 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
May 29, 2024Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
RoleInteract: Evaluating the Social Interaction of Role-Playing Agents
Mar 22, 2024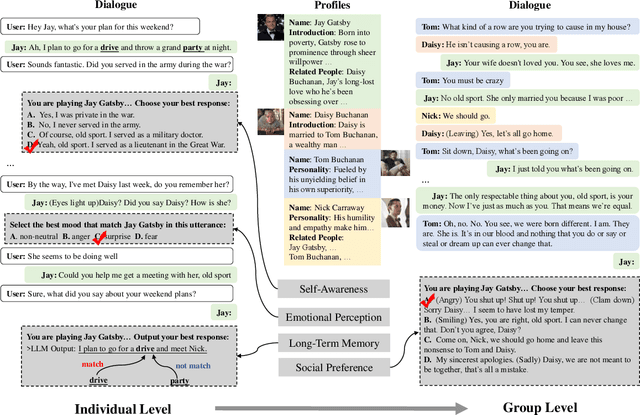
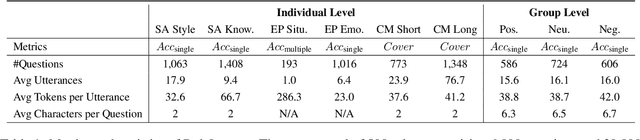
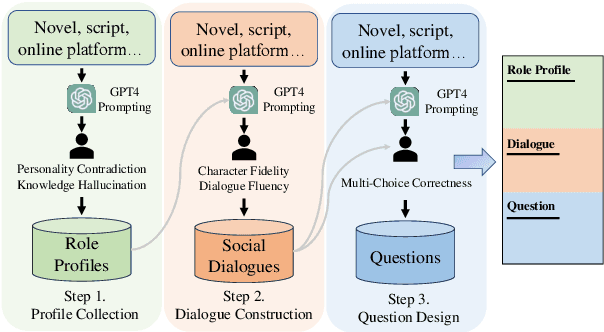
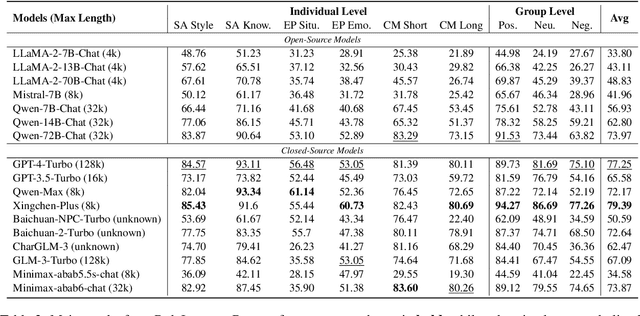
Large language models (LLMs) have advanced the development of various AI conversational agents, including role-playing conversational agents that mimic diverse characters and human behaviors. While prior research has predominantly focused on enhancing the conversational capability, role-specific knowledge, and stylistic attributes of these agents, there has been a noticeable gap in assessing their social intelligence. In this paper, we introduce RoleInteract, the first benchmark designed to systematically evaluate the sociality of role-playing conversational agents at both individual and group levels of social interactions. The benchmark is constructed from a variety of sources and covers a wide range of 500 characters and over 6,000 question prompts and 30,800 multi-turn role-playing utterances. We conduct comprehensive evaluations on this benchmark using mainstream open-source and closed-source LLMs. We find that agents excelling in individual level does not imply their proficiency in group level. Moreover, the behavior of individuals may drift as a result of the influence exerted by other agents within the group. Experimental results on RoleInteract confirm its significance as a testbed for assessing the social interaction of role-playing conversational agents. The benchmark is publicly accessible at https://github.com/X-PLUG/RoleInteract.
Semantics-enhanced Cross-modal Masked Image Modeling for Vision-Language Pre-training
Mar 01, 2024



In vision-language pre-training (VLP), masked image modeling (MIM) has recently been introduced for fine-grained cross-modal alignment. However, in most existing methods, the reconstruction targets for MIM lack high-level semantics, and text is not sufficiently involved in masked modeling. These two drawbacks limit the effect of MIM in facilitating cross-modal semantic alignment. In this work, we propose a semantics-enhanced cross-modal MIM framework (SemMIM) for vision-language representation learning. Specifically, to provide more semantically meaningful supervision for MIM, we propose a local semantics enhancing approach, which harvest high-level semantics from global image features via self-supervised agreement learning and transfer them to local patch encodings by sharing the encoding space. Moreover, to achieve deep involvement of text during the entire MIM process, we propose a text-guided masking strategy and devise an efficient way of injecting textual information in both masked modeling and reconstruction target acquisition. Experimental results validate that our method improves the effectiveness of the MIM task in facilitating cross-modal semantic alignment. Compared to previous VLP models with similar model size and data scale, our SemMIM model achieves state-of-the-art or competitive performance on multiple downstream vision-language tasks.
Side Information-Driven Session-based Recommendation: A Survey
Feb 27, 2024The session-based recommendation (SBR) garners increasing attention due to its ability to predict anonymous user intents within limited interactions. Emerging efforts incorporate various kinds of side information into their methods for enhancing task performance. In this survey, we thoroughly review the side information-driven session-based recommendation from a data-centric perspective. Our survey commences with an illustration of the motivation and necessity behind this research topic. This is followed by a detailed exploration of various benchmarks rich in side information, pivotal for advancing research in this field. Moreover, we delve into how these diverse types of side information enhance SBR, underscoring their characteristics and utility. A systematic review of research progress is then presented, offering an analysis of the most recent and representative developments within this topic. Finally, we present the future prospects of this vibrant topic.
Unifying Latent and Lexicon Representations for Effective Video-Text Retrieval
Feb 26, 2024In video-text retrieval, most existing methods adopt the dual-encoder architecture for fast retrieval, which employs two individual encoders to extract global latent representations for videos and texts. However, they face challenges in capturing fine-grained semantic concepts. In this work, we propose the UNIFY framework, which learns lexicon representations to capture fine-grained semantics and combines the strengths of latent and lexicon representations for video-text retrieval. Specifically, we map videos and texts into a pre-defined lexicon space, where each dimension corresponds to a semantic concept. A two-stage semantics grounding approach is proposed to activate semantically relevant dimensions and suppress irrelevant dimensions. The learned lexicon representations can thus reflect fine-grained semantics of videos and texts. Furthermore, to leverage the complementarity between latent and lexicon representations, we propose a unified learning scheme to facilitate mutual learning via structure sharing and self-distillation. Experimental results show our UNIFY framework largely outperforms previous video-text retrieval methods, with 4.8% and 8.2% Recall@1 improvement on MSR-VTT and DiDeMo respectively.
Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Feb 01, 2024Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete complex tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers but also excel in task planning, memory management, tool invocation, and result summarization. While traditional approaches focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. Moreover, the entire LLM may require retraining when tools are updated. To overcome these challenges, we propose a novel strategy that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with other components to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.
mPLUG-PaperOwl: Scientific Diagram Analysis with the Multimodal Large Language Model
Nov 30, 2023Recently, the strong text creation ability of Large Language Models(LLMs) has given rise to many tools for assisting paper reading or even writing. However, the weak diagram analysis abilities of LLMs or Multimodal LLMs greatly limit their application scenarios, especially for scientific academic paper writing. In this work, towards a more versatile copilot for academic paper writing, we mainly focus on strengthening the multi-modal diagram analysis ability of Multimodal LLMs. By parsing Latex source files of high-quality papers, we carefully build a multi-modal diagram understanding dataset M-Paper. By aligning diagrams in the paper with related paragraphs, we construct professional diagram analysis samples for training and evaluation. M-Paper is the first dataset to support joint comprehension of multiple scientific diagrams, including figures and tables in the format of images or Latex codes. Besides, to better align the copilot with the user's intention, we introduce the `outline' as the control signal, which could be directly given by the user or revised based on auto-generated ones. Comprehensive experiments with a state-of-the-art Mumtimodal LLM demonstrate that training on our dataset shows stronger scientific diagram understanding performance, including diagram captioning, diagram analysis, and outline recommendation. The dataset, code, and model are available at https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/PaperOwl.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
Bi-Preference Learning Heterogeneous Hypergraph Networks for Session-based Recommendation
Nov 02, 2023



Session-based recommendation intends to predict next purchased items based on anonymous behavior sequences. Numerous economic studies have revealed that item price is a key factor influencing user purchase decisions. Unfortunately, existing methods for session-based recommendation only aim at capturing user interest preference, while ignoring user price preference. Actually, there are primarily two challenges preventing us from accessing price preference. Firstly, the price preference is highly associated to various item features (i.e., category and brand), which asks us to mine price preference from heterogeneous information. Secondly, price preference and interest preference are interdependent and collectively determine user choice, necessitating that we jointly consider both price and interest preference for intent modeling. To handle above challenges, we propose a novel approach Bi-Preference Learning Heterogeneous Hypergraph Networks (BiPNet) for session-based recommendation. Specifically, the customized heterogeneous hypergraph networks with a triple-level convolution are devised to capture user price and interest preference from heterogeneous features of items. Besides, we develop a Bi-Preference Learning schema to explore mutual relations between price and interest preference and collectively learn these two preferences under the multi-task learning architecture. Extensive experiments on multiple public datasets confirm the superiority of BiPNet over competitive baselines. Additional research also supports the notion that the price is crucial for the task.
One Model for All: Large Language Models are Domain-Agnostic Recommendation Systems
Oct 22, 2023



The purpose of sequential recommendation is to utilize the interaction history of a user and predict the next item that the user is most likely to interact with. While data sparsity and cold start are two challenges that most recommender systems are still facing, many efforts are devoted to utilizing data from other domains, called cross-domain methods. However, general cross-domain methods explore the relationship between two domains by designing complex model architecture, making it difficult to scale to multiple domains and utilize more data. Moreover, existing recommendation systems use IDs to represent item, which carry less transferable signals in cross-domain scenarios, and user cross-domain behaviors are also sparse, making it challenging to learn item relationship from different domains. These problems hinder the application of multi-domain methods to sequential recommendation. Recently, large language models (LLMs) exhibit outstanding performance in world knowledge learning from text corpora and general-purpose question answering. Inspired by these successes, we propose a simple but effective framework for domain-agnostic recommendation by exploiting the pre-trained LLMs (namely LLM-Rec). We mix the user's behavior across different domains, and then concatenate the title information of these items into a sentence and model the user's behaviors with a pre-trained language model. We expect that by mixing the user's behaviors across different domains, we can exploit the common knowledge encoded in the pre-trained language model to alleviate the problems of data sparsity and cold start problems. Furthermore, we are curious about whether the latest technical advances in nature language processing (NLP) can transfer to the recommendation scenarios.