 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePs and Qs: Quantization-aware pruning for efficient low latency neural network inference
Feb 22, 2021

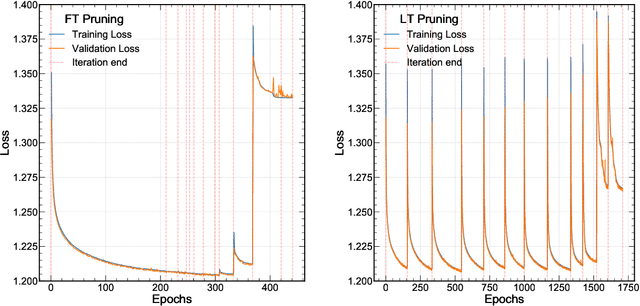
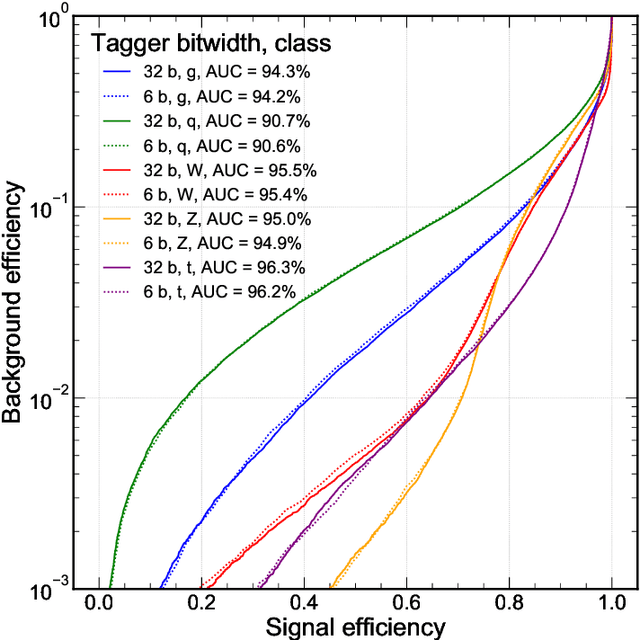
Efficient machine learning implementations optimized for inference in hardware have wide-ranging benefits depending on the application from lower inference latencies to higher data throughputs to more efficient energy consumption. Two popular techniques for reducing computation in neural networks are pruning, removing insignificant synapses, and quantization, reducing the precision of the calculations. In this work, we explore the interplay between pruning and quantization during the training of neural networks for ultra low latency applications targeting high energy physics use cases. However, techniques developed for this study have potential application across many other domains. We study various configurations of pruning during quantization-aware training, which we term \emph{quantization-aware pruning} and the effect of techniques like regularization, batch normalization, and different pruning schemes on multiple computational or neural efficiency metrics. We find that quantization-aware pruning yields more computationally efficient models than either pruning or quantization alone for our task. Further, quantization-aware pruning typically performs similar to or better in terms of computational efficiency compared to standard neural architecture optimization techniques. While the accuracy for the benchmark application may be similar, the information content of the network can vary significantly based on the training configuration.