 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Fine-Grained N:M sparsity for Activations and Neural Gradients
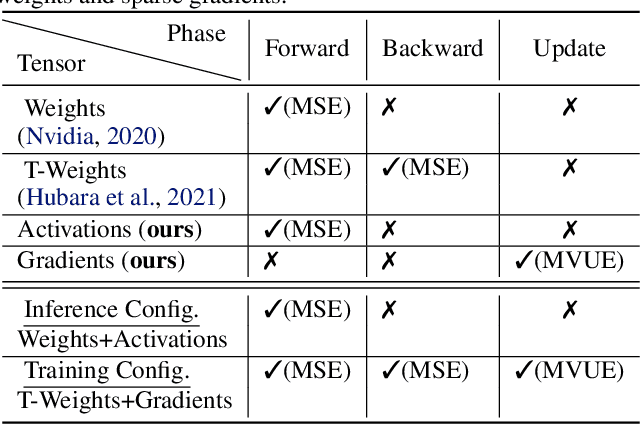

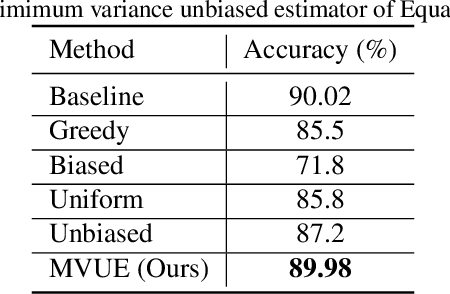
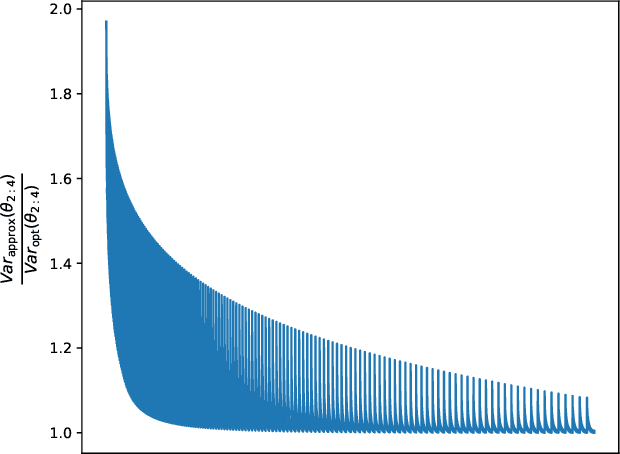
In deep learning, fine-grained N:M sparsity reduces the data footprint and bandwidth of a General Matrix multiply (GEMM) by x2, and doubles throughput by skipping computation of zero values. So far, it was only used to prune weights. We examine how this method can be used also for activations and their gradients (i.e., "neural gradients"). To this end, we first establish tensor-level optimality criteria. Previous works aimed to minimize the mean-square-error (MSE) of each pruned block. We show that while minimization of the MSE works fine for pruning the activations, it catastrophically fails for the neural gradients. Instead, we show that optimal pruning of the neural gradients requires an unbiased minimum-variance pruning mask. We design such specialized masks, and find that in most cases, 1:2 sparsity is sufficient for training, and 2:4 sparsity is usually enough when this is not the case. Further, we suggest combining several such methods together in order to speed up training even more. A reference implementation is supplied in https://github.com/brianchmiel/Act-and-Grad-structured-sparsity.