 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Matt": models, code, and papers
A Multispectral Automated Transfer Technique (MATT) for machine-driven image labeling utilizing the Segment Anything Model (SAM)
Feb 18, 2024
Segment Anything Model (SAM) is drastically accelerating the speed and accuracy of automatically segmenting and labeling large Red-Green-Blue (RGB) imagery datasets. However, SAM is unable to segment and label images outside of the visible light spectrum, for example, for multispectral or hyperspectral imagery. Therefore, this paper outlines a method we call the Multispectral Automated Transfer Technique (MATT). By transposing SAM segmentation masks from RGB images we can automatically segment and label multispectral imagery with high precision and efficiency. For example, the results demonstrate that segmenting and labeling a 2,400-image dataset utilizing MATT achieves a time reduction of 87.8% in developing a trained model, reducing roughly 20 hours of manual labeling, to only 2.4 hours. This efficiency gain is associated with only a 6.7% decrease in overall mean average precision (mAP) when training multispectral models via MATT, compared to a manually labeled dataset. We consider this an acceptable level of precision loss when considering the time saved during training, especially for rapidly prototyping experimental modeling methods. This research greatly contributes to the study of multispectral object detection by providing a novel and open-source method to rapidly segment, label, and train multispectral object detection models with minimal human interaction. Future research needs to focus on applying these methods to (i) space-based multispectral, and (ii) drone-based hyperspectral imagery.
Domain-Rectifying Adapter for Cross-Domain Few-Shot Segmentation
Apr 16, 2024Few-shot semantic segmentation (FSS) has achieved great success on segmenting objects of novel classes, supported by only a few annotated samples. However, existing FSS methods often underperform in the presence of domain shifts, especially when encountering new domain styles that are unseen during training. It is suboptimal to directly adapt or generalize the entire model to new domains in the few-shot scenario. Instead, our key idea is to adapt a small adapter for rectifying diverse target domain styles to the source domain. Consequently, the rectified target domain features can fittingly benefit from the well-optimized source domain segmentation model, which is intently trained on sufficient source domain data. Training domain-rectifying adapter requires sufficiently diverse target domains. We thus propose a novel local-global style perturbation method to simulate diverse potential target domains by perturbating the feature channel statistics of the individual images and collective statistics of the entire source domain, respectively. Additionally, we propose a cyclic domain alignment module to facilitate the adapter effectively rectifying domains using a reverse domain rectification supervision. The adapter is trained to rectify the image features from diverse synthesized target domains to align with the source domain. During testing on target domains, we start by rectifying the image features and then conduct few-shot segmentation on the domain-rectified features. Extensive experiments demonstrate the effectiveness of our method, achieving promising results on cross-domain few-shot semantic segmentation tasks. Our code is available at https://github.com/Matt-Su/DR-Adapter.
G-MATT: Single-step Retrosynthesis Prediction using Molecular Grammar Tree Transformer
May 04, 2023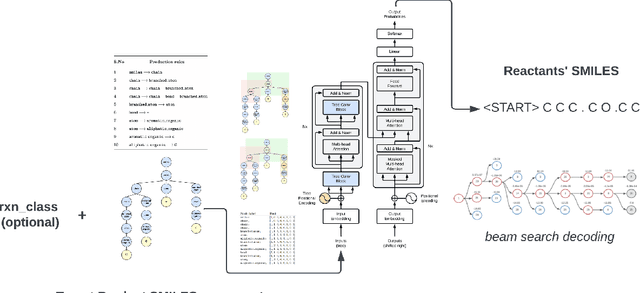
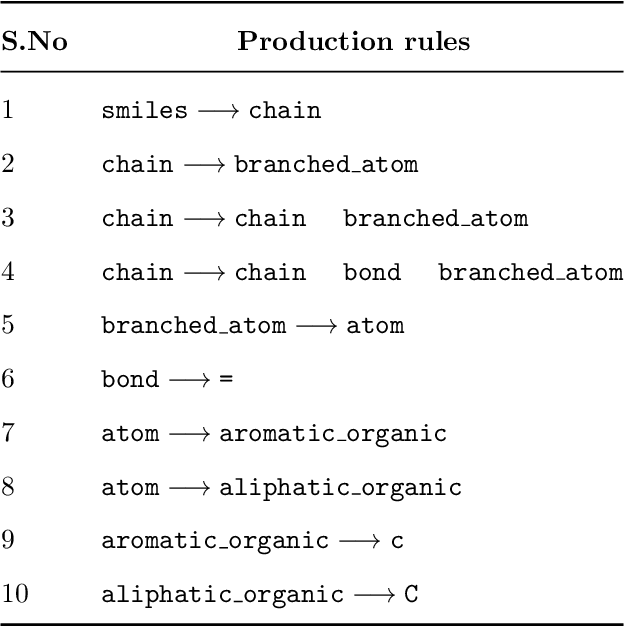
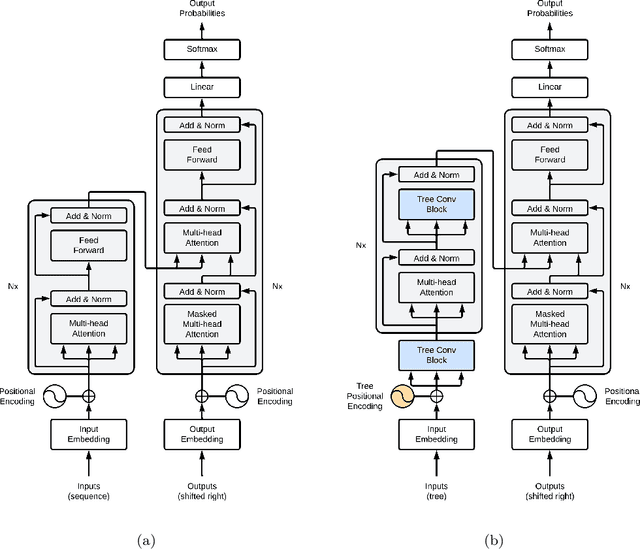

In recent years, several reaction templates-based and template-free approaches have been reported for single-step retrosynthesis prediction. Even though many of these approaches perform well from traditional data-driven metrics standpoint, there is a disconnect between model architectures used and underlying chemistry principles governing retrosynthesis. Here, we propose a novel chemistry-aware retrosynthesis prediction framework that combines powerful data-driven models with chemistry knowledge. We report a tree-to-sequence transformer architecture based on hierarchical SMILES grammar trees as input containing underlying chemistry information that is otherwise ignored by models based on purely SMILES-based representations. The proposed framework, grammar-based molecular attention tree transformer (G-MATT), achieves significant performance improvements compared to baseline retrosynthesis models. G-MATT achieves a top-1 accuracy of 51% (top-10 accuracy of 79.1%), invalid rate of 1.5%, and bioactive similarity rate of 74.8%. Further analyses based on attention maps demonstrate G-MATT's ability to preserve chemistry knowledge without having to use extremely complex model architectures.
MAtt: A Manifold Attention Network for EEG Decoding
Oct 05, 2022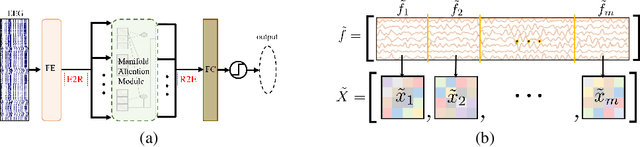
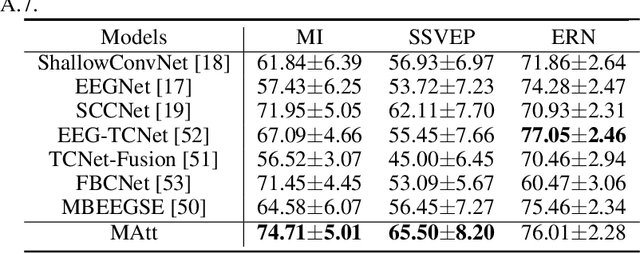
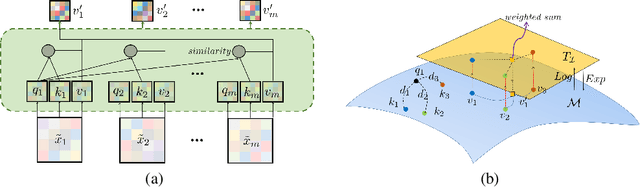
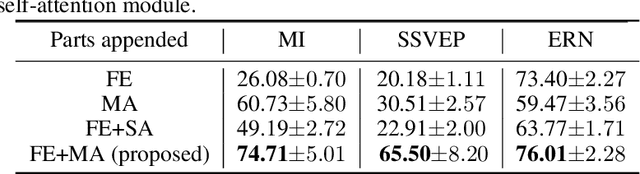
Recognition of electroencephalographic (EEG) signals highly affect the efficiency of non-invasive brain-computer interfaces (BCIs). While recent advances of deep-learning (DL)-based EEG decoders offer improved performances, the development of geometric learning (GL) has attracted much attention for offering exceptional robustness in decoding noisy EEG data. However, there is a lack of studies on the merged use of deep neural networks (DNNs) and geometric learning for EEG decoding. We herein propose a manifold attention network (mAtt), a novel geometric deep learning (GDL)-based model, featuring a manifold attention mechanism that characterizes spatiotemporal representations of EEG data fully on a Riemannian symmetric positive definite (SPD) manifold. The evaluation of the proposed MAtt on both time-synchronous and -asyncronous EEG datasets suggests its superiority over other leading DL methods for general EEG decoding. Furthermore, analysis of model interpretation reveals the capability of MAtt in capturing informative EEG features and handling the non-stationarity of brain dynamics.
MATT: A Multiple-instance Attention Mechanism for Long-tail Music Genre Classification
Sep 09, 2022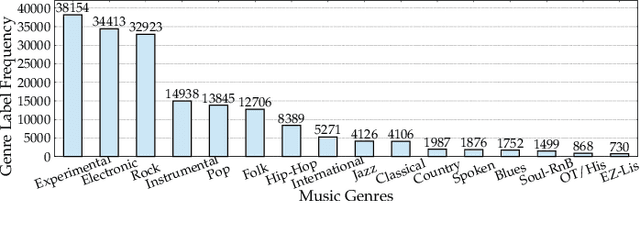
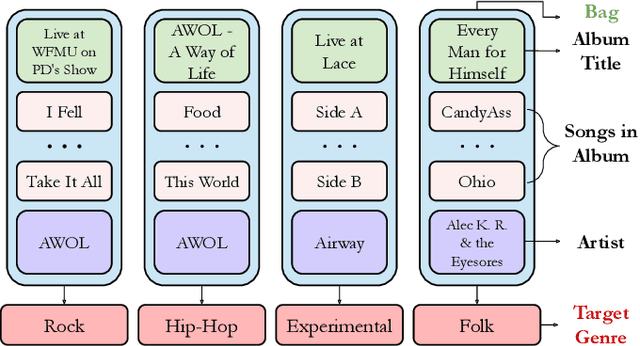
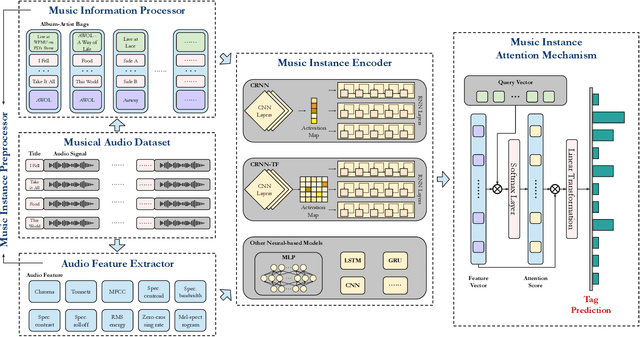
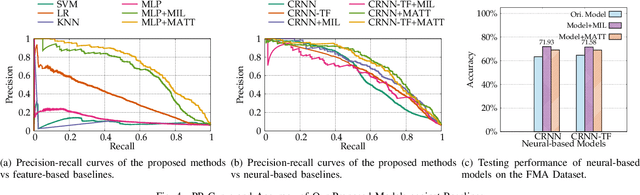
Imbalanced music genre classification is a crucial task in the Music Information Retrieval (MIR) field for identifying the long-tail, data-poor genre based on the related music audio segments, which is very prevalent in real-world scenarios. Most of the existing models are designed for class-balanced music datasets, resulting in poor performance in accuracy and generalization when identifying the music genres at the tail of the distribution. Inspired by the success of introducing Multi-instance Learning (MIL) in various classification tasks, we propose a novel mechanism named Multi-instance Attention (MATT) to boost the performance for identifying tail classes. Specifically, we first construct the bag-level datasets by generating the album-artist pair bags. Second, we leverage neural networks to encode the music audio segments. Finally, under the guidance of a multi-instance attention mechanism, the neural network-based models could select the most informative genre to match the given music segment. Comprehensive experimental results on a large-scale music genre benchmark dataset with long-tail distribution demonstrate MATT significantly outperforms other state-of-the-art baselines.
Many tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .
MATT: Multimodal Attention Level Estimation for e-learning Platforms
Jan 22, 2023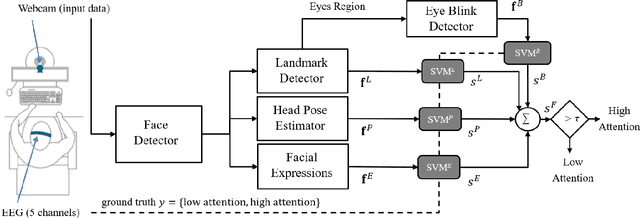
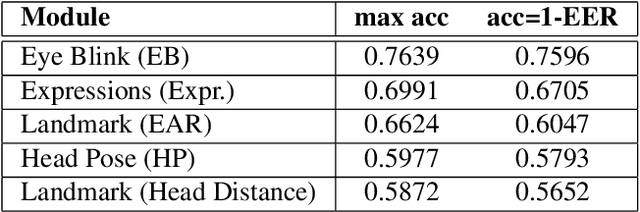
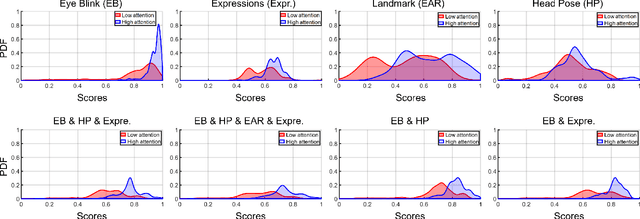
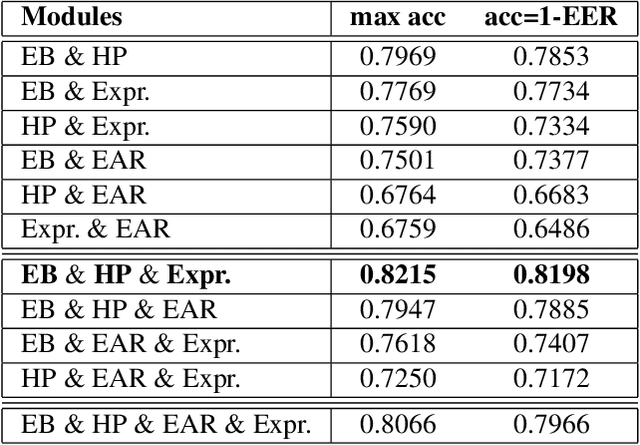
This work presents a new multimodal system for remote attention level estimation based on multimodal face analysis. Our multimodal approach uses different parameters and signals obtained from the behavior and physiological processes that have been related to modeling cognitive load such as faces gestures (e.g., blink rate, facial actions units) and user actions (e.g., head pose, distance to the camera). The multimodal system uses the following modules based on Convolutional Neural Networks (CNNs): Eye blink detection, head pose estimation, facial landmark detection, and facial expression features. First, we individually evaluate the proposed modules in the task of estimating the student's attention level captured during online e-learning sessions. For that we trained binary classifiers (high or low attention) based on Support Vector Machines (SVM) for each module. Secondly, we find out to what extent multimodal score level fusion improves the attention level estimation. The mEBAL database is used in the experimental framework, a public multi-modal database for attention level estimation obtained in an e-learning environment that contains data from 38 users while conducting several e-learning tasks of variable difficulty (creating changes in student cognitive loads).
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
Aug 29, 2019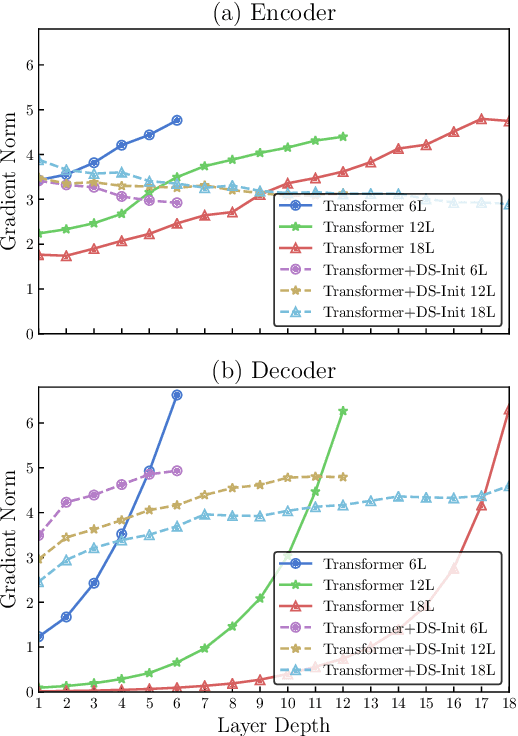
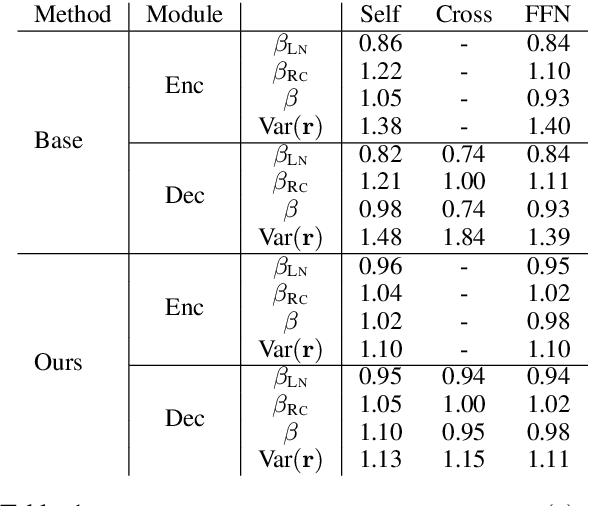
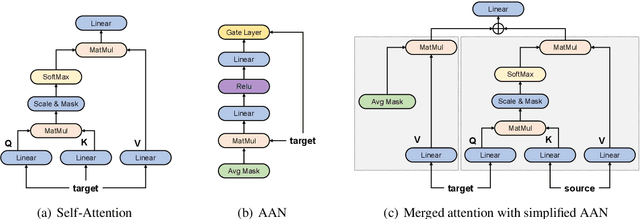
The general trend in NLP is towards increasing model capacity and performance via deeper neural networks. However, simply stacking more layers of the popular Transformer architecture for machine translation results in poor convergence and high computational overhead. Our empirical analysis suggests that convergence is poor due to gradient vanishing caused by the interaction between residual connections and layer normalization. We propose depth-scaled initialization (DS-Init), which decreases parameter variance at the initialization stage, and reduces output variance of residual connections so as to ease gradient back-propagation through normalization layers. To address computational cost, we propose a merged attention sublayer (MAtt) which combines a simplified averagebased self-attention sublayer and the encoderdecoder attention sublayer on the decoder side. Results on WMT and IWSLT translation tasks with five translation directions show that deep Transformers with DS-Init and MAtt can substantially outperform their base counterpart in terms of BLEU (+1.1 BLEU on average for 12-layer models), while matching the decoding speed of the baseline model thanks to the efficiency improvements of MAtt.
Tiny Neural Models for Seq2Seq
Aug 07, 2021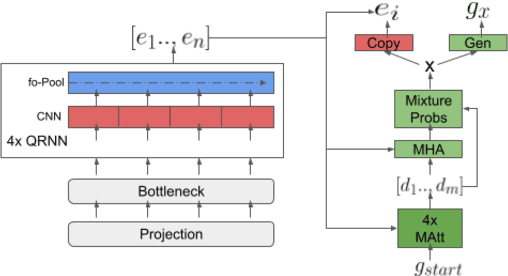
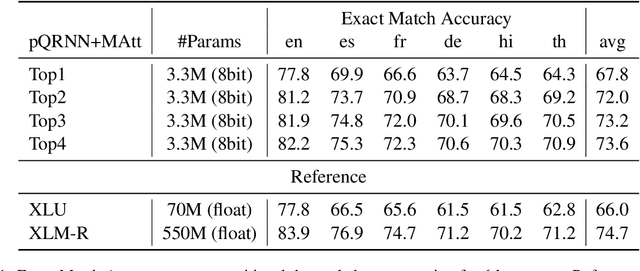
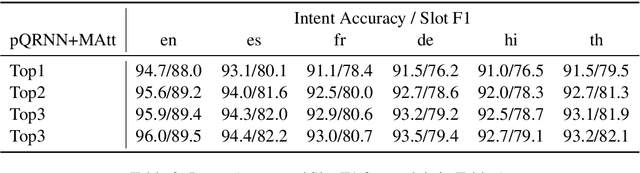
Semantic parsing models with applications in task oriented dialog systems require efficient sequence to sequence (seq2seq) architectures to be run on-device. To this end, we propose a projection based encoder-decoder model referred to as pQRNN-MAtt. Studies based on projection methods were restricted to encoder-only models, and we believe this is the first study extending it to seq2seq architectures. The resulting quantized models are less than 3.5MB in size and are well suited for on-device latency critical applications. We show that on MTOP, a challenging multilingual semantic parsing dataset, the average model performance surpasses LSTM based seq2seq model that uses pre-trained embeddings despite being 85x smaller. Furthermore, the model can be an effective student for distilling large pre-trained models such as T5/BERT.
Rolling-Unrolling LSTMs for Action Anticipation from First-Person Video
May 08, 2020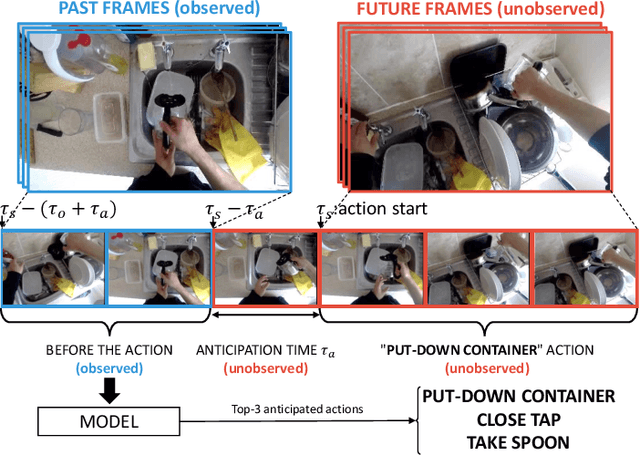
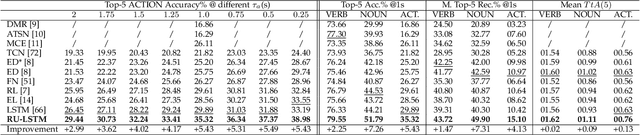
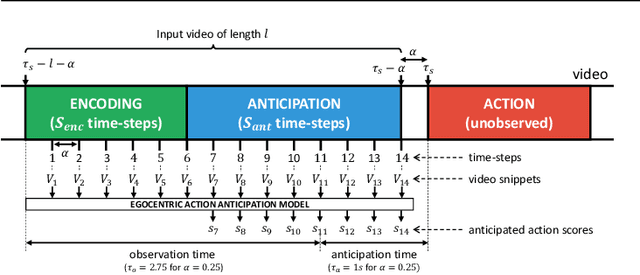
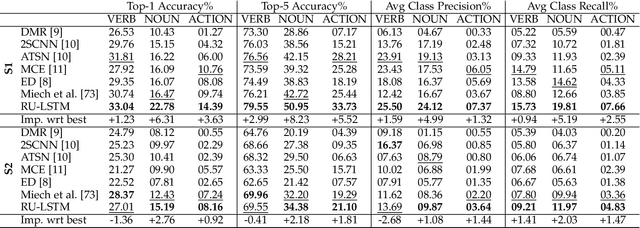
In this paper, we tackle the problem of egocentric action anticipation, i.e., predicting what actions the camera wearer will perform in the near future and which objects they will interact with. Specifically, we contribute Rolling-Unrolling LSTM, a learning architecture to anticipate actions from egocentric videos. The method is based on three components: 1) an architecture comprised of two LSTMs to model the sub-tasks of summarizing the past and inferring the future, 2) a Sequence Completion Pre-Training technique which encourages the LSTMs to focus on the different sub-tasks, and 3) a Modality ATTention (MATT) mechanism to efficiently fuse multi-modal predictions performed by processing RGB frames, optical flow fields and object-based features. The proposed approach is validated on EPIC-Kitchens, EGTEA Gaze+ and ActivityNet. The experiments show that the proposed architecture is state-of-the-art in the domain of egocentric videos, achieving top performances in the 2019 EPIC-Kitchens egocentric action anticipation challenge. The approach also achieves competitive performance on ActivityNet with respect to methods not based on unsupervised pre-training and generalizes to the tasks of early action recognition and action recognition. To encourage research on this challenging topic, we made our code, trained models, and pre-extracted features available at our web page: http://iplab.dmi.unict.it/rulstm.
* arXiv admin note: substantial text overlap with arXiv:1905.09035