 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHongfei Lin
Enhancing Textual Personality Detection toward Social Media: Integrating Long-term and Short-term Perspectives
Apr 23, 2024
Textual personality detection aims to identify personality characteristics by analyzing user-generated content toward social media platforms. Numerous psychological literature highlighted that personality encompasses both long-term stable traits and short-term dynamic states. However, existing studies often concentrate only on either long-term or short-term personality representations, without effectively combining both aspects. This limitation hinders a comprehensive understanding of individuals' personalities, as both stable traits and dynamic states are vital. To bridge this gap, we propose a Dual Enhanced Network(DEN) to jointly model users' long-term and short-term personality for textual personality detection. In DEN, a Long-term Personality Encoding is devised to effectively model long-term stable personality traits. Short-term Personality Encoding is presented to capture short-term dynamic personality states. The Bi-directional Interaction component facilitates the integration of both personality aspects, allowing for a comprehensive representation of the user's personality. Experimental results on two personality detection datasets demonstrate the effectiveness of the DEN model and the benefits of considering both the dynamic and stable nature of personality characteristics for textual personality detection.
FineRec:Exploring Fine-grained Sequential Recommendation
Apr 19, 2024Sequential recommendation is dedicated to offering items of interest for users based on their history behaviors. The attribute-opinion pairs, expressed by users in their reviews for items, provide the potentials to capture user preferences and item characteristics at a fine-grained level. To this end, we propose a novel framework FineRec that explores the attribute-opinion pairs of reviews to finely handle sequential recommendation. Specifically, we utilize a large language model to extract attribute-opinion pairs from reviews. For each attribute, a unique attribute-specific user-opinion-item graph is created, where corresponding opinions serve as the edges linking heterogeneous user and item nodes. To tackle the diversity of opinions, we devise a diversity-aware convolution operation to aggregate information within the graphs, enabling attribute-specific user and item representation learning. Ultimately, we present an interaction-driven fusion mechanism to integrate attribute-specific user/item representations across all attributes for generating recommendations. Extensive experiments conducted on several realworld datasets demonstrate the superiority of our FineRec over existing state-of-the-art methods. Further analysis also verifies the effectiveness of our fine-grained manner in handling the task.
Disentangling ID and Modality Effects for Session-based Recommendation
Apr 19, 2024Session-based recommendation aims to predict intents of anonymous users based on their limited behaviors. Modeling user behaviors involves two distinct rationales: co-occurrence patterns reflected by item IDs, and fine-grained preferences represented by item modalities (e.g., text and images). However, existing methods typically entangle these causes, leading to their failure in achieving accurate and explainable recommendations. To this end, we propose a novel framework DIMO to disentangle the effects of ID and modality in the task. At the item level, we introduce a co-occurrence representation schema to explicitly incorporate cooccurrence patterns into ID representations. Simultaneously, DIMO aligns different modalities into a unified semantic space to represent them uniformly. At the session level, we present a multi-view self-supervised disentanglement, including proxy mechanism and counterfactual inference, to disentangle ID and modality effects without supervised signals. Leveraging these disentangled causes, DIMO provides recommendations via causal inference and further creates two templates for generating explanations. Extensive experiments on multiple real-world datasets demonstrate the consistent superiority of DIMO over existing methods. Further analysis also confirms DIMO's effectiveness in generating explanations.
Side Information-Driven Session-based Recommendation: A Survey
Feb 27, 2024The session-based recommendation (SBR) garners increasing attention due to its ability to predict anonymous user intents within limited interactions. Emerging efforts incorporate various kinds of side information into their methods for enhancing task performance. In this survey, we thoroughly review the side information-driven session-based recommendation from a data-centric perspective. Our survey commences with an illustration of the motivation and necessity behind this research topic. This is followed by a detailed exploration of various benchmarks rich in side information, pivotal for advancing research in this field. Moreover, we delve into how these diverse types of side information enhance SBR, underscoring their characteristics and utility. A systematic review of research progress is then presented, offering an analysis of the most recent and representative developments within this topic. Finally, we present the future prospects of this vibrant topic.
Taiyi: A Bilingual Fine-Tuned Large Language Model for Diverse Biomedical Tasks
Nov 20, 2023



Recent advancements in large language models (LLMs) have shown promising results across a variety of natural language processing (NLP) tasks. The application of LLMs to specific domains, such as biomedicine, has achieved increased attention. However, most biomedical LLMs focus on enhancing performance in monolingual biomedical question answering and conversation tasks. To further investigate the effectiveness of the LLMs on diverse biomedical NLP tasks in different languages, we present Taiyi, a bilingual (English and Chinese) fine-tuned LLM for diverse biomedical tasks. In this work, we first curated a comprehensive collection of 140 existing biomedical text mining datasets across over 10 task types. Subsequently, a two-stage strategy is proposed for supervised fine-tuning to optimize the model performance across varied tasks. Experimental results on 13 test sets covering named entity recognition, relation extraction, text classification, question answering tasks demonstrate Taiyi achieves superior performance compared to general LLMs. The case study involving additional biomedical NLP tasks further shows Taiyi's considerable potential for bilingual biomedical multi-tasking. The source code, datasets, and model for Taiyi are freely available at https://github.com/DUTIR-BioNLP/Taiyi-LLM.
Bi-Preference Learning Heterogeneous Hypergraph Networks for Session-based Recommendation
Nov 02, 2023



Session-based recommendation intends to predict next purchased items based on anonymous behavior sequences. Numerous economic studies have revealed that item price is a key factor influencing user purchase decisions. Unfortunately, existing methods for session-based recommendation only aim at capturing user interest preference, while ignoring user price preference. Actually, there are primarily two challenges preventing us from accessing price preference. Firstly, the price preference is highly associated to various item features (i.e., category and brand), which asks us to mine price preference from heterogeneous information. Secondly, price preference and interest preference are interdependent and collectively determine user choice, necessitating that we jointly consider both price and interest preference for intent modeling. To handle above challenges, we propose a novel approach Bi-Preference Learning Heterogeneous Hypergraph Networks (BiPNet) for session-based recommendation. Specifically, the customized heterogeneous hypergraph networks with a triple-level convolution are devised to capture user price and interest preference from heterogeneous features of items. Besides, we develop a Bi-Preference Learning schema to explore mutual relations between price and interest preference and collectively learn these two preferences under the multi-task learning architecture. Extensive experiments on multiple public datasets confirm the superiority of BiPNet over competitive baselines. Additional research also supports the notion that the price is crucial for the task.
A Transformer-Based Model With Self-Distillation for Multimodal Emotion Recognition in Conversations
Oct 31, 2023Emotion recognition in conversations (ERC), the task of recognizing the emotion of each utterance in a conversation, is crucial for building empathetic machines. Existing studies focus mainly on capturing context- and speaker-sensitive dependencies on the textual modality but ignore the significance of multimodal information. Different from emotion recognition in textual conversations, capturing intra- and inter-modal interactions between utterances, learning weights between different modalities, and enhancing modal representations play important roles in multimodal ERC. In this paper, we propose a transformer-based model with self-distillation (SDT) for the task. The transformer-based model captures intra- and inter-modal interactions by utilizing intra- and inter-modal transformers, and learns weights between modalities dynamically by designing a hierarchical gated fusion strategy. Furthermore, to learn more expressive modal representations, we treat soft labels of the proposed model as extra training supervision. Specifically, we introduce self-distillation to transfer knowledge of hard and soft labels from the proposed model to each modality. Experiments on IEMOCAP and MELD datasets demonstrate that SDT outperforms previous state-of-the-art baselines.
* 13 pages, 10 figures. Accepted by IEEE Transactions on Multimedia (TMM)
Beyond Co-occurrence: Multi-modal Session-based Recommendation
Sep 29, 2023



Session-based recommendation is devoted to characterizing preferences of anonymous users based on short sessions. Existing methods mostly focus on mining limited item co-occurrence patterns exposed by item ID within sessions, while ignoring what attracts users to engage with certain items is rich multi-modal information displayed on pages. Generally, the multi-modal information can be classified into two categories: descriptive information (e.g., item images and description text) and numerical information (e.g., price). In this paper, we aim to improve session-based recommendation by modeling the above multi-modal information holistically. There are mainly three issues to reveal user intent from multi-modal information: (1) How to extract relevant semantics from heterogeneous descriptive information with different noise? (2) How to fuse these heterogeneous descriptive information to comprehensively infer user interests? (3) How to handle probabilistic influence of numerical information on user behaviors? To solve above issues, we propose a novel multi-modal session-based recommendation (MMSBR) that models both descriptive and numerical information under a unified framework. Specifically, a pseudo-modality contrastive learning is devised to enhance the representation learning of descriptive information. Afterwards, a hierarchical pivot transformer is presented to fuse heterogeneous descriptive information. Moreover, we represent numerical information with Gaussian distribution and design a Wasserstein self-attention to handle the probabilistic influence mode. Extensive experiments on three real-world datasets demonstrate the effectiveness of the proposed MMSBR. Further analysis also proves that our MMSBR can alleviate the cold-start problem in SBR effectively.
KESDT: knowledge enhanced shallow and deep Transformer for detecting adverse drug reactions
Aug 18, 2023



Adverse drug reaction (ADR) detection is an essential task in the medical field, as ADRs have a gravely detrimental impact on patients' health and the healthcare system. Due to a large number of people sharing information on social media platforms, an increasing number of efforts focus on social media data to carry out effective ADR detection. Despite having achieved impressive performance, the existing methods of ADR detection still suffer from three main challenges. Firstly, researchers have consistently ignored the interaction between domain keywords and other words in the sentence. Secondly, social media datasets suffer from the challenges of low annotated data. Thirdly, the issue of sample imbalance is commonly observed in social media datasets. To solve these challenges, we propose the Knowledge Enhanced Shallow and Deep Transformer(KESDT) model for ADR detection. Specifically, to cope with the first issue, we incorporate the domain keywords into the Transformer model through a shallow fusion manner, which enables the model to fully exploit the interactive relationships between domain keywords and other words in the sentence. To overcome the low annotated data, we integrate the synonym sets into the Transformer model through a deep fusion manner, which expands the size of the samples. To mitigate the impact of sample imbalance, we replace the standard cross entropy loss function with the focal loss function for effective model training. We conduct extensive experiments on three public datasets including TwiMed, Twitter, and CADEC. The proposed KESDT outperforms state-of-the-art baselines on F1 values, with relative improvements of 4.87%, 47.83%, and 5.73% respectively, which demonstrates the effectiveness of our proposed KESDT.
ZRIGF: An Innovative Multimodal Framework for Zero-Resource Image-Grounded Dialogue Generation
Aug 02, 2023
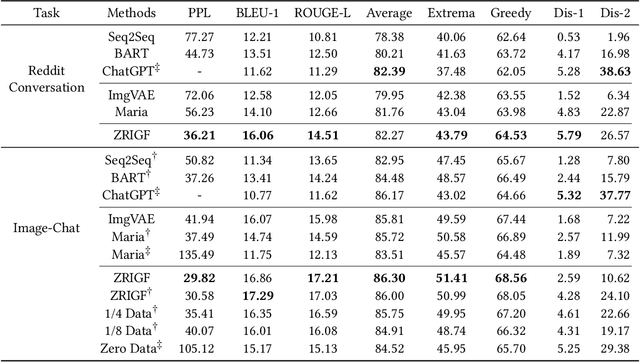


Image-grounded dialogue systems benefit greatly from integrating visual information, resulting in high-quality response generation. However, current models struggle to effectively utilize such information in zero-resource scenarios, mainly due to the disparity between image and text modalities. To overcome this challenge, we propose an innovative multimodal framework, called ZRIGF, which assimilates image-grounded information for dialogue generation in zero-resource situations. ZRIGF implements a two-stage learning strategy, comprising contrastive pre-training and generative pre-training. Contrastive pre-training includes a text-image matching module that maps images and texts into a unified encoded vector space, along with a text-assisted masked image modeling module that preserves pre-training visual features and fosters further multimodal feature alignment. Generative pre-training employs a multimodal fusion module and an information transfer module to produce insightful responses based on harmonized multimodal representations. Comprehensive experiments conducted on both text-based and image-grounded dialogue datasets demonstrate ZRIGF's efficacy in generating contextually pertinent and informative responses. Furthermore, we adopt a fully zero-resource scenario in the image-grounded dialogue dataset to demonstrate our framework's robust generalization capabilities in novel domains. The code is available at https://github.com/zhangbo-nlp/ZRIGF.