 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation and Improvement of Chatbot Text Classification Data Quality Using Plausible Negative Examples
Jun 05, 2019
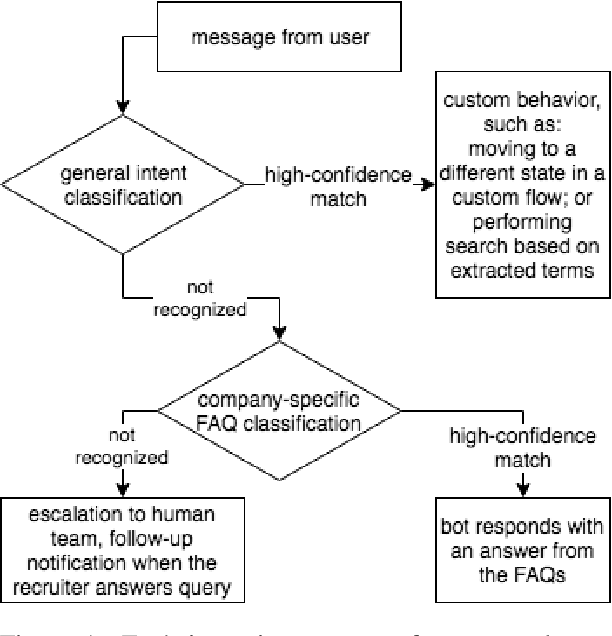
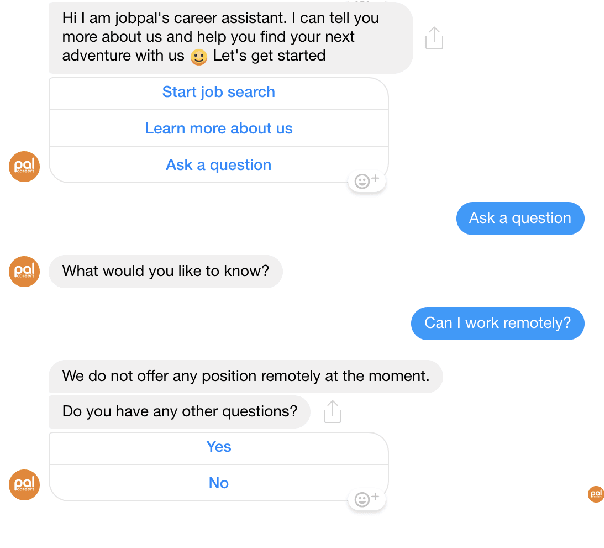
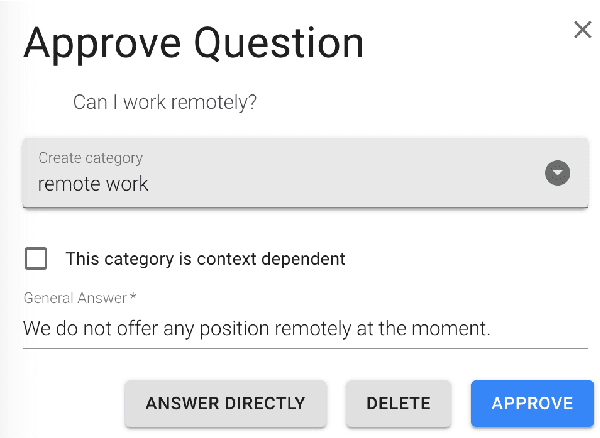
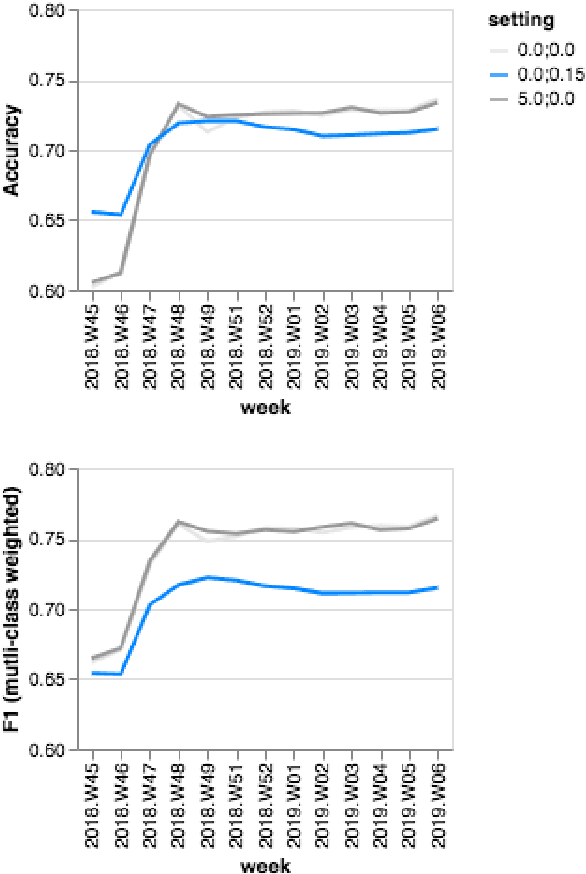
We describe and validate a metric for estimating multi-class classifier performance based on cross-validation and adapted for improvement of small, unbalanced natural-language datasets used in chatbot design. Our experiences draw upon building recruitment chatbots that mediate communication between job-seekers and recruiters by exposing the ML/NLP dataset to the recruiting team. Evaluation approaches must be understandable to various stakeholders, and useful for improving chatbot performance. The metric, nex-cv, uses negative examples in the evaluation of text classification, and fulfils three requirements. First, it is actionable: it can be used by non-developer staff. Second, it is not overly optimistic compared to human ratings, making it a fast method for comparing classifiers. Third, it allows model-agnostic comparison, making it useful for comparing systems despite implementation differences. We validate the metric based on seven recruitment-domain datasets in English and German over the course of one year.