 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Balakrishnan": models, code, and papers
Rejoinder: On nearly assumption-free tests of nominal confidence interval coverage for causal parameters estimated by machine learning
Aug 07, 2020
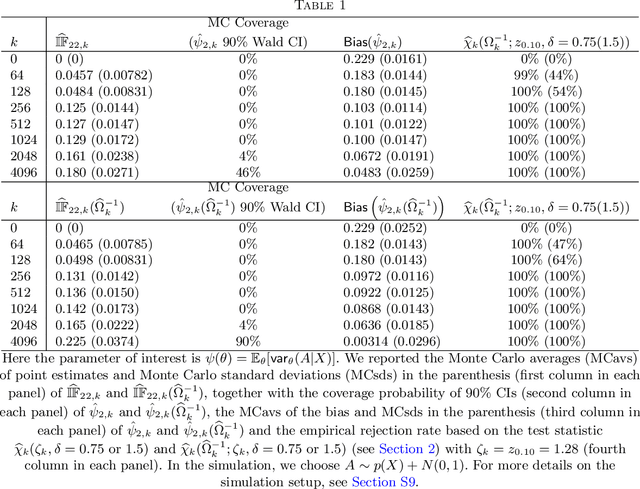
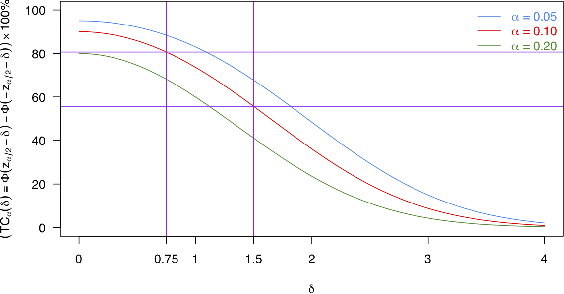
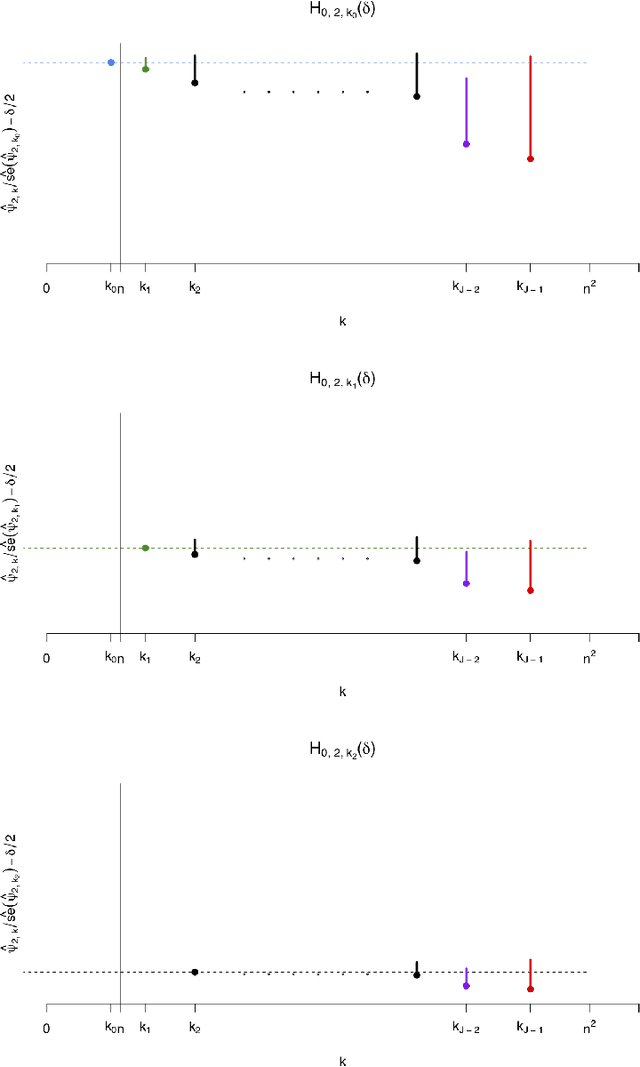
This is the rejoinder to the discussion by Kennedy, Balakrishnan and Wasserman on the paper "On nearly assumption-free tests of nominal confidence interval coverage for causal parameters estimated by machine learning" published in Statistical Science.
Stochastic Adversarial Koopman Model for Dynamical Systems
Sep 10, 2021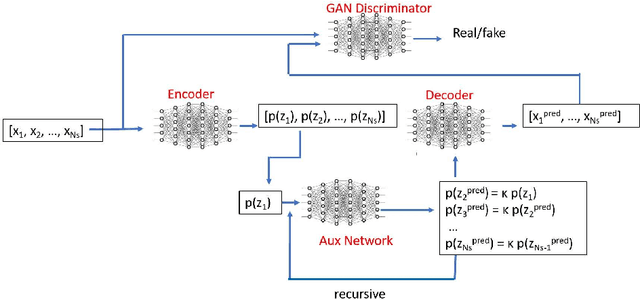
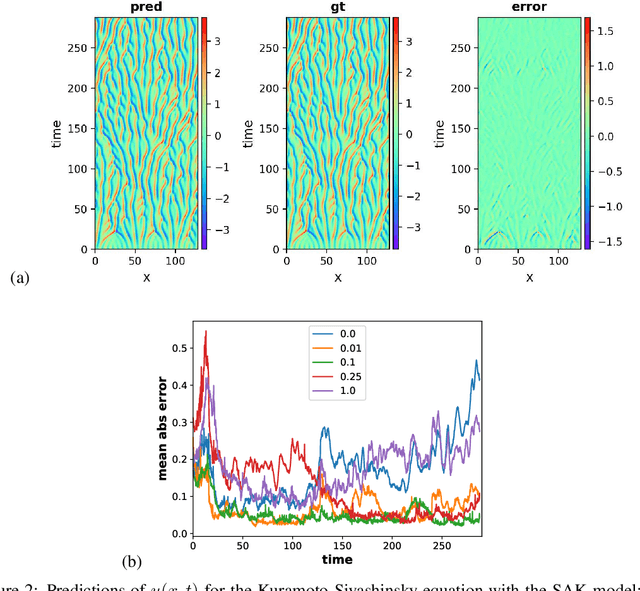
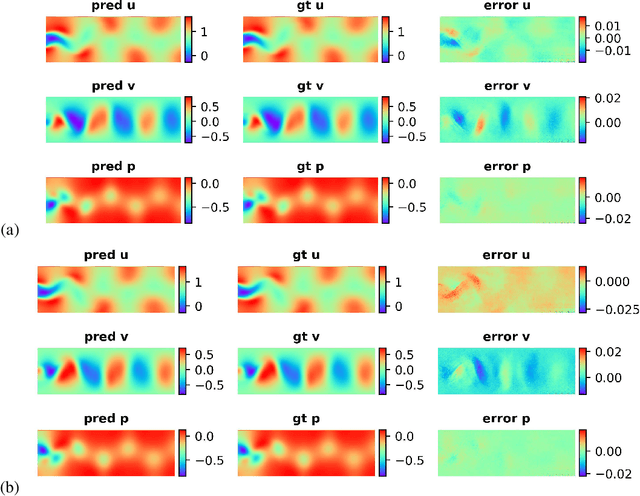
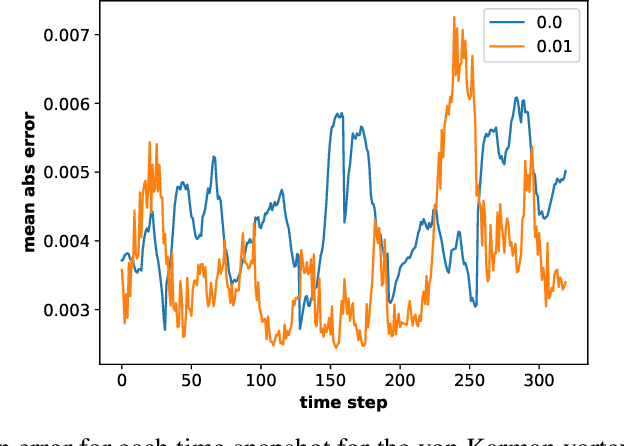
Dynamical systems are ubiquitous and are often modeled using a non-linear system of governing equations. Numerical solution procedures for many dynamical systems have existed for several decades, but can be slow due to high-dimensional state space of the dynamical system. Thus, deep learning-based reduced order models (ROMs) are of interest and one such family of algorithms along these lines are based on the Koopman theory. This paper extends a recently developed adversarial Koopman model (Balakrishnan \& Upadhyay, arXiv:2006.05547) to stochastic space, where the Koopman operator applies on the probability distribution of the latent encoding of an encoder. Specifically, the latent encoding of the system is modeled as a Gaussian, and is advanced in time by using an auxiliary neural network that outputs two Koopman matrices $K_{\mu}$ and $K_{\sigma}$. Adversarial and gradient losses are used and this is found to lower the prediction errors. A reduced Koopman formulation is also undertaken where the Koopman matrices are assumed to have a tridiagonal structure, and this yields predictions comparable to the baseline model with full Koopman matrices. The efficacy of the stochastic Koopman model is demonstrated on different test problems in chaos, fluid dynamics, combustion, and reaction-diffusion models. The proposed model is also applied in a setting where the Koopman matrices are conditioned on other input parameters for generalization and this is applied to simulate the state of a Lithium-ion battery in time. The Koopman models discussed in this study are very promising for the wide range of problems considered.
A Functional EM Algorithm for Panel Count Data with Missing Counts
Mar 28, 2020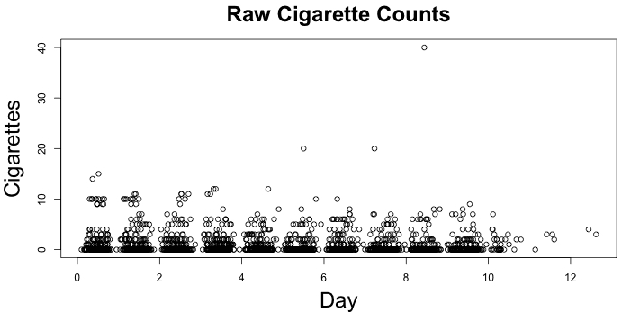
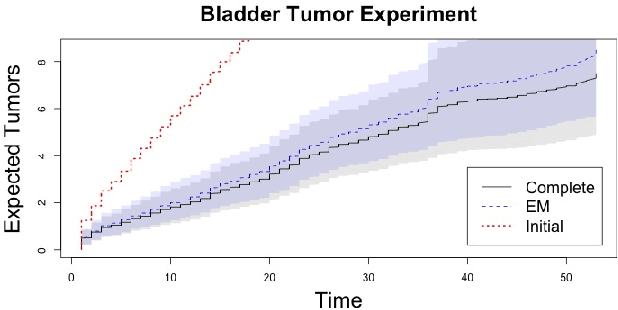
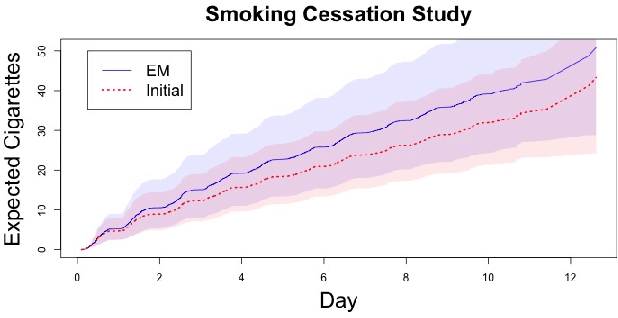
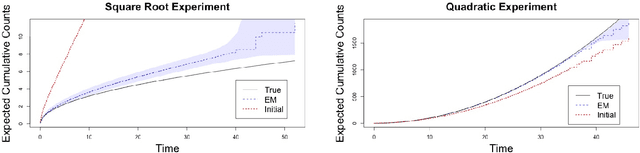
Panel count data is recurrent events data where counts of events are observed at discrete time points. Panel counts naturally describe self-reported behavioral data, and the occurrence of missing or unreliable reports is common. Unfortunately, no prior work has tackled the problem of missingness in this setting. We address this gap in the literature by developing a novel functional EM algorithm that can be used as a wrapper around several popular panel count mean function inference methods when some counts are missing. We provide a novel theoretical analysis of our method showing strong consistency. Extending the methods in (Balakrishnan et al., 2017, Wu et al. 2016), we show that the functional EM algorithm recovers the true mean function of the counting process. We accomplish this by developing alternative regularity conditions for our objective function in order to show convergence of the population EM algorithm. We prove strong consistency of the M-step, thus giving strong consistency guarantees for the finite sample EM algorithm. We present experimental results for synthetic data, synthetic missingness on real data, and a smoking cessation study, where we find that participants may underestimate cigarettes smoked by approximately 18.6% over a 12 day period.
Randomly initialized EM algorithm for two-component Gaussian mixture achieves near optimality in $O(\sqrt{n})$ iterations
Aug 28, 2019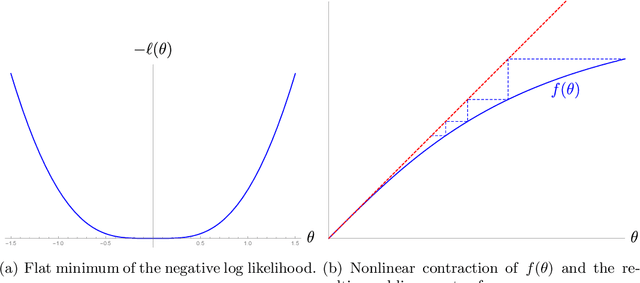
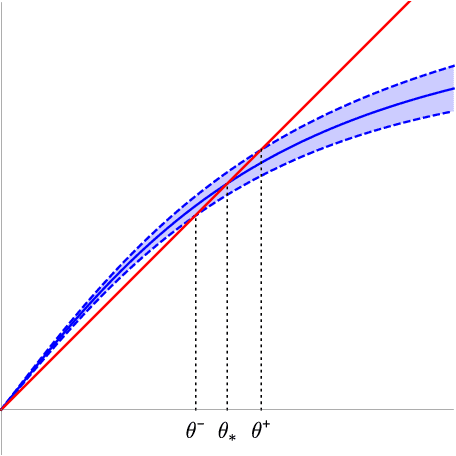
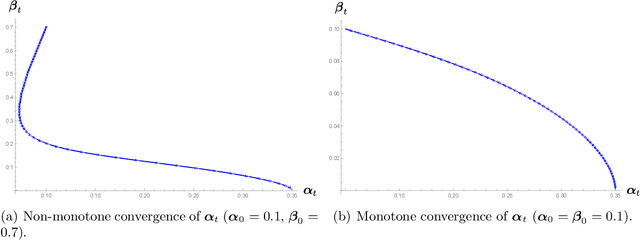
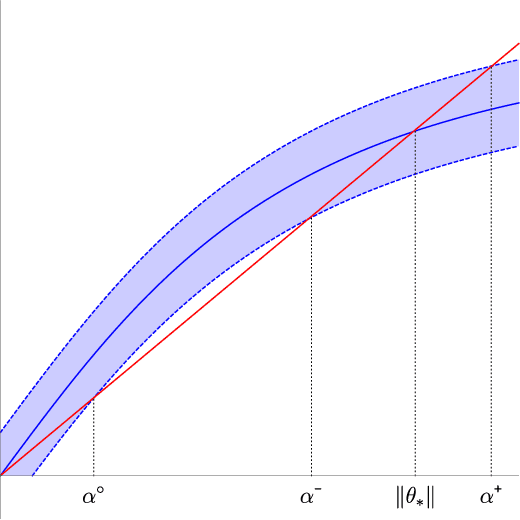
We analyze the classical EM algorithm for parameter estimation in the symmetric two-component Gaussian mixtures in $d$ dimensions. We show that, even in the absence of any separation between components, provided that the sample size satisfies $n=\Omega(d \log^3 d)$, the randomly initialized EM algorithm converges to an estimate in at most $O(\sqrt{n})$ iterations with high probability, which is at most $O((\frac{d \log^3 n}{n})^{1/4})$ in Euclidean distance from the true parameter and within logarithmic factors of the minimax rate of $(\frac{d}{n})^{1/4}$. Both the nonparametric statistical rate and the sublinear convergence rate are direct consequences of the zero Fisher information in the worst case. Refined pointwise guarantees beyond worst-case analysis and convergence to the MLE are also shown under mild conditions. This improves the previous result of Balakrishnan et al \cite{BWY17} which requires strong conditions on both the separation of the components and the quality of the initialization, and that of Daskalakis et al \cite{DTZ17} which requires sample splitting and restarting the EM iteration.
Statistical Guarantees for Estimating the Centers of a Two-component Gaussian Mixture by EM
Aug 07, 2016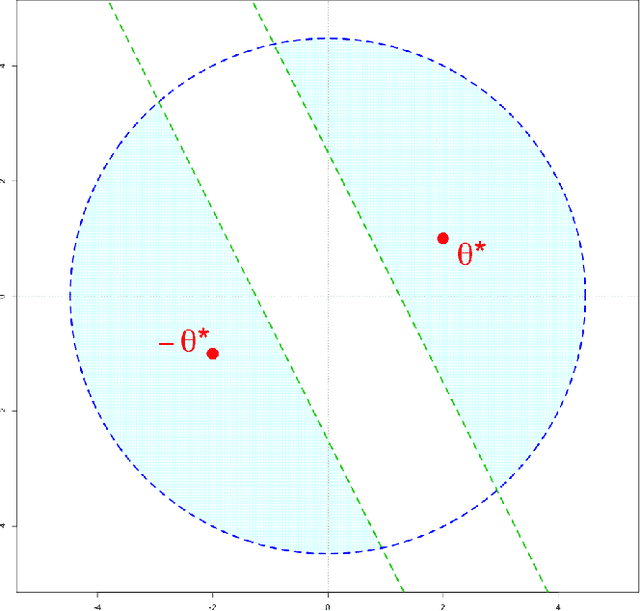
Recently, a general method for analyzing the statistical accuracy of the EM algorithm has been developed and applied to some simple latent variable models [Balakrishnan et al. 2016]. In that method, the basin of attraction for valid initialization is required to be a ball around the truth. Using Stein's Lemma, we extend these results in the case of estimating the centers of a two-component Gaussian mixture in $d$ dimensions. In particular, we significantly expand the basin of attraction to be the intersection of a half space and a ball around the origin. If the signal-to-noise ratio is at least a constant multiple of $ \sqrt{d\log d} $, we show that a random initialization strategy is feasible.
Average-Case Lower Bounds for Learning Sparse Mixtures, Robust Estimation and Semirandom Adversaries
Aug 08, 2019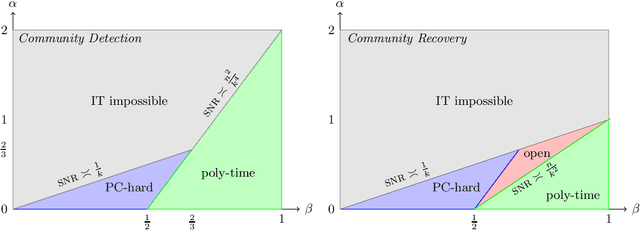



This paper develops several average-case reduction techniques to show new hardness results for three central high-dimensional statistics problems, implying a statistical-computational gap induced by robustness, a detection-recovery gap and a universality principle for these gaps. A main feature of our approach is to map to these problems via a common intermediate problem that we introduce, which we call Imbalanced Sparse Gaussian Mixtures. We assume the planted clique conjecture for a version of the planted clique problem where the position of the planted clique is mildly constrained, and from this obtain the following computational lower bounds: (1) a $k$-to-$k^2$ statistical-computational gap for robust sparse mean estimation, providing the first average-case evidence for a conjecture of Li (2017) and Balakrishnan et al. (2017); (2) a tight lower bound for semirandom planted dense subgraph, which shows that a semirandom adversary shifts the detection threshold in planted dense subgraph to the conjectured recovery threshold; and (3) a universality principle for $k$-to-$k^2$ gaps in a broad class of sparse mixture problems that includes many natural formulations such as the spiked covariance model. Our main approach is to introduce several average-case techniques to produce structured and Gaussianized versions of an input graph problem, and then to rotate these high-dimensional Gaussians by matrices carefully constructed from hyperplanes in $\mathbb{F}_r^t$. For our universality result, we introduce a new method to perform an algorithmic change of measure tailored to sparse mixtures. We also provide evidence that the mild promise in our variant of planted clique does not change the complexity of the problem.
Regularized EM Algorithms: A Unified Framework and Statistical Guarantees
Dec 05, 2015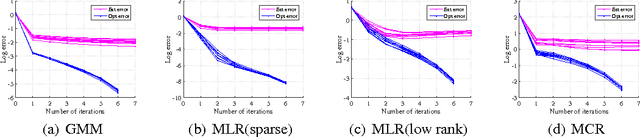
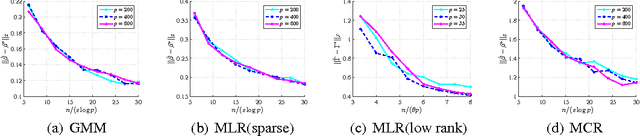
Latent variable models are a fundamental modeling tool in machine learning applications, but they present significant computational and analytical challenges. The popular EM algorithm and its variants, is a much used algorithmic tool; yet our rigorous understanding of its performance is highly incomplete. Recently, work in Balakrishnan et al. (2014) has demonstrated that for an important class of problems, EM exhibits linear local convergence. In the high-dimensional setting, however, the M-step may not be well defined. We address precisely this setting through a unified treatment using regularization. While regularization for high-dimensional problems is by now well understood, the iterative EM algorithm requires a careful balancing of making progress towards the solution while identifying the right structure (e.g., sparsity or low-rank). In particular, regularizing the M-step using the state-of-the-art high-dimensional prescriptions (e.g., Wainwright (2014)) is not guaranteed to provide this balance. Our algorithm and analysis are linked in a way that reveals the balance between optimization and statistical errors. We specialize our general framework to sparse gaussian mixture models, high-dimensional mixed regression, and regression with missing variables, obtaining statistical guarantees for each of these examples.