 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKRLS: Improving End-to-End Response Generation in Task Oriented Dialog with Reinforced Keywords Learning
Dec 20, 2022
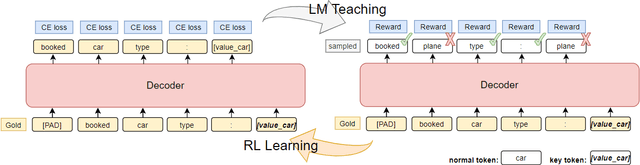
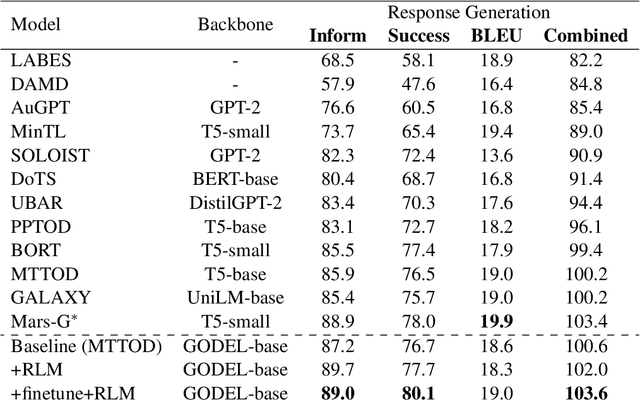
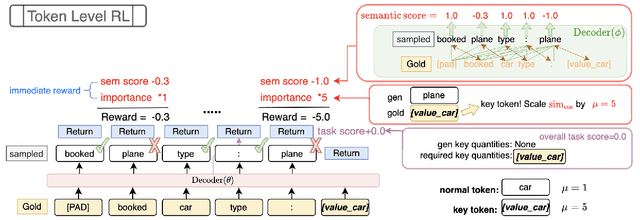

In task-oriented dialogs, an informative and successful system response needs to include key information such as the phone number of a hotel. Therefore, we hypothesize that a model can achieve better overall performance by focusing on correctly generating key quantities. In this paper, we propose a new training algorithm, Keywords Reinforcement Learning with Next-word Sampling (KRLS), that utilizes Reinforcement Learning but avoids the time-consuming auto-regressive generation, and a fine-grained per-token reward function to help the model learn keywords generation more robustly. Empirical results show that the KRLS algorithm can achieve state-of-the-art performance on the inform, success, and combined score on the MultiWoZ benchmark dataset.