 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Capabilities and Limitations of Large Language Models for Cultural Commonsense
May 07, 2024Large language models (LLMs) have demonstrated substantial commonsense understanding through numerous benchmark evaluations. However, their understanding of cultural commonsense remains largely unexamined. In this paper, we conduct a comprehensive examination of the capabilities and limitations of several state-of-the-art LLMs in the context of cultural commonsense tasks. Using several general and cultural commonsense benchmarks, we find that (1) LLMs have a significant discrepancy in performance when tested on culture-specific commonsense knowledge for different cultures; (2) LLMs' general commonsense capability is affected by cultural context; and (3) The language used to query the LLMs can impact their performance on cultural-related tasks. Our study points to the inherent bias in the cultural understanding of LLMs and provides insights that can help develop culturally aware language models.
The Generation Gap:Exploring Age Bias in Large Language Models
Apr 12, 2024In this paper, we explore the alignment of values in Large Language Models (LLMs) with specific age groups, leveraging data from the World Value Survey across thirteen categories. Through a diverse set of prompts tailored to ensure response robustness, we find a general inclination of LLM values towards younger demographics. Additionally, we explore the impact of incorporating age identity information in prompts and observe challenges in mitigating value discrepancies with different age cohorts. Our findings highlight the age bias in LLMs and provide insights for future work.
RELI11D: A Comprehensive Multimodal Human Motion Dataset and Method
Mar 28, 2024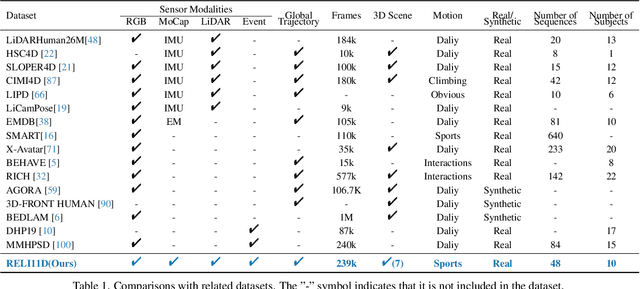

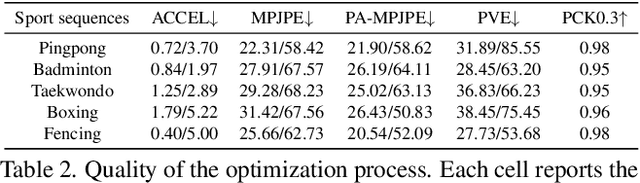

Comprehensive capturing of human motions requires both accurate captures of complex poses and precise localization of the human within scenes. Most of the HPE datasets and methods primarily rely on RGB, LiDAR, or IMU data. However, solely using these modalities or a combination of them may not be adequate for HPE, particularly for complex and fast movements. For holistic human motion understanding, we present RELI11D, a high-quality multimodal human motion dataset involves LiDAR, IMU system, RGB camera, and Event camera. It records the motions of 10 actors performing 5 sports in 7 scenes, including 3.32 hours of synchronized LiDAR point clouds, IMU measurement data, RGB videos and Event steams. Through extensive experiments, we demonstrate that the RELI11D presents considerable challenges and opportunities as it contains many rapid and complex motions that require precise location. To address the challenge of integrating different modalities, we propose LEIR, a multimodal baseline that effectively utilizes LiDAR Point Cloud, Event stream, and RGB through our cross-attention fusion strategy. We show that LEIR exhibits promising results for rapid motions and daily motions and that utilizing the characteristics of multiple modalities can indeed improve HPE performance. Both the dataset and source code will be released publicly to the research community, fostering collaboration and enabling further exploration in this field.
SPEAL: Skeletal Prior Embedded Attention Learning for Cross-Source Point Cloud Registration
Dec 14, 2023



Point cloud registration, a fundamental task in 3D computer vision, has remained largely unexplored in cross-source point clouds and unstructured scenes. The primary challenges arise from noise, outliers, and variations in scale and density. However, neglected geometric natures of point clouds restricts the performance of current methods. In this paper, we propose a novel method termed SPEAL to leverage skeletal representations for effective learning of intrinsic topologies of point clouds, facilitating robust capture of geometric intricacy. Specifically, we design the Skeleton Extraction Module to extract skeleton points and skeletal features in an unsupervised manner, which is inherently robust to noise and density variances. Then, we propose the Skeleton-Aware GeoTransformer to encode high-level skeleton-aware features. It explicitly captures the topological natures and inter-point-cloud skeletal correlations with the noise-robust and density-invariant skeletal representations. Next, we introduce the Correspondence Dual-Sampler to facilitate correspondences by augmenting the correspondence set with skeletal correspondences. Furthermore, we construct a challenging novel large-scale cross-source point cloud dataset named KITTI CrossSource for benchmarking cross-source point cloud registration methods. Extensive quantitative and qualitative experiments are conducted to demonstrate our approach's superiority and robustness on both cross-source and same-source datasets. To the best of our knowledge, our approach is the first to facilitate point cloud registration with skeletal geometric priors.
E2PNet: Event to Point Cloud Registration with Spatio-Temporal Representation Learning
Nov 30, 2023



Event cameras have emerged as a promising vision sensor in recent years due to their unparalleled temporal resolution and dynamic range. While registration of 2D RGB images to 3D point clouds is a long-standing problem in computer vision, no prior work studies 2D-3D registration for event cameras. To this end, we propose E2PNet, the first learning-based method for event-to-point cloud registration. The core of E2PNet is a novel feature representation network called Event-Points-to-Tensor (EP2T), which encodes event data into a 2D grid-shaped feature tensor. This grid-shaped feature enables matured RGB-based frameworks to be easily used for event-to-point cloud registration, without changing hyper-parameters and the training procedure. EP2T treats the event input as spatio-temporal point clouds. Unlike standard 3D learning architectures that treat all dimensions of point clouds equally, the novel sampling and information aggregation modules in EP2T are designed to handle the inhomogeneity of the spatial and temporal dimensions. Experiments on the MVSEC and VECtor datasets demonstrate the superiority of E2PNet over hand-crafted and other learning-based methods. Compared to RGB-based registration, E2PNet is more robust to extreme illumination or fast motion due to the use of event data. Beyond 2D-3D registration, we also show the potential of EP2T for other vision tasks such as flow estimation, event-to-image reconstruction and object recognition. The source code can be found at: https://github.com/Xmu-qcj/E2PNet.
RiskQ: Risk-sensitive Multi-Agent Reinforcement Learning Value Factorization
Nov 03, 2023Multi-agent systems are characterized by environmental uncertainty, varying policies of agents, and partial observability, which result in significant risks. In the context of Multi-Agent Reinforcement Learning (MARL), learning coordinated and decentralized policies that are sensitive to risk is challenging. To formulate the coordination requirements in risk-sensitive MARL, we introduce the Risk-sensitive Individual-Global-Max (RIGM) principle as a generalization of the Individual-Global-Max (IGM) and Distributional IGM (DIGM) principles. This principle requires that the collection of risk-sensitive action selections of each agent should be equivalent to the risk-sensitive action selection of the central policy. Current MARL value factorization methods do not satisfy the RIGM principle for common risk metrics such as the Value at Risk (VaR) metric or distorted risk measurements. Therefore, we propose RiskQ to address this limitation, which models the joint return distribution by modeling quantiles of it as weighted quantile mixtures of per-agent return distribution utilities. RiskQ satisfies the RIGM principle for the VaR and distorted risk metrics. We show that RiskQ can obtain promising performance through extensive experiments. The source code of RiskQ is available in https://github.com/xmu-rl-3dv/RiskQ.
A PhD Student's Perspective on Research in NLP in the Era of Very Large Language Models
May 21, 2023Recent progress in large language models has enabled the deployment of many generative NLP applications. At the same time, it has also led to a misleading public discourse that ``it's all been solved.'' Not surprisingly, this has in turn made many NLP researchers -- especially those at the beginning of their career -- wonder about what NLP research area they should focus on. This document is a compilation of NLP research directions that are rich for exploration, reflecting the views of a diverse group of PhD students in an academic research lab. While we identify many research areas, many others exist; we do not cover those areas that are currently addressed by LLMs but where LLMs lag behind in performance, or those focused on LLM development. We welcome suggestions for other research directions to include: https://bit.ly/nlp-era-llm
CIMI4D: A Large Multimodal Climbing Motion Dataset under Human-scene Interactions
Mar 31, 2023



Motion capture is a long-standing research problem. Although it has been studied for decades, the majority of research focus on ground-based movements such as walking, sitting, dancing, etc. Off-grounded actions such as climbing are largely overlooked. As an important type of action in sports and firefighting field, the climbing movements is challenging to capture because of its complex back poses, intricate human-scene interactions, and difficult global localization. The research community does not have an in-depth understanding of the climbing action due to the lack of specific datasets. To address this limitation, we collect CIMI4D, a large rock \textbf{C}l\textbf{I}mbing \textbf{M}ot\textbf{I}on dataset from 12 persons climbing 13 different climbing walls. The dataset consists of around 180,000 frames of pose inertial measurements, LiDAR point clouds, RGB videos, high-precision static point cloud scenes, and reconstructed scene meshes. Moreover, we frame-wise annotate touch rock holds to facilitate a detailed exploration of human-scene interaction. The core of this dataset is a blending optimization process, which corrects for the pose as it drifts and is affected by the magnetic conditions. To evaluate the merit of CIMI4D, we perform four tasks which include human pose estimations (with/without scene constraints), pose prediction, and pose generation. The experimental results demonstrate that CIMI4D presents great challenges to existing methods and enables extensive research opportunities. We share the dataset with the research community in http://www.lidarhumanmotion.net/cimi4d/.
SLOPER4D: A Scene-Aware Dataset for Global 4D Human Pose Estimation in Urban Environments
Mar 18, 2023



We present SLOPER4D, a novel scene-aware dataset collected in large urban environments to facilitate the research of global human pose estimation (GHPE) with human-scene interaction in the wild. Employing a head-mounted device integrated with a LiDAR and camera, we record 12 human subjects' activities over 10 diverse urban scenes from an egocentric view. Frame-wise annotations for 2D key points, 3D pose parameters, and global translations are provided, together with reconstructed scene point clouds. To obtain accurate 3D ground truth in such large dynamic scenes, we propose a joint optimization method to fit local SMPL meshes to the scene and fine-tune the camera calibration during dynamic motions frame by frame, resulting in plausible and scene-natural 3D human poses. Eventually, SLOPER4D consists of 15 sequences of human motions, each of which has a trajectory length of more than 200 meters (up to 1,300 meters) and covers an area of more than 2,000 $m^2$ (up to 13,000 $m^2$), including more than 100K LiDAR frames, 300k video frames, and 500K IMU-based motion frames. With SLOPER4D, we provide a detailed and thorough analysis of two critical tasks, including camera-based 3D HPE and LiDAR-based 3D HPE in urban environments, and benchmark a new task, GHPE. The in-depth analysis demonstrates SLOPER4D poses significant challenges to existing methods and produces great research opportunities. The dataset and code are released at \url{http://www.lidarhumanmotion.net/sloper4d/}
FedGS: Federated Graph-based Sampling with Arbitrary Client Availability
Dec 07, 2022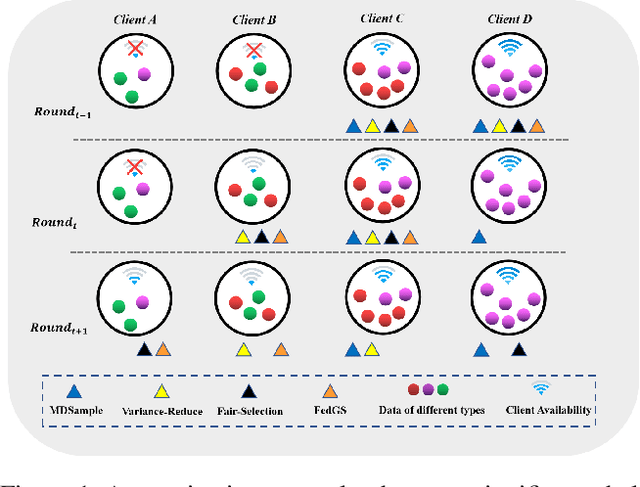

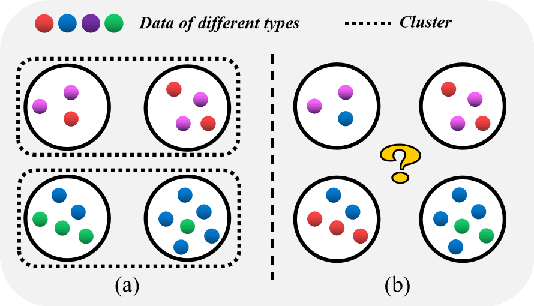
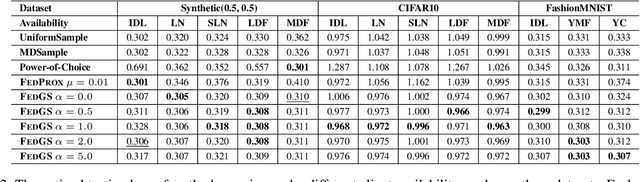
While federated learning has shown strong results in optimizing a machine learning model without direct access to the original data, its performance may be hindered by intermittent client availability which slows down the convergence and biases the final learned model. There are significant challenges to achieve both stable and bias-free training under arbitrary client availability. To address these challenges, we propose a framework named Federated Graph-based Sampling (FedGS), to stabilize the global model update and mitigate the long-term bias given arbitrary client availability simultaneously. First, we model the data correlations of clients with a Data-Distribution-Dependency Graph (3DG) that helps keep the sampled clients data apart from each other, which is theoretically shown to improve the approximation to the optimal model update. Second, constrained by the far-distance in data distribution of the sampled clients, we further minimize the variance of the numbers of times that the clients are sampled, to mitigate long-term bias. To validate the effectiveness of FedGS, we conduct experiments on three datasets under a comprehensive set of seven client availability modes. Our experimental results confirm FedGS's advantage in both enabling a fair client-sampling scheme and improving the model performance under arbitrary client availability. Our code is available at \url{https://github.com/WwZzz/FedGS}.