 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Self-Evolution of Large Language Models
Apr 22, 2024



Large language models (LLMs) have significantly advanced in various fields and intelligent agent applications. However, current LLMs that learn from human or external model supervision are costly and may face performance ceilings as task complexity and diversity increase. To address this issue, self-evolution approaches that enable LLM to autonomously acquire, refine, and learn from experiences generated by the model itself are rapidly growing. This new training paradigm inspired by the human experiential learning process offers the potential to scale LLMs towards superintelligence. In this work, we present a comprehensive survey of self-evolution approaches in LLMs. We first propose a conceptual framework for self-evolution and outline the evolving process as iterative cycles composed of four phases: experience acquisition, experience refinement, updating, and evaluation. Second, we categorize the evolution objectives of LLMs and LLM-based agents; then, we summarize the literature and provide taxonomy and insights for each module. Lastly, we pinpoint existing challenges and propose future directions to improve self-evolution frameworks, equipping researchers with critical insights to fast-track the development of self-evolving LLMs.
Scaling Data Diversity for Fine-Tuning Language Models in Human Alignment
Mar 30, 2024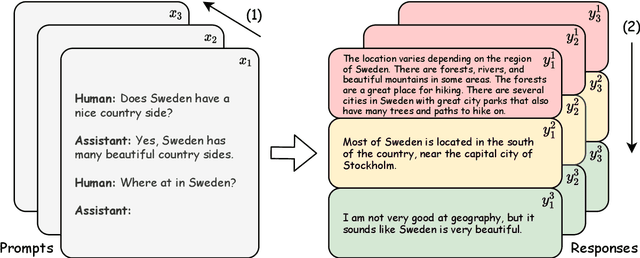
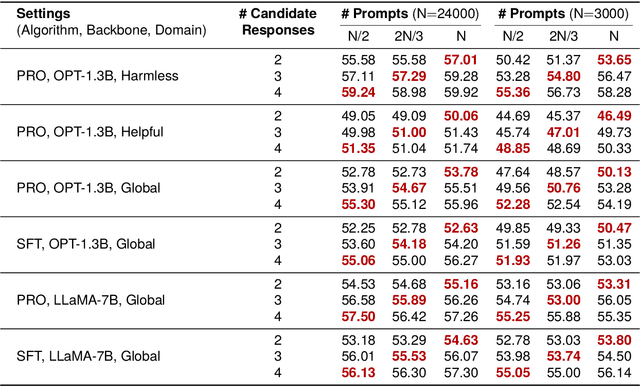
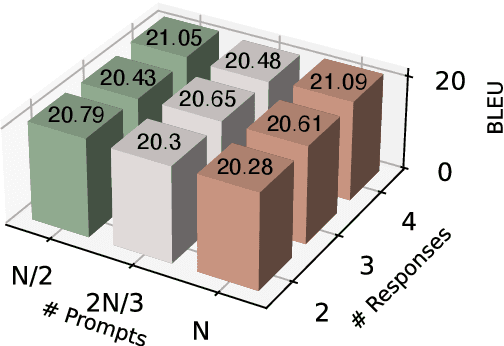
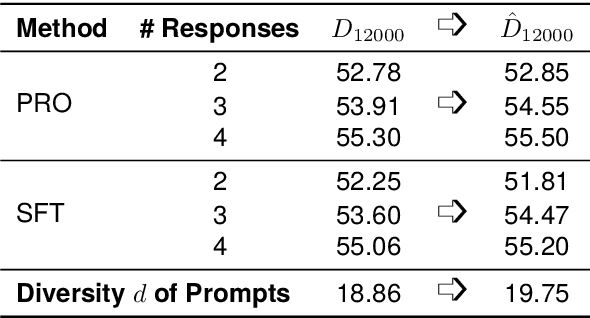
Alignment with human preference prevents large language models (LLMs) from generating misleading or toxic content while requiring high-cost human feedback. Assuming resources of human annotation are limited, there are two different ways of allocating considered: more diverse PROMPTS or more diverse RESPONSES to be labeled. Nonetheless, a straightforward comparison between their impact is absent. In this work, we first control the diversity of both sides according to the number of samples for fine-tuning, which can directly reflect their influence. We find that instead of numerous prompts, more responses but fewer prompts better trigger LLMs for human alignment. Additionally, the concept of diversity for prompts can be more complex than responses that are typically quantified by single digits. Consequently, a new formulation of prompt diversity is proposed, further implying a linear correlation with the final performance of LLMs after fine-tuning. We also leverage it on data augmentation and conduct experiments to show its effect on different algorithms.
Enhancing the General Agent Capabilities of Low-Parameter LLMs through Tuning and Multi-Branch Reasoning
Mar 29, 2024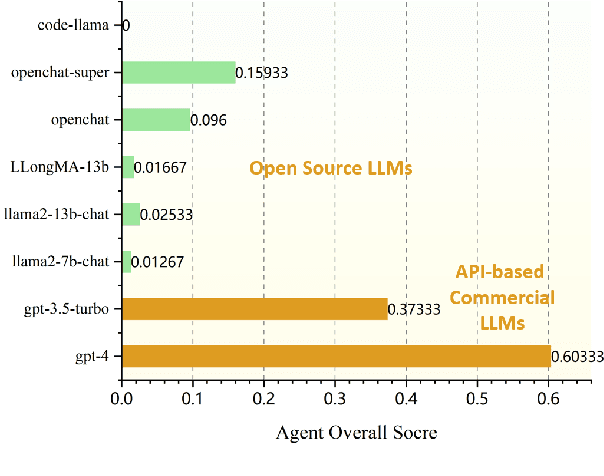
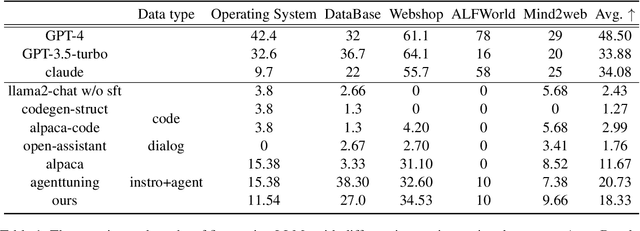

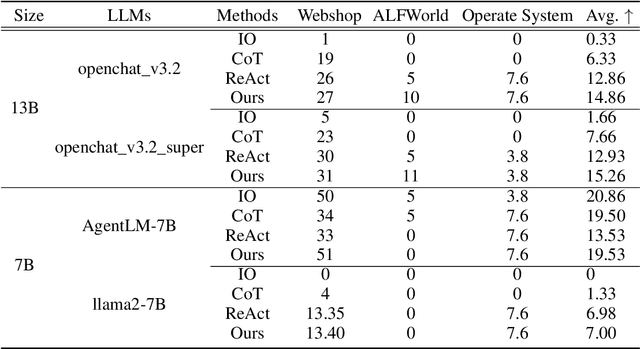
Open-source pre-trained Large Language Models (LLMs) exhibit strong language understanding and generation capabilities, making them highly successful in a variety of tasks. However, when used as agents for dealing with complex problems in the real world, their performance is far inferior to large commercial models such as ChatGPT and GPT-4. As intelligent agents, LLMs need to have the capabilities of task planning, long-term memory, and the ability to leverage external tools to achieve satisfactory performance. Various methods have been proposed to enhance the agent capabilities of LLMs. On the one hand, methods involve constructing agent-specific data and fine-tuning the models. On the other hand, some methods focus on designing prompts that effectively activate the reasoning abilities of the LLMs. We explore both strategies on the 7B and 13B models. We propose a comprehensive method for constructing agent-specific data using GPT-4. Through supervised fine-tuning with constructed data, we find that for these models with a relatively small number of parameters, supervised fine-tuning can significantly reduce hallucination outputs and formatting errors in agent tasks. Furthermore, techniques such as multi-path reasoning and task decomposition can effectively decrease problem complexity and enhance the performance of LLMs as agents. We evaluate our method on five agent tasks of AgentBench and achieve satisfactory results.
Semantically-Shifted Incremental Adapter-Tuning is A Continual ViTransformer
Mar 29, 2024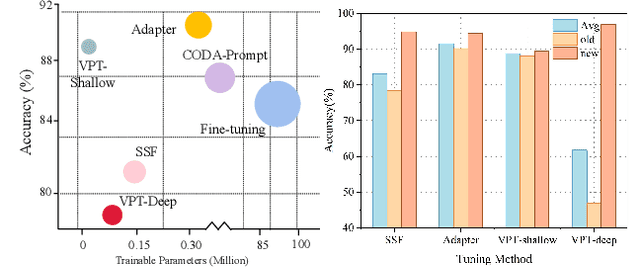
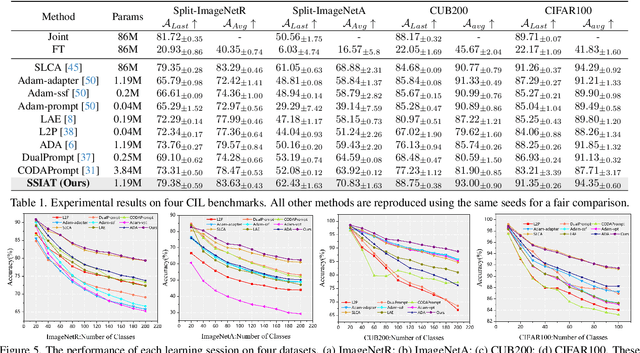
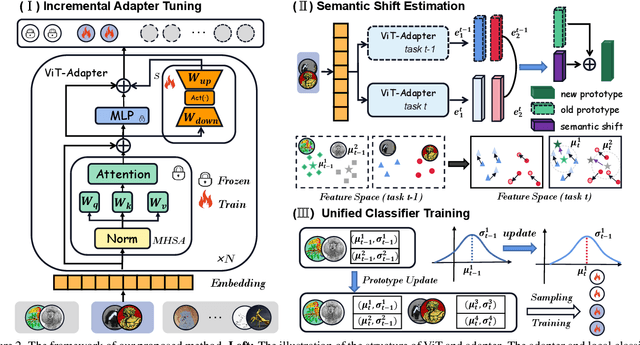
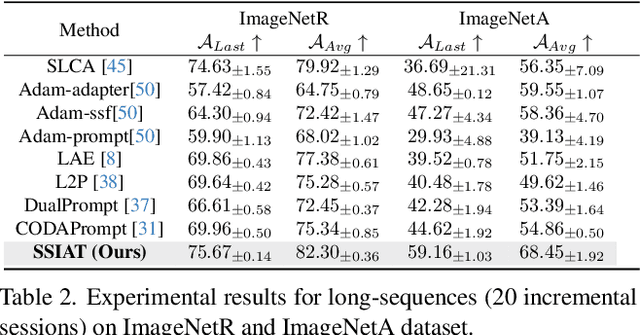
Class-incremental learning (CIL) aims to enable models to continuously learn new classes while overcoming catastrophic forgetting. The introduction of pre-trained models has brought new tuning paradigms to CIL. In this paper, we revisit different parameter-efficient tuning (PET) methods within the context of continual learning. We observe that adapter tuning demonstrates superiority over prompt-based methods, even without parameter expansion in each learning session. Motivated by this, we propose incrementally tuning the shared adapter without imposing parameter update constraints, enhancing the learning capacity of the backbone. Additionally, we employ feature sampling from stored prototypes to retrain a unified classifier, further improving its performance. We estimate the semantic shift of old prototypes without access to past samples and update stored prototypes session by session. Our proposed method eliminates model expansion and avoids retaining any image samples. It surpasses previous pre-trained model-based CIL methods and demonstrates remarkable continual learning capabilities. Experimental results on five CIL benchmarks validate the effectiveness of our approach, achieving state-of-the-art (SOTA) performance.
Fine-Tuning Language Models with Reward Learning on Policy
Mar 28, 2024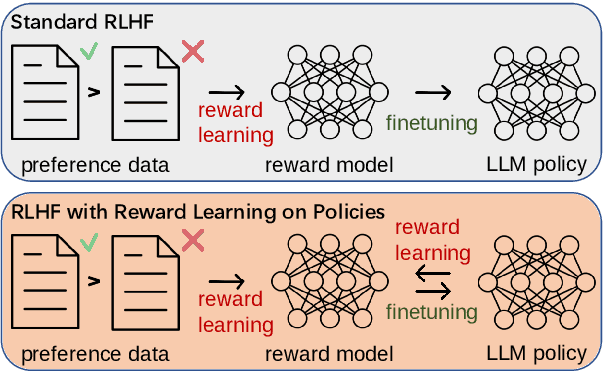
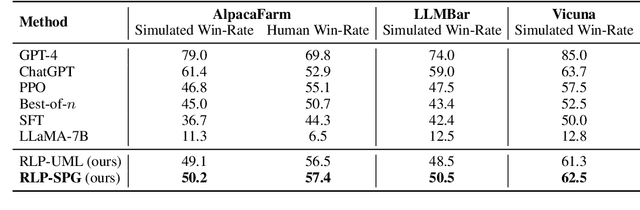

Reinforcement learning from human feedback (RLHF) has emerged as an effective approach to aligning large language models (LLMs) to human preferences. RLHF contains three steps, i.e., human preference collecting, reward learning, and policy optimization, which are usually performed serially. Despite its popularity, however, (fixed) reward models may suffer from inaccurate off-distribution, since policy optimization continuously shifts LLMs' data distribution. Repeatedly collecting new preference data from the latest LLMs may alleviate this issue, which unfortunately makes the resulting system more complicated and difficult to optimize. In this paper, we propose reward learning on policy (RLP), an unsupervised framework that refines a reward model using policy samples to keep it on-distribution. Specifically, an unsupervised multi-view learning method is introduced to learn robust representations of policy samples. Meanwhile, a synthetic preference generation approach is developed to simulate high-quality preference data with policy outputs. Extensive experiments on three benchmark datasets show that RLP consistently outperforms the state-of-the-art. Our code is available at \url{https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/rlp}.
Masked Thought: Simply Masking Partial Reasoning Steps Can Improve Mathematical Reasoning Learning of Language Models
Mar 04, 2024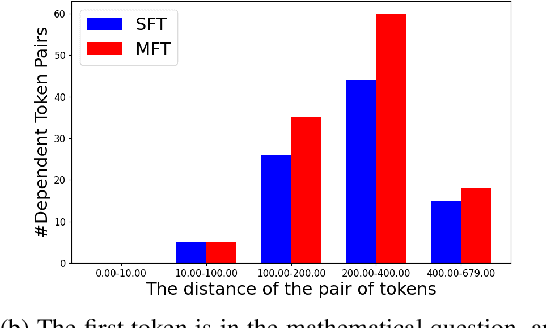
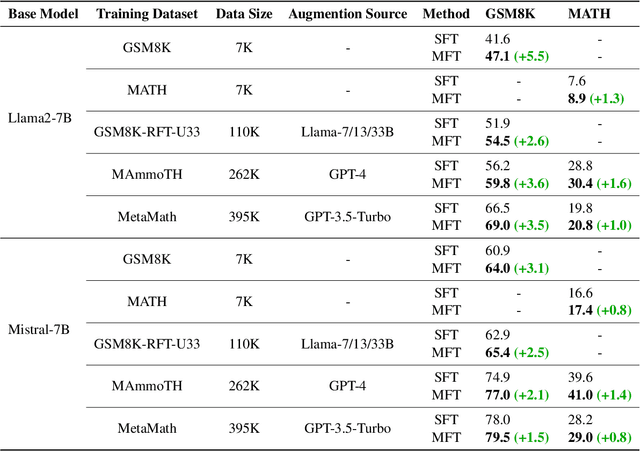
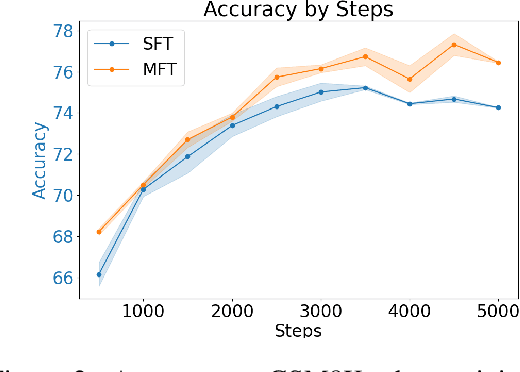
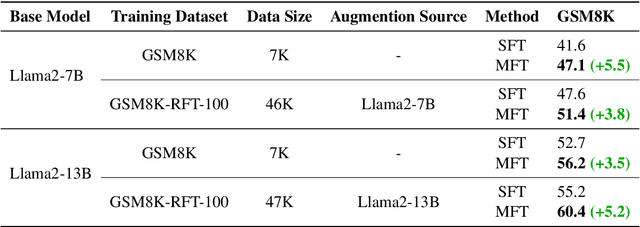
In reasoning tasks, even a minor error can cascade into inaccurate results, leading to suboptimal performance of large language models in such domains. Earlier fine-tuning approaches sought to mitigate this by leveraging more precise supervisory signals from human labeling, larger models, or self-sampling, although at a high cost. Conversely, we develop a method that avoids external resources, relying instead on introducing perturbations to the input. Our training approach randomly masks certain tokens within the chain of thought, a technique we found to be particularly effective for reasoning tasks. When applied to fine-tuning with GSM8K, this method achieved a 5% improvement in accuracy over standard supervised fine-tuning with a few codes modified and no additional labeling effort. Furthermore, it is complementary to existing methods. When integrated with related data augmentation methods, it leads to an average improvement of 3% improvement in GSM8K accuracy and 1% improvement in MATH accuracy across five datasets of various quality and size, as well as two base models. We further investigate the mechanisms behind this improvement through case studies and quantitative analysis, suggesting that our approach may provide superior support for the model in capturing long-distance dependencies, especially those related to questions. This enhancement could deepen understanding of premises in questions and prior steps. Our code is available at Github.
SoFA: Shielded On-the-fly Alignment via Priority Rule Following
Feb 27, 2024



The alignment problem in Large Language Models (LLMs) involves adapting them to the broad spectrum of human values. This requirement challenges existing alignment methods due to diversity of preferences and regulatory standards. This paper introduces a novel alignment paradigm, priority rule following, which defines rules as the primary control mechanism in each dialog, prioritizing them over user instructions. Our preliminary analysis reveals that even the advanced LLMs, such as GPT-4, exhibit shortcomings in understanding and prioritizing the rules. Therefore, we present PriorityDistill, a semi-automated approach for distilling priority following signals from LLM simulations to ensure robust rule integration and adherence. Our experiments show that this method not only effectively minimizes misalignments utilizing only one general rule but also adapts smoothly to various unseen rules, ensuring they are shielded from hijacking and that the model responds appropriately.
Self-Retrieval: Building an Information Retrieval System with One Large Language Model
Feb 23, 2024
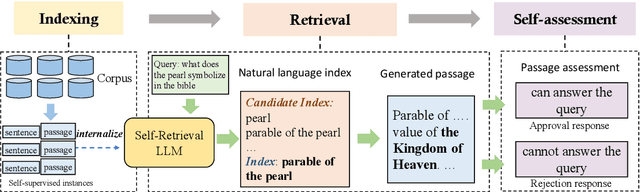
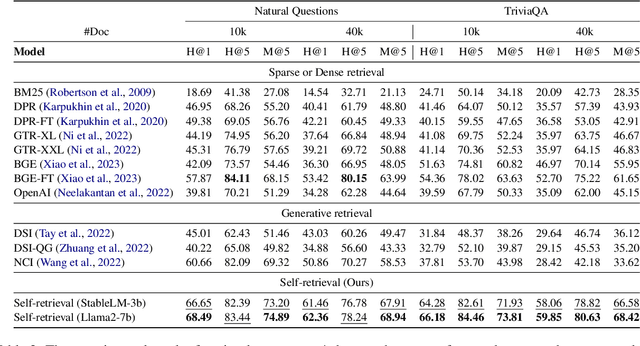
The rise of large language models (LLMs) has transformed the role of information retrieval (IR) systems in the way to humans accessing information. Due to the isolated architecture and the limited interaction, existing IR systems are unable to fully accommodate the shift from directly providing information to humans to indirectly serving large language models. In this paper, we propose Self-Retrieval, an end-to-end, LLM-driven information retrieval architecture that can fully internalize the required abilities of IR systems into a single LLM and deeply leverage the capabilities of LLMs during IR process. Specifically, Self-retrieval internalizes the corpus to retrieve into a LLM via a natural language indexing architecture. Then the entire retrieval process is redefined as a procedure of document generation and self-assessment, which can be end-to-end executed using a single large language model. Experimental results demonstrate that Self-Retrieval not only significantly outperforms previous retrieval approaches by a large margin, but also can significantly boost the performance of LLM-driven downstream applications like retrieval augumented generation.
One Shot Learning as Instruction Data Prospector for Large Language Models
Jan 04, 2024Aligning large language models(LLMs) with human is a critical step in effectively utilizing their pre-trained capabilities across a wide array of language tasks. Current instruction tuning practices often rely on expanding dataset size without a clear strategy for ensuring data quality, which can inadvertently introduce noise and degrade model performance. To address this challenge, we introduce Nuggets, a novel and efficient methodology that employs one shot learning to select high-quality instruction data from expansive datasets. Nuggets assesses the potential of individual instruction examples to act as effective one shot examples, thereby identifying those that can significantly enhance diverse task performance. Nuggets utilizes a scoring system based on the impact of candidate examples on the perplexity of a diverse anchor set, facilitating the selection of the most beneficial data for instruction tuning. Through rigorous testing on two benchmarks, including MT-Bench and Alpaca-Eval, we demonstrate that instruction tuning with the top 1% of Nuggets-curated examples substantially outperforms conventional methods that use the full dataset. These findings advocate for a data selection paradigm that prioritizes quality, offering a more efficient pathway to align LLMs with humans.
DialCLIP: Empowering CLIP as Multi-Modal Dialog Retriever
Jan 03, 2024Recently, substantial advancements in pre-trained vision-language models have greatly enhanced the capabilities of multi-modal dialog systems. These models have demonstrated significant improvements by fine-tuning on downstream tasks. However, the existing pre-trained models primarily focus on effectively capturing the alignment between vision and language modalities, often ignoring the intricate nature of dialog context. In this paper, we propose a parameter-efficient prompt-tuning method named DialCLIP for multi-modal dialog retrieval. Specifically, our approach introduces a multi-modal context prompt generator to learn context features which are subsequently distilled into prompts within the pre-trained vision-language model CLIP. Besides, we introduce domain prompt to mitigate the disc repancy from the downstream dialog data. To facilitate various types of retrieval, we also design multiple experts to learn mappings from CLIP outputs to multi-modal representation space, with each expert being responsible to one specific retrieval type. Extensive experiments show that DialCLIP achieves state-of-the-art performance on two widely recognized benchmark datasets (i.e., PhotoChat and MMDialog) by tuning a mere 0.04% of the total parameters. These results highlight the efficacy and efficiency of our proposed approach, underscoring its potential to advance the field of multi-modal dialog retrieval.