 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDropout: Energy-Based Dropout and Pruning of Deep Neural Networks
Jun 07, 2020
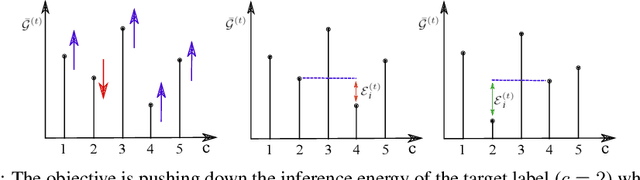
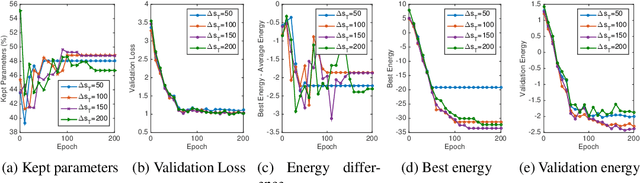
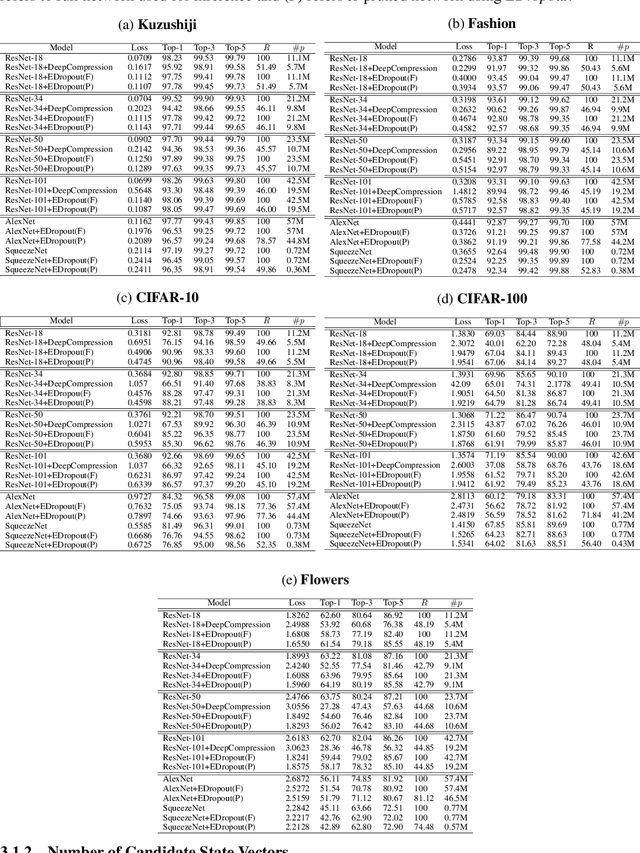
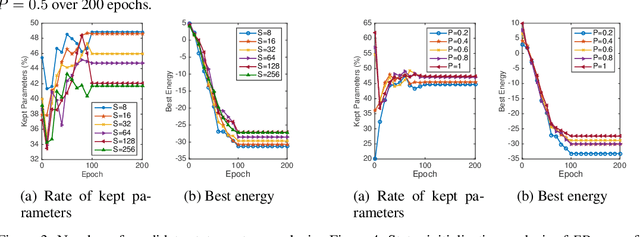
Dropout is well-known as an effective regularization method by sampling a sub-network from a larger deep neural network and training different sub-networks on different subsets of the data. Inspired by the concept of dropout, we stochastically select, train, and evolve a population of sub-networks, where each sub-network is represented by a state vector and a scalar energy. The proposed energy-based dropout (EDropout) method provides a unified framework that can be applied on any arbitrary neural network without the need for proper normalization. The concept of energy in EDropout has the capability of handling diverse number of constraints without any limit on the size or length of the state vectors. The selected set of sub-networks converges during the training to a sub-network that minimizes the energy of the candidate state vectors. The rest of training time is then allocated to fine-tuning the selected sub-network. This process will be equivalent to pruning. We evaluate the proposed method on different flavours of ResNets, AlexNet, and SqueezeNet on the Kuzushiji, Fashion, CIFAR-10, CIFAR-100, and Flowers datasets, and compare with the state-of-the-art pruning and compression methods. We show that on average the networks trained with EDropout achieve a pruning rate of more than 50% of the trainable parameters with approximately <5% and <1% drop of Top-1 and Top-5 classification accuracy, respectively.