 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
Jun 07, 2024Parameter-Efficient Fine-tuning (PEFT) facilitates the fine-tuning of Large Language Models (LLMs) under limited resources. However, the fine-tuning performance with PEFT on complex, knowledge-intensive tasks is limited due to the constrained model capacity, which originates from the limited number of additional trainable parameters. To overcome this limitation, we introduce a novel mechanism that fine-tunes LLMs with adapters of larger size yet memory-efficient. This is achieved by leveraging the inherent activation sparsity in the Feed-Forward Networks (FFNs) of LLMs and utilizing the larger capacity of Central Processing Unit (CPU) memory compared to Graphics Processing Unit (GPU). We store and update the parameters of larger adapters on the CPU. Moreover, we employ a Mixture of Experts (MoE)-like architecture to mitigate unnecessary CPU computations and reduce the communication volume between the GPU and CPU. This is particularly beneficial over the limited bandwidth of PCI Express (PCIe). Our method can achieve fine-tuning results comparable to those obtained with larger memory capacities, even when operating under more limited resources such as a 24GB memory single GPU setup, with acceptable loss in training efficiency. Our codes are available at https://github.com/CURRENTF/MEFT.
E-ICL: Enhancing Fine-Grained Emotion Recognition through the Lens of Prototype Theory
Jun 04, 2024In-context learning (ICL) achieves remarkable performance in various domains such as knowledge acquisition, commonsense reasoning, and semantic understanding. However, its performance significantly deteriorates for emotion detection tasks, especially fine-grained emotion recognition. The underlying reasons for this remain unclear. In this paper, we identify the reasons behind ICL's poor performance from the perspective of prototype theory and propose a method to address this issue. Specifically, we conduct extensive pilot experiments and find that ICL conforms to the prototype theory on fine-grained emotion recognition. Based on this theory, we uncover the following deficiencies in ICL: (1) It relies on prototypes (example-label pairs) that are semantically similar but emotionally inaccurate to predict emotions. (2) It is prone to interference from irrelevant categories, affecting the accuracy and robustness of the predictions. To address these issues, we propose an Emotion Context Learning method (E-ICL) on fine-grained emotion recognition. E-ICL relies on more emotionally accurate prototypes to predict categories by referring to emotionally similar examples with dynamic labels. Simultaneously, E-ICL employs an exclusionary emotion prediction strategy to avoid interference from irrelevant categories, thereby increasing its accuracy and robustness. Note that the entire process is accomplished with the assistance of a plug-and-play emotion auxiliary model, without additional training. Experiments on the fine-grained emotion datasets EDOS, Empathetic-Dialogues, EmpatheticIntent, and GoEmotions show that E-ICL achieves superior emotion prediction performance. Furthermore, even when the emotion auxiliary model used is lower than 10% of the LLMs, E-ICL can still boost the performance of LLMs by over 4% on multiple datasets.
Chain of Tools: Large Language Model is an Automatic Multi-tool Learner
May 26, 2024Augmenting large language models (LLMs) with external tools has emerged as a promising approach to extend their utility, empowering them to solve practical tasks. Existing work typically empowers LLMs as tool users with a manually designed workflow, where the LLM plans a series of tools in a step-by-step manner, and sequentially executes each tool to obtain intermediate results until deriving the final answer. However, they suffer from two challenges in realistic scenarios: (1) The handcrafted control flow is often ad-hoc and constraints the LLM to local planning; (2) The LLM is instructed to use only manually demonstrated tools or well-trained Python functions, which limits its generalization to new tools. In this work, we first propose Automatic Tool Chain (ATC), a framework that enables the LLM to act as a multi-tool user, which directly utilizes a chain of tools through programming. To scale up the scope of the tools, we next propose a black-box probing method. This further empowers the LLM as a tool learner that can actively discover and document tool usages, teaching themselves to properly master new tools. For a comprehensive evaluation, we build a challenging benchmark named ToolFlow, which diverges from previous benchmarks by its long-term planning scenarios and complex toolset. Experiments on both existing datasets and ToolFlow illustrate the superiority of our framework. Analysis on different settings also validates the effectiveness and the utility of our black-box probing algorithm.
ExcluIR: Exclusionary Neural Information Retrieval
Apr 26, 2024Exclusion is an important and universal linguistic skill that humans use to express what they do not want. However, in information retrieval community, there is little research on exclusionary retrieval, where users express what they do not want in their queries. In this work, we investigate the scenario of exclusionary retrieval in document retrieval for the first time. We present ExcluIR, a set of resources for exclusionary retrieval, consisting of an evaluation benchmark and a training set for helping retrieval models to comprehend exclusionary queries. The evaluation benchmark includes 3,452 high-quality exclusionary queries, each of which has been manually annotated. The training set contains 70,293 exclusionary queries, each paired with a positive document and a negative document. We conduct detailed experiments and analyses, obtaining three main observations: (1) Existing retrieval models with different architectures struggle to effectively comprehend exclusionary queries; (2) Although integrating our training data can improve the performance of retrieval models on exclusionary retrieval, there still exists a gap compared to human performance; (3) Generative retrieval models have a natural advantage in handling exclusionary queries. To facilitate future research on exclusionary retrieval, we share the benchmark and evaluation scripts on \url{https://github.com/zwh-sdu/ExcluIR}.
Disentangling ID and Modality Effects for Session-based Recommendation
Apr 19, 2024Session-based recommendation aims to predict intents of anonymous users based on their limited behaviors. Modeling user behaviors involves two distinct rationales: co-occurrence patterns reflected by item IDs, and fine-grained preferences represented by item modalities (e.g., text and images). However, existing methods typically entangle these causes, leading to their failure in achieving accurate and explainable recommendations. To this end, we propose a novel framework DIMO to disentangle the effects of ID and modality in the task. At the item level, we introduce a co-occurrence representation schema to explicitly incorporate cooccurrence patterns into ID representations. Simultaneously, DIMO aligns different modalities into a unified semantic space to represent them uniformly. At the session level, we present a multi-view self-supervised disentanglement, including proxy mechanism and counterfactual inference, to disentangle ID and modality effects without supervised signals. Leveraging these disentangled causes, DIMO provides recommendations via causal inference and further creates two templates for generating explanations. Extensive experiments on multiple real-world datasets demonstrate the consistent superiority of DIMO over existing methods. Further analysis also confirms DIMO's effectiveness in generating explanations.
Offline Trajectory Generalization for Offline Reinforcement Learning
Apr 16, 2024Offline reinforcement learning (RL) aims to learn policies from static datasets of previously collected trajectories. Existing methods for offline RL either constrain the learned policy to the support of offline data or utilize model-based virtual environments to generate simulated rollouts. However, these methods suffer from (i) poor generalization to unseen states; and (ii) trivial improvement from low-qualified rollout simulation. In this paper, we propose offline trajectory generalization through world transformers for offline reinforcement learning (OTTO). Specifically, we use casual Transformers, a.k.a. World Transformers, to predict state dynamics and the immediate reward. Then we propose four strategies to use World Transformers to generate high-rewarded trajectory simulation by perturbing the offline data. Finally, we jointly use offline data with simulated data to train an offline RL algorithm. OTTO serves as a plug-in module and can be integrated with existing offline RL methods to enhance them with better generalization capability of transformers and high-rewarded data augmentation. Conducting extensive experiments on D4RL benchmark datasets, we verify that OTTO significantly outperforms state-of-the-art offline RL methods.
Generative Retrieval as Multi-Vector Dense Retrieval
Mar 31, 2024Generative retrieval generates identifiers of relevant documents in an end-to-end manner using a sequence-to-sequence architecture for a given query. The relation between generative retrieval and other retrieval methods, especially those based on matching within dense retrieval models, is not yet fully comprehended. Prior work has demonstrated that generative retrieval with atomic identifiers is equivalent to single-vector dense retrieval. Accordingly, generative retrieval exhibits behavior analogous to hierarchical search within a tree index in dense retrieval when using hierarchical semantic identifiers. However, prior work focuses solely on the retrieval stage without considering the deep interactions within the decoder of generative retrieval. In this paper, we fill this gap by demonstrating that generative retrieval and multi-vector dense retrieval share the same framework for measuring the relevance to a query of a document. Specifically, we examine the attention layer and prediction head of generative retrieval, revealing that generative retrieval can be understood as a special case of multi-vector dense retrieval. Both methods compute relevance as a sum of products of query and document vectors and an alignment matrix. We then explore how generative retrieval applies this framework, employing distinct strategies for computing document token vectors and the alignment matrix. We have conducted experiments to verify our conclusions and show that both paradigms exhibit commonalities of term matching in their alignment matrix.
CAUSE: Counterfactual Assessment of User Satisfaction Estimation in Task-Oriented Dialogue Systems
Mar 27, 2024
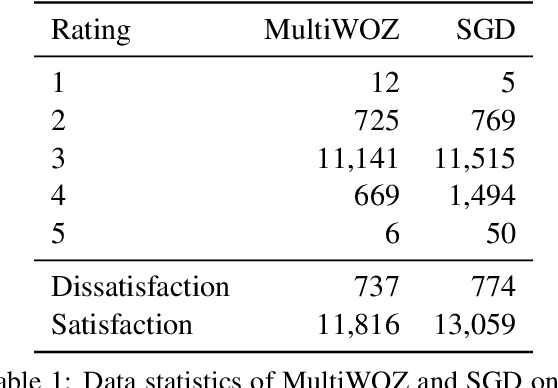

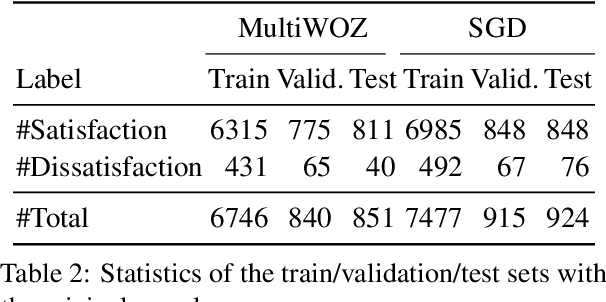
An important unexplored aspect in previous work on user satisfaction estimation for Task-Oriented Dialogue (TOD) systems is their evaluation in terms of robustness for the identification of user dissatisfaction: current benchmarks for user satisfaction estimation in TOD systems are highly skewed towards dialogues for which the user is satisfied. The effect of having a more balanced set of satisfaction labels on performance is unknown. However, balancing the data with more dissatisfactory dialogue samples requires further data collection and human annotation, which is costly and time-consuming. In this work, we leverage large language models (LLMs) and unlock their ability to generate satisfaction-aware counterfactual dialogues to augment the set of original dialogues of a test collection. We gather human annotations to ensure the reliability of the generated samples. We evaluate two open-source LLMs as user satisfaction estimators on our augmented collection against state-of-the-art fine-tuned models. Our experiments show that when used as few-shot user satisfaction estimators, open-source LLMs show higher robustness to the increase in the number of dissatisfaction labels in the test collection than the fine-tuned state-of-the-art models. Our results shed light on the need for data augmentation approaches for user satisfaction estimation in TOD systems. We release our aligned counterfactual dialogues, which are curated by human annotation, to facilitate further research on this topic.
Enhanced Generative Recommendation via Content and Collaboration Integration
Mar 27, 2024



Generative recommendation has emerged as a promising paradigm aimed at augmenting recommender systems with recent advancements in generative artificial intelligence. This task has been formulated as a sequence-to-sequence generation process, wherein the input sequence encompasses data pertaining to the user's previously interacted items, and the output sequence denotes the generative identifier for the suggested item. However, existing generative recommendation approaches still encounter challenges in (i) effectively integrating user-item collaborative signals and item content information within a unified generative framework, and (ii) executing an efficient alignment between content information and collaborative signals. In this paper, we introduce content-based collaborative generation for recommender systems, denoted as ColaRec. To capture collaborative signals, the generative item identifiers are derived from a pretrained collaborative filtering model, while the user is represented through the aggregation of interacted items' content. Subsequently, the aggregated textual description of items is fed into a language model to encapsulate content information. This integration enables ColaRec to amalgamate collaborative signals and content information within an end-to-end framework. Regarding the alignment, we propose an item indexing task to facilitate the mapping between the content-based semantic space and the interaction-based collaborative space. Additionally, a contrastive loss is introduced to ensure that items with similar collaborative GIDs possess comparable content representations, thereby enhancing alignment. To validate the efficacy of ColaRec, we conduct experiments on three benchmark datasets. Empirical results substantiate the superior performance of ColaRec.
Uncovering Selective State Space Model's Capabilities in Lifelong Sequential Recommendation
Mar 25, 2024



Sequential Recommenders have been widely applied in various online services, aiming to model users' dynamic interests from their sequential interactions. With users increasingly engaging with online platforms, vast amounts of lifelong user behavioral sequences have been generated. However, existing sequential recommender models often struggle to handle such lifelong sequences. The primary challenges stem from computational complexity and the ability to capture long-range dependencies within the sequence. Recently, a state space model featuring a selective mechanism (i.e., Mamba) has emerged. In this work, we investigate the performance of Mamba for lifelong sequential recommendation (i.e., length>=2k). More specifically, we leverage the Mamba block to model lifelong user sequences selectively. We conduct extensive experiments to evaluate the performance of representative sequential recommendation models in the setting of lifelong sequences. Experiments on two real-world datasets demonstrate the superiority of Mamba. We found that RecMamba achieves performance comparable to the representative model while significantly reducing training duration by approximately 70% and memory costs by 80%. Codes and data are available at \url{https://github.com/nancheng58/RecMamba}.