 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Inliers Make Great Outliers: Out-of-Distribution Object Detection with Noisy Synthetic Outliers
Aug 29, 2022

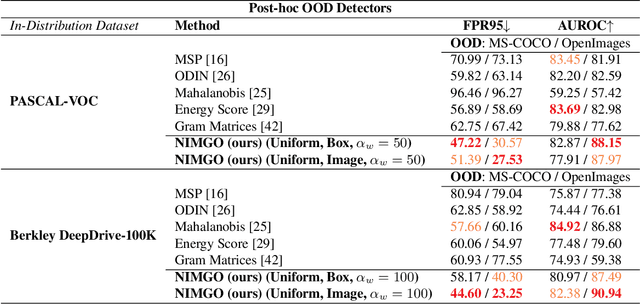

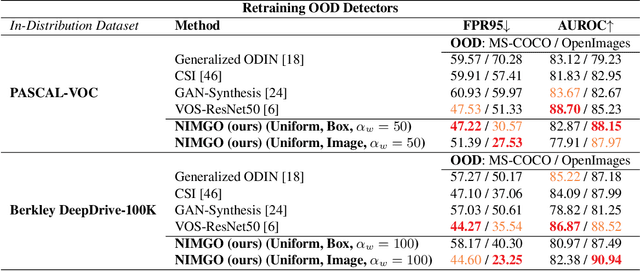
Many high-performing works on out-of-distribution (OOD) detection use real or synthetically generated outlier data to regularise model confidence; however, they often require retraining of the base network or specialised model architectures. Our work demonstrates that Noisy Inliers Make Great Outliers (NIMGO) in the challenging field of OOD object detection. We hypothesise that synthetic outliers need only be minimally perturbed variants of the in-distribution (ID) data in order to train a discriminator to identify OOD samples -- without expensive retraining of the base network. To test our hypothesis, we generate a synthetic outlier set by applying an additive-noise perturbation to ID samples at the image or bounding-box level. An auxiliary feature monitoring multilayer perceptron (MLP) is then trained to detect OOD feature representations using the perturbed ID samples as a proxy. During testing, we demonstrate that the auxiliary MLP distinguishes ID samples from OOD samples at a state-of-the-art level, reducing the false positive rate by more than 20\% (absolute) over the previous state-of-the-art on the OpenImages dataset. Extensive additional ablations provide empirical evidence in support of our hypothesis.