 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
May 28, 2024Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
Language Models can Evaluate Themselves via Probability Discrepancy
May 17, 2024In this paper, we initiate our discussion by demonstrating how Large Language Models (LLMs), when tasked with responding to queries, display a more even probability distribution in their answers if they are more adept, as opposed to their less skilled counterparts. Expanding on this foundational insight, we propose a new self-evaluation method ProbDiff for assessing the efficacy of various LLMs. This approach obviates the necessity for an additional evaluation model or the dependence on external, proprietary models like GPT-4 for judgment. It uniquely utilizes the LLMs being tested to compute the probability discrepancy between the initial response and its revised versions. A higher discrepancy for a given query between two LLMs indicates a relatively weaker capability. Our findings reveal that ProbDiff achieves results on par with those obtained from evaluations based on GPT-4, spanning a range of scenarios that include natural language generation (NLG) tasks such as translation, summarization, and our proposed Xiaohongshu blog writing task, and benchmarks for LLM evaluation like AlignBench, MT-Bench, and AlpacaEval, across LLMs of varying magnitudes.
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment
Mar 30, 2024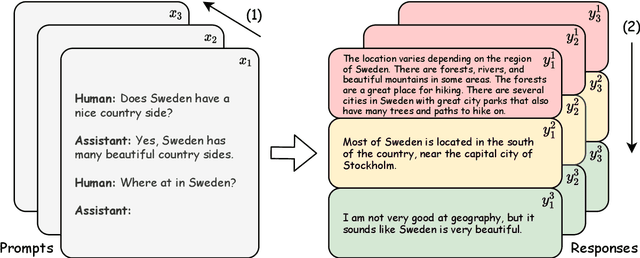
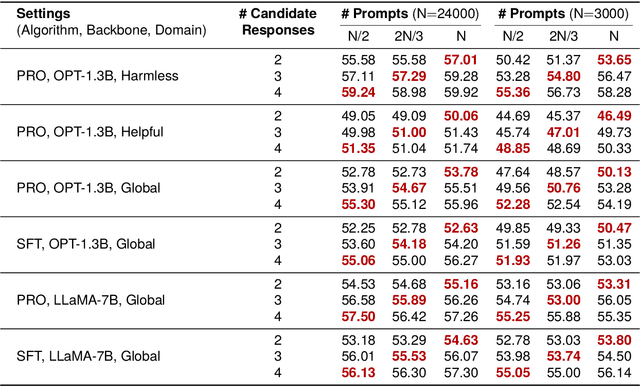
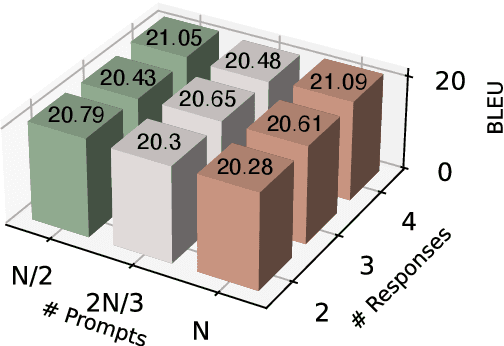
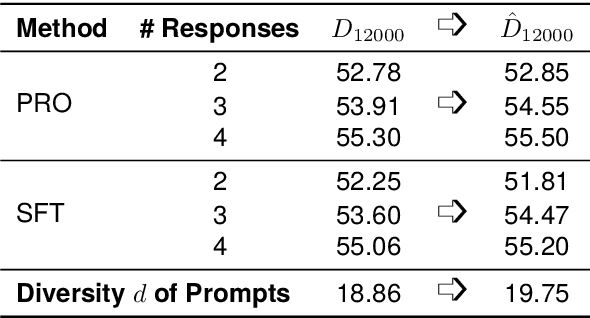
Alignment with human preference prevents large language models (LLMs) from generating misleading or toxic content while requiring high-cost human feedback. Assuming resources of human annotation are limited, there are two different ways of allocating considered: more diverse PROMPTS or more diverse RESPONSES to be labeled. Nonetheless, a straightforward comparison between their impact is absent. In this work, we first control the diversity of both sides according to the number of samples for fine-tuning, which can directly reflect their influence. We find that instead of numerous prompts, more responses but fewer prompts better trigger LLMs for human alignment. Additionally, the concept of diversity for prompts can be more complex than responses that are typically quantified by single digits. Consequently, a new formulation of prompt diversity is proposed, further implying a linear correlation with the final performance of LLMs after fine-tuning. We also leverage it on data augmentation and conduct experiments to show its effect on different algorithms.
SoFA: Shielded On-the-fly Alignment via Priority Rule Following
Feb 27, 2024



The alignment problem in Large Language Models (LLMs) involves adapting them to the broad spectrum of human values. This requirement challenges existing alignment methods due to diversity of preferences and regulatory standards. This paper introduces a novel alignment paradigm, priority rule following, which defines rules as the primary control mechanism in each dialog, prioritizing them over user instructions. Our preliminary analysis reveals that even the advanced LLMs, such as GPT-4, exhibit shortcomings in understanding and prioritizing the rules. Therefore, we present PriorityDistill, a semi-automated approach for distilling priority following signals from LLM simulations to ensure robust rule integration and adherence. Our experiments show that this method not only effectively minimizes misalignments utilizing only one general rule but also adapts smoothly to various unseen rules, ensuring they are shielded from hijacking and that the model responds appropriately.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024
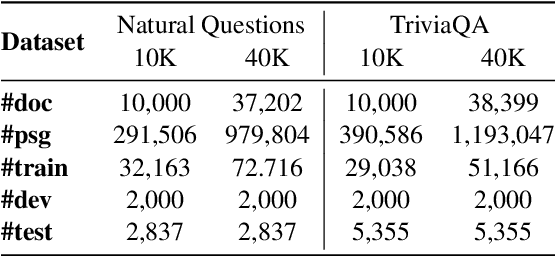
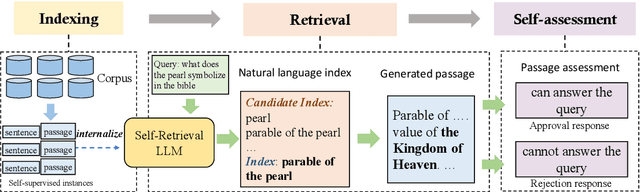
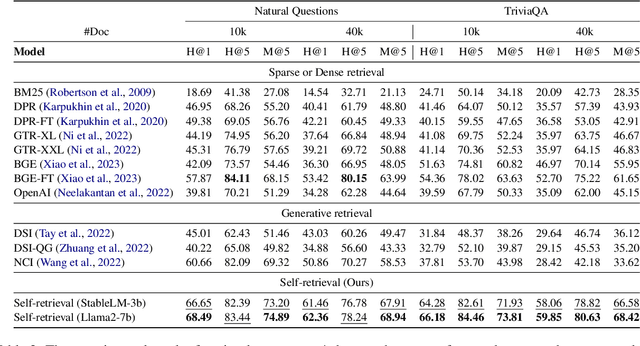
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment
Jan 23, 2024Considerable efforts have been invested in augmenting the role-playing proficiency of open-source large language models (LLMs) by emulating proprietary counterparts. Nevertheless, we posit that LLMs inherently harbor role-play capabilities, owing to the extensive knowledge of characters and potential dialogues ingrained in their vast training corpora. Thus, in this study, we introduce Ditto, a self-alignment method for role-play. Ditto capitalizes on character knowledge, encouraging an instruction-following LLM to simulate role-play dialogues as a variant of reading comprehension. This method creates a role-play training set comprising 4,000 characters, surpassing the scale of currently available datasets by tenfold regarding the number of roles. Subsequently, we fine-tune the LLM using this self-generated dataset to augment its role-playing capabilities. Upon evaluating our meticulously constructed and reproducible role-play benchmark and the roleplay subset of MT-Bench, Ditto, in various parameter scales, consistently maintains a consistent role identity and provides accurate role-specific knowledge in multi-turn role-play conversations. Notably, it outperforms all open-source role-play baselines, showcasing performance levels comparable to advanced proprietary chatbots. Furthermore, we present the first comprehensive cross-supervision alignment experiment in the role-play domain, revealing that the intrinsic capabilities of LLMs confine the knowledge within role-play. Meanwhile, the role-play styles can be easily acquired with the guidance of smaller models. We open-source related resources at https://github.com/OFA-Sys/Ditto.
Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch
Nov 06, 2023



In this paper, we uncover that Language Models (LMs), either encoder- or decoder-based, can obtain new capabilities by assimilating the parameters of homologous models without retraining or GPUs. Typically, new abilities of LMs can be imparted by Supervised Fine-Tuning (SFT), reflected in the disparity between fine-tuned and pre-trained parameters (i.e., delta parameters). We initially observe that by introducing a novel operation called DARE (Drop And REscale), most delta parameters can be directly set to zeros without affecting the capabilities of SFT LMs and larger models can tolerate a higher proportion of discarded parameters. Based on this observation, we further sparsify delta parameters of multiple SFT homologous models with DARE and subsequently merge them into a single model by parameter averaging. We conduct experiments on eight datasets from the GLUE benchmark with BERT and RoBERTa. We also merge WizardLM, WizardMath, and Code Alpaca based on Llama 2. Experimental results show that: (1) The delta parameter value ranges for SFT models are typically small, often within 0.005, and DARE can eliminate 99% of them effortlessly. However, once the models are continuously pre-trained, the value ranges can grow to around 0.03, making DARE impractical. We have also tried to remove fine-tuned instead of delta parameters and find that a 10% reduction can lead to drastically decreased performance (even to 0). This highlights that SFT merely stimulates the abilities via delta parameters rather than injecting new abilities into LMs; (2) DARE can merge multiple task-specific LMs into one LM with diverse abilities. For instance, the merger of WizardLM and WizardMath improves the GSM8K zero-shot accuracy of WizardLM from 2.2 to 66.3, retaining its instruction-following ability while surpassing WizardMath's original 64.2 performance. Codes are available at https://github.com/yule-BUAA/MergeLM.
Diversify Question Generation with Retrieval-Augmented Style Transfer
Oct 23, 2023



Given a textual passage and an answer, humans are able to ask questions with various expressions, but this ability is still challenging for most question generation (QG) systems. Existing solutions mainly focus on the internal knowledge within the given passage or the semantic word space for diverse content planning. These methods, however, have not considered the potential of external knowledge for expression diversity. To bridge this gap, we propose RAST, a framework for Retrieval-Augmented Style Transfer, where the objective is to utilize the style of diverse templates for question generation. For training RAST, we develop a novel Reinforcement Learning (RL) based approach that maximizes a weighted combination of diversity reward and consistency reward. Here, the consistency reward is computed by a Question-Answering (QA) model, whereas the diversity reward measures how much the final output mimics the retrieved template. Experimental results show that our method outperforms previous diversity-driven baselines on diversity while being comparable in terms of consistency scores. Our code is available at https://github.com/gouqi666/RAST.
Improving Question Generation with Multi-level Content Planning
Oct 23, 2023This paper addresses the problem of generating questions from a given context and an answer, specifically focusing on questions that require multi-hop reasoning across an extended context. Previous studies have suggested that key phrase selection is essential for question generation (QG), yet it is still challenging to connect such disjointed phrases into meaningful questions, particularly for long context. To mitigate this issue, we propose MultiFactor, a novel QG framework based on multi-level content planning. Specifically, MultiFactor includes two components: FA-model, which simultaneously selects key phrases and generates full answers, and Q-model which takes the generated full answer as an additional input to generate questions. Here, full answer generation is introduced to connect the short answer with the selected key phrases, thus forming an answer-aware summary to facilitate QG. Both FA-model and Q-model are formalized as simple-yet-effective Phrase-Enhanced Transformers, our joint model for phrase selection and text generation. Experimental results show that our method outperforms strong baselines on two popular QG datasets. Our code is available at https://github.com/zeaver/MultiFactor.
Quantifying and mitigating the impact of label errors on model disparity metrics
Oct 04, 2023



Errors in labels obtained via human annotation adversely affect a model's performance. Existing approaches propose ways to mitigate the effect of label error on a model's downstream accuracy, yet little is known about its impact on a model's disparity metrics. Here we study the effect of label error on a model's disparity metrics. We empirically characterize how varying levels of label error, in both training and test data, affect these disparity metrics. We find that group calibration and other metrics are sensitive to train-time and test-time label error -- particularly for minority groups. This disparate effect persists even for models trained with noise-aware algorithms. To mitigate the impact of training-time label error, we present an approach to estimate the influence of a training input's label on a model's group disparity metric. We empirically assess the proposed approach on a variety of datasets and find significant improvement, compared to alternative approaches, in identifying training inputs that improve a model's disparity metric. We complement the approach with an automatic relabel-and-finetune scheme that produces updated models with, provably, improved group calibration error.