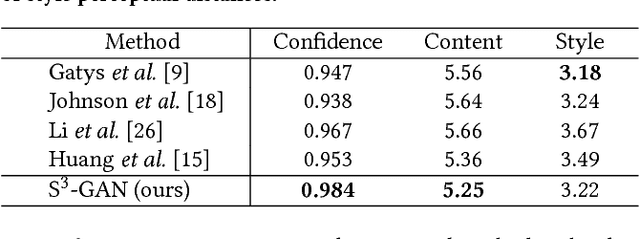
Style synthesis attracts great interests recently, while few works focus on its dual problem "style separation". In this paper, we propose the Style Separation and Synthesis Generative Adversarial Network (S3-GAN) to simultaneously implement style separation and style synthesis on object photographs of specific categories. Based on the assumption that the object photographs lie on a manifold, and the contents and styles are independent, we employ S3-GAN to build mappings between the manifold and a latent vector space for separating and synthesizing the contents and styles. The S3-GAN consists of an encoder network, a generator network, and an adversarial network. The encoder network performs style separation by mapping an object photograph to a latent vector. Two halves of the latent vector represent the content and style, respectively. The generator network performs style synthesis by taking a concatenated vector as input. The concatenated vector contains the style half vector of the style target image and the content half vector of the content target image. Once obtaining the images from the generator network, an adversarial network is imposed to generate more photo-realistic images. Experiments on CelebA and UT Zappos 50K datasets demonstrate that the S3-GAN has the capacity of style separation and synthesis simultaneously, and could capture various styles in a single model.