 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition with Augmented Synthesized Speech
Sep 25, 2019
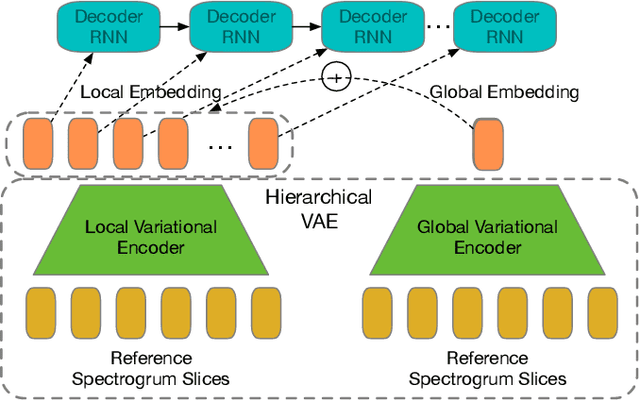
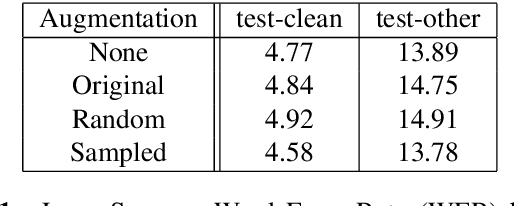
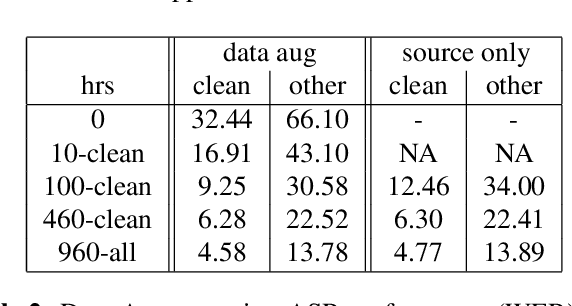
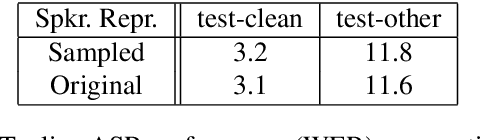
Recent success of the Tacotron speech synthesis architecture and its variants in producing natural sounding multi-speaker synthesized speech has raised the exciting possibility of replacing expensive, manually transcribed, domain-specific, human speech that is used to train speech recognizers. The multi-speaker speech synthesis architecture can learn latent embedding spaces of prosody, speaker and style variations derived from input acoustic representations thereby allowing for manipulation of the synthesized speech. In this paper, we evaluate the feasibility of enhancing speech recognition performance using speech synthesis using two corpora from different domains. We explore algorithms to provide the necessary acoustic and lexical diversity needed for robust speech recognition. Finally, we demonstrate the feasibility of this approach as a data augmentation strategy for domain-transfer. We find that improvements to speech recognition performance is achievable by augmenting training data with synthesized material. However, there remains a substantial gap in performance between recognizers trained on human speech those trained on synthesized speech.