 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Consistent Video Editing with Text-to-Image Diffusion Models
May 27, 2023

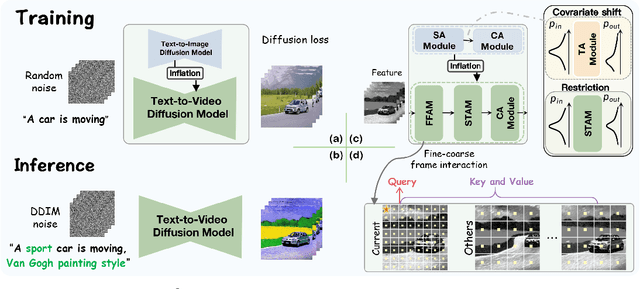


Existing works have advanced Text-to-Image (TTI) diffusion models for video editing in a one-shot learning manner. Despite their low requirements of data and computation, these methods might produce results of unsatisfied consistency with text prompt as well as temporal sequence, limiting their applications in the real world. In this paper, we propose to address the above issues with a novel EI$^2$ model towards \textbf{E}nhancing v\textbf{I}deo \textbf{E}diting cons\textbf{I}stency of TTI-based frameworks. Specifically, we analyze and find that the inconsistent problem is caused by newly added modules into TTI models for learning temporal information. These modules lead to covariate shift in the feature space, which harms the editing capability. Thus, we design EI$^2$ to tackle the above drawbacks with two classical modules: Shift-restricted Temporal Attention Module (STAM) and Fine-coarse Frame Attention Module (FFAM). First, through theoretical analysis, we demonstrate that covariate shift is highly related to Layer Normalization, thus STAM employs a \textit{Instance Centering} layer replacing it to preserve the distribution of temporal features. In addition, {STAM} employs an attention layer with normalized mapping to transform temporal features while constraining the variance shift. As the second part, we incorporate {STAM} with a novel {FFAM}, which efficiently leverages fine-coarse spatial information of overall frames to further enhance temporal consistency. Extensive experiments demonstrate the superiority of the proposed EI$^2$ model for text-driven video editing.