 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn regularization for a convolutional kernel in neural networks
Jun 21, 2019
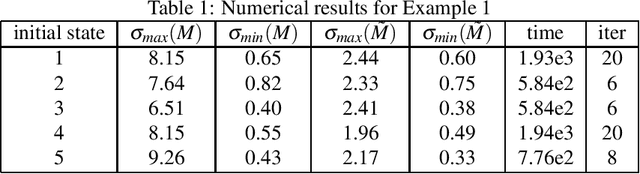
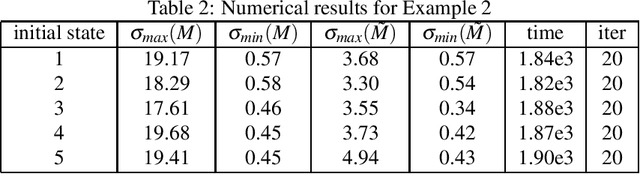
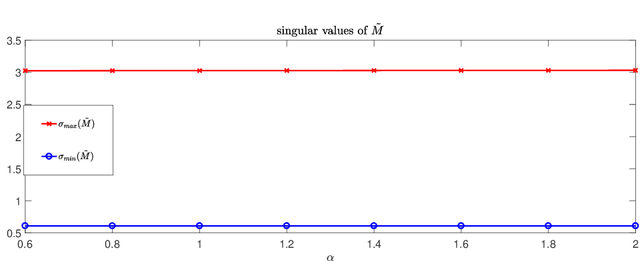
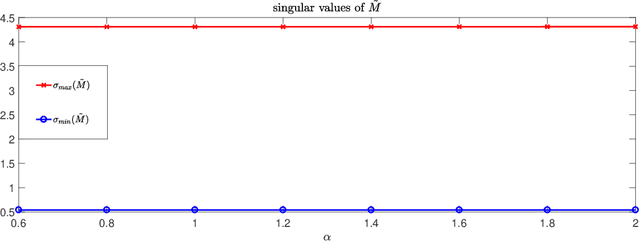
Convolutional neural network is an important model in deep learning. To avoid exploding/vanishing gradient problems and to improve the generalizability of a neural network, it is desirable to have a convolution operation that nearly preserves the norm, or to have the singular values of the transformation matrix corresponding to a convolutional kernel bounded around $1$. We propose a penalty function that can be used in the optimization of a convolutional neural network to constrain the singular values of the transformation matrix around $1$. We derive an algorithm to carry out the gradient descent minimization of this penalty function in terms of convolution kernels. Numerical examples are presented to demonstrate the effectiveness of the method.