 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedSAC: Dynamic Submodel Allocation for Collaborative Fairness in Federated Learning
May 28, 2024Collaborative fairness stands as an essential element in federated learning to encourage client participation by equitably distributing rewards based on individual contributions. Existing methods primarily focus on adjusting gradient allocations among clients to achieve collaborative fairness. However, they frequently overlook crucial factors such as maintaining consistency across local models and catering to the diverse requirements of high-contributing clients. This oversight inevitably decreases both fairness and model accuracy in practice. To address these issues, we propose FedSAC, a novel Federated learning framework with dynamic Submodel Allocation for Collaborative fairness, backed by a theoretical convergence guarantee. First, we present the concept of "bounded collaborative fairness (BCF)", which ensures fairness by tailoring rewards to individual clients based on their contributions. Second, to implement the BCF, we design a submodel allocation module with a theoretical guarantee of fairness. This module incentivizes high-contributing clients with high-performance submodels containing a diverse range of crucial neurons, thereby preserving consistency across local models. Third, we further develop a dynamic aggregation module to adaptively aggregate submodels, ensuring the equitable treatment of low-frequency neurons and consequently enhancing overall model accuracy. Extensive experiments conducted on three public benchmarks demonstrate that FedSAC outperforms all baseline methods in both fairness and model accuracy. We see this work as a significant step towards incentivizing broader client participation in federated learning. The source code is available at https://github.com/wangzihuixmu/FedSAC.
Commonsense Prototype for Outdoor Unsupervised 3D Object Detection
Apr 25, 2024The prevalent approaches of unsupervised 3D object detection follow cluster-based pseudo-label generation and iterative self-training processes. However, the challenge arises due to the sparsity of LiDAR scans, which leads to pseudo-labels with erroneous size and position, resulting in subpar detection performance. To tackle this problem, this paper introduces a Commonsense Prototype-based Detector, termed CPD, for unsupervised 3D object detection. CPD first constructs Commonsense Prototype (CProto) characterized by high-quality bounding box and dense points, based on commonsense intuition. Subsequently, CPD refines the low-quality pseudo-labels by leveraging the size prior from CProto. Furthermore, CPD enhances the detection accuracy of sparsely scanned objects by the geometric knowledge from CProto. CPD outperforms state-of-the-art unsupervised 3D detectors on Waymo Open Dataset (WOD), PandaSet, and KITTI datasets by a large margin. Besides, by training CPD on WOD and testing on KITTI, CPD attains 90.85% and 81.01% 3D Average Precision on easy and moderate car classes, respectively. These achievements position CPD in close proximity to fully supervised detectors, highlighting the significance of our method. The code will be available at https://github.com/hailanyi/CPD.
FedPFT: Federated Proxy Fine-Tuning of Foundation Models
Apr 17, 2024Adapting Foundation Models (FMs) for downstream tasks through Federated Learning (FL) emerges a promising strategy for protecting data privacy and valuable FMs. Existing methods fine-tune FM by allocating sub-FM to clients in FL, however, leading to suboptimal performance due to insufficient tuning and inevitable error accumulations of gradients. In this paper, we propose Federated Proxy Fine-Tuning (FedPFT), a novel method enhancing FMs adaptation in downstream tasks through FL by two key modules. First, the sub-FM construction module employs a layer-wise compression approach, facilitating comprehensive FM fine-tuning across all layers by emphasizing those crucial neurons. Second, the sub-FM alignment module conducts a two-step distillations-layer-level and neuron-level-before and during FL fine-tuning respectively, to reduce error of gradient by accurately aligning sub-FM with FM under theoretical guarantees. Experimental results on seven commonly used datasets (i.e., four text and three vision) demonstrate the superiority of FedPFT.
Real-time guidewire tracking and segmentation in intraoperative x-ray
Apr 12, 2024During endovascular interventions, physicians have to perform accurate and immediate operations based on the available real-time information, such as the shape and position of guidewires observed on the fluoroscopic images, haptic information and the patients' physiological signals. For this purpose, real-time and accurate guidewire segmentation and tracking can enhance the visualization of guidewires and provide visual feedback for physicians during the intervention as well as for robot-assisted interventions. Nevertheless, this task often comes with the challenge of elongated deformable structures that present themselves with low contrast in the noisy fluoroscopic image sequences. To address these issues, a two-stage deep learning framework for real-time guidewire segmentation and tracking is proposed. In the first stage, a Yolov5s detector is trained, using the original X-ray images as well as synthetic ones, which is employed to output the bounding boxes of possible target guidewires. More importantly, a refinement module based on spatiotemporal constraints is incorporated to robustly localize the guidewire and remove false detections. In the second stage, a novel and efficient network is proposed to segment the guidewire in each detected bounding box. The network contains two major modules, namely a hessian-based enhancement embedding module and a dual self-attention module. Quantitative and qualitative evaluations on clinical intra-operative images demonstrate that the proposed approach significantly outperforms our baselines as well as the current state of the art and, in comparison, shows higher robustness to low quality images.
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
Mar 28, 2024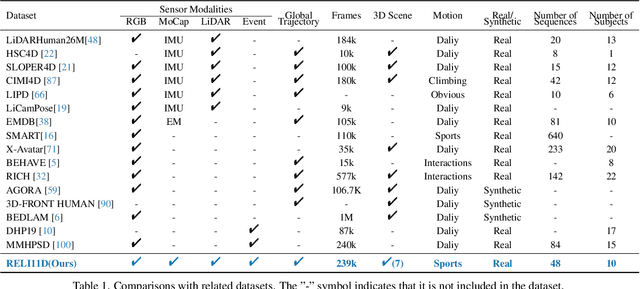

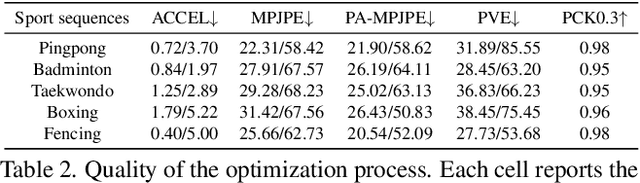

Comprehensive capturing of human motions requires both accurate captures of complex poses and precise localization of the human within scenes. Most of the HPE datasets and methods primarily rely on RGB, LiDAR, or IMU data. However, solely using these modalities or a combination of them may not be adequate for HPE, particularly for complex and fast movements. For holistic human motion understanding, we present RELI11D, a high-quality multimodal human motion dataset involves LiDAR, IMU system, RGB camera, and Event camera. It records the motions of 10 actors performing 5 sports in 7 scenes, including 3.32 hours of synchronized LiDAR point clouds, IMU measurement data, RGB videos and Event steams. Through extensive experiments, we demonstrate that the RELI11D presents considerable challenges and opportunities as it contains many rapid and complex motions that require precise location. To address the challenge of integrating different modalities, we propose LEIR, a multimodal baseline that effectively utilizes LiDAR Point Cloud, Event stream, and RGB through our cross-attention fusion strategy. We show that LEIR exhibits promising results for rapid motions and daily motions and that utilizing the characteristics of multiple modalities can indeed improve HPE performance. Both the dataset and source code will be released publicly to the research community, fostering collaboration and enabling further exploration in this field.
Density-guided Translator Boosts Synthetic-to-Real Unsupervised Domain Adaptive Segmentation of 3D Point Clouds
Mar 27, 2024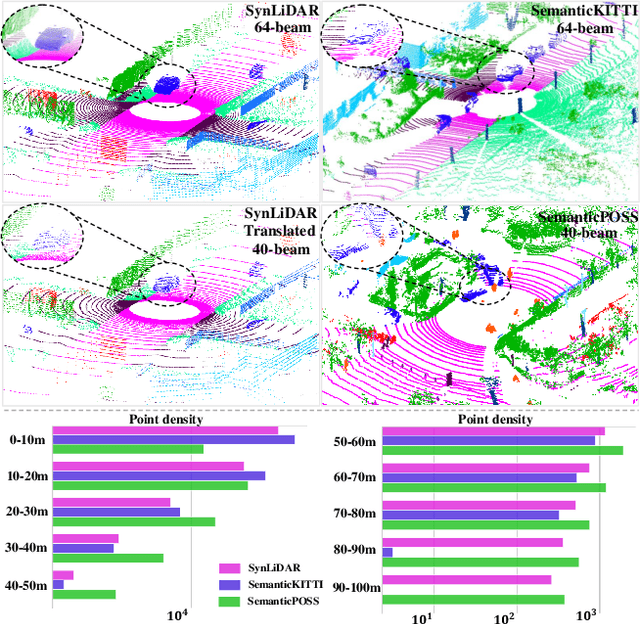
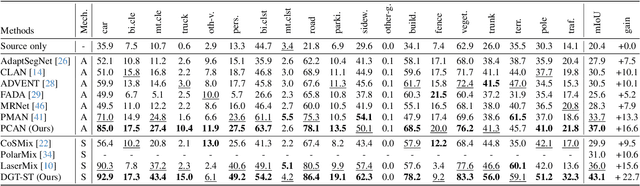
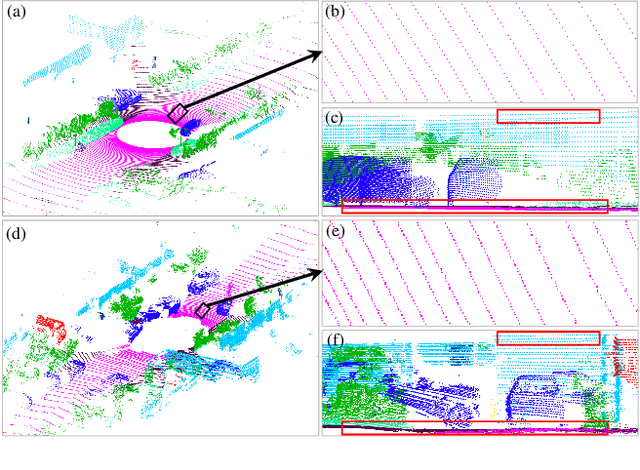
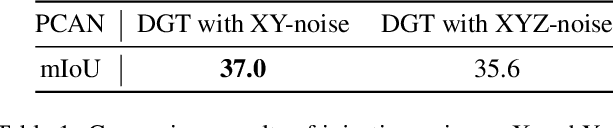
3D synthetic-to-real unsupervised domain adaptive segmentation is crucial to annotating new domains. Self-training is a competitive approach for this task, but its performance is limited by different sensor sampling patterns (i.e., variations in point density) and incomplete training strategies. In this work, we propose a density-guided translator (DGT), which translates point density between domains, and integrates it into a two-stage self-training pipeline named DGT-ST. First, in contrast to existing works that simultaneously conduct data generation and feature/output alignment within unstable adversarial training, we employ the non-learnable DGT to bridge the domain gap at the input level. Second, to provide a well-initialized model for self-training, we propose a category-level adversarial network in stage one that utilizes the prototype to prevent negative transfer. Finally, by leveraging the designs above, a domain-mixed self-training method with source-aware consistency loss is proposed in stage two to narrow the domain gap further. Experiments on two synthetic-to-real segmentation tasks (SynLiDAR $\rightarrow$ semanticKITTI and SynLiDAR $\rightarrow$ semanticPOSS) demonstrate that DGT-ST outperforms state-of-the-art methods, achieving 9.4$\%$ and 4.3$\%$ mIoU improvements, respectively. Code is available at \url{https://github.com/yuan-zm/DGT-ST}.
Large Language Models Need Consultants for Reasoning: Becoming an Expert in a Complex Human System Through Behavior Simulation
Mar 27, 2024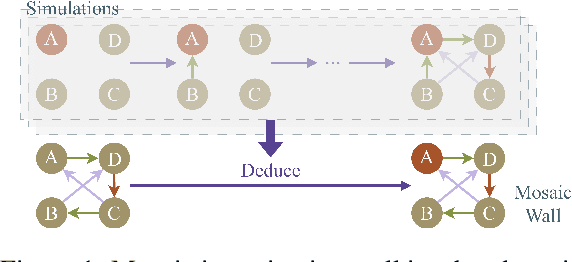

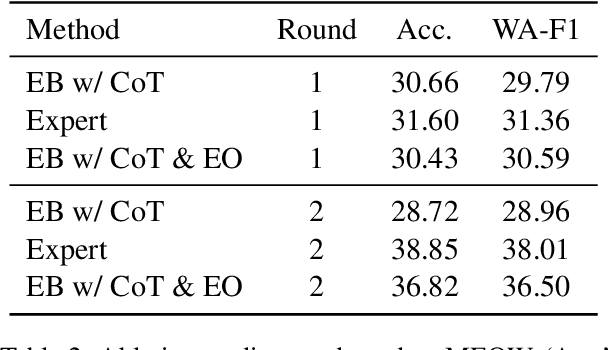
Large language models (LLMs), in conjunction with various reasoning reinforcement methodologies, have demonstrated remarkable capabilities comparable to humans in fields such as mathematics, law, coding, common sense, and world knowledge. In this paper, we delve into the reasoning abilities of LLMs within complex human systems. We propose a novel reasoning framework, termed ``Mosaic Expert Observation Wall'' (MEOW) exploiting generative-agents-based simulation technique. In the MEOW framework, simulated data are utilized to train an expert model concentrating ``experience'' about a specific task in each independent time of simulation. It is the accumulated ``experience'' through the simulation that makes for an expert on a task in a complex human system. We conduct the experiments within a communication game that mirrors real-world security scenarios. The results indicate that our proposed methodology can cooperate with existing methodologies to enhance the reasoning abilities of LLMs in complex human systems.
G4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Mar 02, 2024Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.
Sunshine to Rainstorm: Cross-Weather Knowledge Distillation for Robust 3D Object Detection
Feb 28, 2024LiDAR-based 3D object detection models have traditionally struggled under rainy conditions due to the degraded and noisy scanning signals. Previous research has attempted to address this by simulating the noise from rain to improve the robustness of detection models. However, significant disparities exist between simulated and actual rain-impacted data points. In this work, we propose a novel rain simulation method, termed DRET, that unifies Dynamics and Rainy Environment Theory to provide a cost-effective means of expanding the available realistic rain data for 3D detection training. Furthermore, we present a Sunny-to-Rainy Knowledge Distillation (SRKD) approach to enhance 3D detection under rainy conditions. Extensive experiments on the WaymoOpenDataset large-scale dataset show that, when combined with the state-of-the-art DSVT model and other classical 3D detectors, our proposed framework demonstrates significant detection accuracy improvements, without losing efficiency. Remarkably, our framework also improves detection capabilities under sunny conditions, therefore offering a robust solution for 3D detection regardless of whether the weather is rainy or sunny
GIM: Learning Generalizable Image Matcher From Internet Videos
Feb 16, 2024Image matching is a fundamental computer vision problem. While learning-based methods achieve state-of-the-art performance on existing benchmarks, they generalize poorly to in-the-wild images. Such methods typically need to train separate models for different scene types and are impractical when the scene type is unknown in advance. One of the underlying problems is the limited scalability of existing data construction pipelines, which limits the diversity of standard image matching datasets. To address this problem, we propose GIM, a self-training framework for learning a single generalizable model based on any image matching architecture using internet videos, an abundant and diverse data source. Given an architecture, GIM first trains it on standard domain-specific datasets and then combines it with complementary matching methods to create dense labels on nearby frames of novel videos. These labels are filtered by robust fitting, and then enhanced by propagating them to distant frames. The final model is trained on propagated data with strong augmentations. We also propose ZEB, the first zero-shot evaluation benchmark for image matching. By mixing data from diverse domains, ZEB can thoroughly assess the cross-domain generalization performance of different methods. Applying GIM consistently improves the zero-shot performance of 3 state-of-the-art image matching architectures; with 50 hours of YouTube videos, the relative zero-shot performance improves by 8.4%-18.1%. GIM also enables generalization to extreme cross-domain data such as Bird Eye View (BEV) images of projected 3D point clouds (Fig. 1(c)). More importantly, our single zero-shot model consistently outperforms domain-specific baselines when evaluated on downstream tasks inherent to their respective domains. The video presentation is available at https://www.youtube.com/watch?v=FU_MJLD8LeY.